







 谷歌首席科学家JeffDean的演讲揭示了人工智能领域的重大进展,包括TPU的发展、神经网络的精度优化、跨模态技术的突破,以及在AIGC时代,谷歌如何追赶并引领技术潮流。演讲强调了硬件能效提升和跨模态技术对拓宽计算机应用的重要性。
谷歌首席科学家JeffDean的演讲揭示了人工智能领域的重大进展,包括TPU的发展、神经网络的精度优化、跨模态技术的突破,以及在AIGC时代,谷歌如何追赶并引领技术潮流。演讲强调了硬件能效提升和跨模态技术对拓宽计算机应用的重要性。
文章目录
这次我们正在经历的AIGC革命
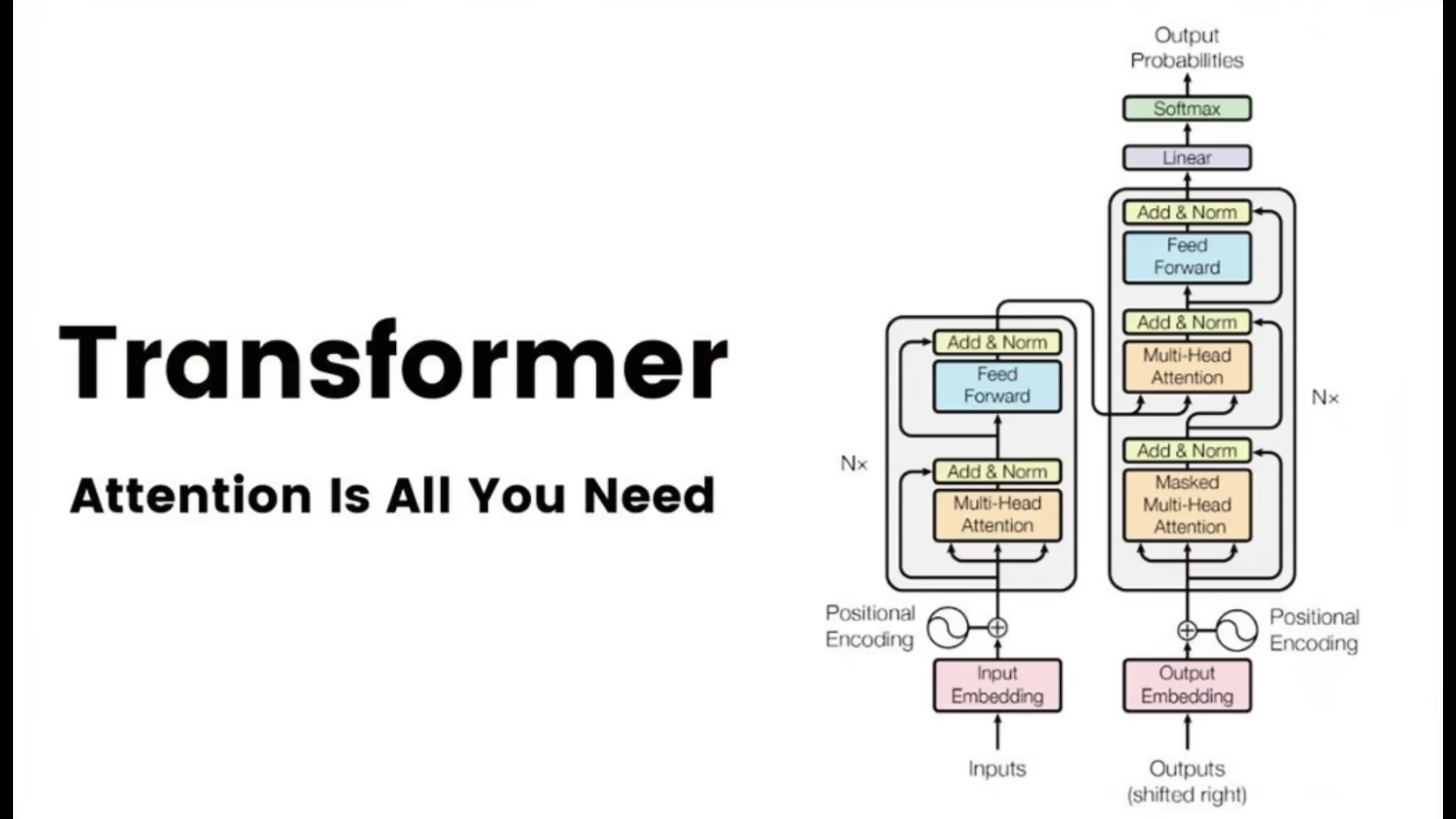
始作俑者应该就是2017年谷歌发表的题为 “Attention is All You Need”的重磅论文
但是现在大家普遍感觉在大模型领域
谷歌一直是在追赶别人
那么为什么现在会出现这种情况呢?
谷歌现在都做了什么工作呢?
为了解答这个问题
谷歌首席科学家Jeff Dean于2月13日
在美国莱斯大学进行了一场1小时12分钟的公开演讲

主要展示人工智能和机器学习领域中几个令人振奋的趋势
并且介绍了谷歌在人工智能时代的过去、现在与未来所做的工作

甚至还概述了Gemini系列模型
虽然它在15日发布的时候
被Sora抢去了风头
但是这个演讲对于我们了解谷歌在AI时代的进展和计划
还是有很大帮助
谁是Jeff Dean
我们先简单介绍一下大神Jeff Dean

他是在1999年加入的谷歌
目前担任谷歌的首席科学家

专注在Google DeepMind和Google Research的人工智能进展方面
他的研究重点包括机器学习和人工智能
以及将人工智能应用于有益于社会的方面

他的工作对谷歌搜索引擎、初期的广告服务系统、分布式计算基础设施
比如BigTable、MapReduce和TensorFlow等等都产生了重要影响
可以说是Google技术的奠基人
关于Jeff Dean的传说很多
甚至很多成了段子,比如说
编译器从来不警告Jeff
而是Jeff警告编译器
以及Jeff的键盘只有两个键,1和0
要找新的硬件解决方案
首先
Jeff Dean认为机器学习真的改变了我们对计算机能力的期望

十年前
语音识别技术还只能称得上“勉强能用”,
计算机对图像并不能做到真正理解
机器还无法深刻理解语言的概念和多语言的数据
而现在
计算机已经能够看到和感知到我们周围的世界
我们目前在计算领域
有点类似于动物突然之间进化出眼睛时的阶段

这是一个完全不同的局面
另一个观察是规模的增长
数据集在不断扩大
不仅更加丰富多元
而且愈发引人关注;
同时
机器学习模型的构建也在不断突破以往的规模

这种规模的增长往往能够带来性能上的显著提升
每当我们将规模进一步扩大
无论是解决问题的能力还是结果的准确性
都会实现一个质的飞跃
这种基于全新机器学习范式的计算需求
与传统的、依赖于人工编写的复杂C++代码大相径庭
为了更有效地执行这类新型计算任务
我们需要寻求不同类型、更为适应的硬件解决方案
跨模态技术突破拓宽计算机应用的可能性
在过去的十年间
我们不仅在计算机视觉、语音识别和自然语言处理技术方面
取得了令人瞩目的进步
更令人惊奇的是
我们还实现了从图像到标签或文本描述的转化
比如能够详细描绘出一张
猎豹站在吉普车顶度假的照片中的场景
甚至还能够逆转这些过程
此外
还出现了从文本描述生成图像甚至视频剪辑的能力
以及基于文本描述合成特定声音片段的技术
这标志着跨模态理解和生成技术的重大突破
这些能力的出现
无疑极大地拓宽了计算机构建和应用的可能性
让我们现在可以创造出更加丰富多元的应用和服务
ImageNet & AlexNet:图像识别技术发展
在这个过程中
斯坦福大学推出的ImageNet基准测试项目
应该说是一个标志性的事件
这个项目涉及从包含大约一百万张彩色图像
及其对应的一千个类别标签的训练数据集中学习
并且要求参赛系统对没有见过的新图像进行准确分类
在2011年首届竞赛中
最佳系统的识别准确率仅为50.9%。
转折点发生在次年
亚历克斯·克里热夫斯基Alex Krizhevsky和杰弗里·辛顿Jeffrey Hinton合作
发表了一篇具有里程碑意义的论文
推出了名为AlexNet的深度神经网络模型
将准确率提高了约13%,
这一突破性成就使得神经网络成为了主流选择
在当时的所有28个参赛作品中
只有他们的团队采用了神经网络技术
这标志着从手动设计特征
转向直接从原始数据中学习模式的转变
达到了手工设计方法难以企及的复杂度
自从那以后
ImageNet挑战赛中的准确率就逐渐从63%跃升至当前的91%,
这个数值甚至超过了人类在此类任务上的平均表现
能做到1000多个类别以及诸如40多个不同犬种这样细微的区分
语音识别技术发展
与此同时
语音识别技术也经历了类似的增长
词错误率(WER)的衡量标准
也就是错误识别单词的百分比
在短短五年内
从13.25%下降到了惊人的2.5%,
意味着原本每六七个词就有一个错误的情况
现在变成了大约四十个词才出现一次错误
极大地提升了语音识别系统的可靠性和可用性
硬件能效不断提升
硬件优化和能效上也在不断提升
从而可以构建出质量更高、规模更大的模型
神经网络的优势-精度要求不苛刻、本质都是线性代数
接下来Jeff Dean重点讲了一下神经网络
它有两个特别的优势
首先,它对计算精度的要求并不苛刻
在很多情况下
可以将模型中的浮点运算精度
从六位数降低到一到两位数
甚至有助于提升模型的学习效果
某些优化算法会特意引入噪声来增强模型的学习能力
而降低精度在某种程度上
类似于向学习过程中添加一定量的噪声
有时候反而能带来更好的训练结果
神经网络精度要求不苛刻、降低精度可能带来好结果
其次
神经网络中的大多数计算和算法
本质上都是线性代数操作的不同组合
例如矩阵乘法和各种向量运算等
如果能够设计出专门用于低精度线性代数运算的计算机硬件
就能够以更低的计算成本和能源消耗
构建出更高质量的模型
谷歌的TPU
为此
谷歌研发了张量处理单元(TPU)
这是一种专门针对低精度线性代数优化的系统架构
最初的TPU V1版本主要用在推理阶段
就是当模型已经训练完成并且应用到实际产品环境的时候
比如识别图像内容或者语音识别
与当时使用的CPU相比
TPU V1在能耗和计算性能方面
实现了30倍到80倍的提升
随后
TPU V2和V3版本不仅提升了单个芯片的性能
还开始关注大规模系统的设计
支持多个芯片协同工作进行模型的训练和推断
其中
TPU V3采用了水冷技术来提高散热效率
而TPU V4则在外形设计上增添了时尚元素
加了一些五颜六色的酷炫电线(纯搞笑)
这块呢Jeff Dean是纯属搞笑了
这三个迭代版本的芯片称为Pod
被设计成为能够组装成更大的系统
第一代Pod的网络结构很简单
但是带宽高
采用了2D网格布局
每个芯片与四个相邻的芯片直接相连
确保了高速、低成本的数据传输
随着技术的进步,Pod的规模不断扩大
第二代扩展到了1024个芯片
分布于八个机柜中;
而更进一步的版本则利用了64个机柜
每个机柜有64个芯片
提供了超过1.1太赫兹的低精度浮点运算能力
共计4096个芯片
最近公开的TPU v5p系列有两种型号
一种用来推理
拥有256个芯片的Pod;
另一种v5p芯片内存更大、芯片间带宽更高、内存带宽更充足
它的16位浮点性能接近半petaflop
并且混合精度性能是其两倍
最大的v5p Pod包含了近9000个芯片
可提供exaflop级别的强大计算能力
语言模型
随后Jeff Dean重点回顾了一下语言模型十五年的历程
这里我们简单过一下
2007 - N-gram
早在2007年,他和谷歌翻译团队合作
构建了一个用于研究竞赛的高质量系统
虽然只能处理少量句子
比如两周内只能翻译大约50句话
但是可以通过查找大约20万条的N-gram
实现高品质的翻译
N-gram是一种基于统计语言模型的算法,用于自然语言处理任务。
它的基本思想是将文本或语音中的连续序列、
按照大小为N的滑动窗口进行分割,形成长度为N的片段序列。每个N-gram代表一个
由N个连续的词或字符组成的序列,其出现的概率是基于给定的语料库统计得到的。N-gram模型假设文本中的下一个词(或字符)出现的概率仅依赖于前面的N个词(或字符),而与其他部分无关。
这种假设简化了语言建模的复杂性,使得模型更容易从数据中学习。
在实际应用中,N-gram模型广泛用于
文本生成、语言建模、机器翻译等领域。例如,
在文本生成任务中,可以根据
已有的文本数据使用N-gram模型生成类似风格和结构的新文本。在语言建模中,
N-gram模型可以用于识别和纠正拼写错误,或者自动完成用户输入的文本。在机器翻译中,
N-gram模型可以用于评估机器翻译结果的质量,例如通过计算翻译结果与参考翻译之间的N-gram匹配度来评估相似度。习惯上,1-gram被称为unigram,2-gram被称为bigram,3-gram被称为trigram,以此类推。
然而,实际应用中,
n>5的N-gram模型较为少见,因为随着N的增大,模型的复杂度和计算成本也会显著增加。总的来说,N-gram是一种
有效的统计语言模型,能够捕捉文本中的序列信息,为自然语言处理任务提供有力的支持。
为了能够让它得到实际应用
Jeff Dean建立了一个给N-gram模型提供服务的系统
统计了超过2万亿个token中
每种五个词序列出现的频率
从而产生了大约3000亿种独特的五词组合
并将它存储在多台计算机的内存中
以便进行并行查询
为了解决数据稀疏问题
他们创新地提出了一种名为“Stupid Backoff”的算法
在找不到匹配N-gram时
会逐步尝试查找前缀
直至找到合适的词汇序列
这个经历让他深刻认识到
大量数据只要结合简单的技术
就可以产生惊人效果
数据自身会揭示答案
2013 - Word2Vec
2013年
Jeff Dean的同事托马斯·米科洛夫Tomas Mikolov开始关注分布式表示的概念
也就是将单词从离散表示
转变为高维向量空间中的连续表示
比如使用百维的向量来表示不同的单词
通过训练他们发现
如果让相似语境下的词向量相互接近、不相似的远离
那么就能够在高维空间中发现优秀的特征结构
比如山、小山丘和悬崖这些类似概念的词
都会相邻
同时在高维空间中的方向也具有意义
比如国王与女王之间的向量差值方向
大致也反映了男性与女性的一般区别
在这个基础上,Word2Vec模型诞生了
2014 - Sequence-To-Sequence
2014年,Jeff Dean当时的同事
伊利亚·苏茨克维尔Ilya Sutskever、奥里奥尔·维尼亚尔斯Oriol Vinyals
开发了一个被称为“Sequence to Sequence”的模型
利用了神经网络
通过长短时记忆网络
能够准确地从英语句子翻译成法语句子
长短时记忆网络(Long Short-Term Memory,LSTM)是循环神经网络(RNNs)的一种特殊类型,旨在解决传统RNN存在的长期依赖问题。
传统的RNN在处理长序列数据时,由于
梯度消失或梯度爆炸等问题,使得模型在训练过程中不稳定或无法有效学习。而LSTM通过
特殊的网络结构设计,可以捕捉长序列之间的语义关联,有效缓解这些问题。LSTM的整体结构与RNN基本相同,都是由
多个cell串联起来,包括双向LSTM和深层LSTM。但它们的区别在于
单层的前向传播网络模块,LSTM的单一重复模块具有更复杂的结构,包含4个网络层,以一种特殊的方式进行交互。LSTM的核心结构可以分为四个部分:
遗忘门、输入门、细胞状态和输出门。
遗忘门负责决定从细胞状态中丢弃哪些信息;
输入门决定哪些新的信息将被存储在细胞状态中;
细胞状态则保存和更新长期记忆;最后,输出门基于
细胞状态来决定输出什么值。这种设计使得LSTM具有更好的性能,尤其是在处理
具有长期依赖关系的序列数据时。因此,LSTM在语音识别、图片描述、自然语言处理等许多领域得到了广泛的应用。
然而,由于其结构复杂,理解和训练LSTM模型需要一定的专业知识。
总的来说,
长短时记忆网络是一种高效的循环神经网络,通过其特殊的网络结构设计,可以有效地处理具有长期依赖关系的序列数据,
从而在各种应用中取得优秀的性能。
一年后
进一步发表了一篇研讨会论文
展示了如何在多回合对话中运用上下文信息
借助Sequence to Sequence模型
机器开始可以基于之前多个互动回合的上下文
来生成恰当回复
2017 - Transformer
2017年
谷歌的其他研究人员与一名实习生共同提出了“Transformer”模型
这个创新在于摒弃了传统递归模型的顺序依赖性
转而采用并行处理输入中的所有单词
并通过注意力机制:聚焦于文本的不同部分
而非强制单个状态按照顺序处理每一个单词
这不仅大大提升了计算效率
而且在相同计算资源条件下
把翻译准确性提高了10到100倍
随着硬件性能的不断提升和此类算法的不断改进
人们开始广泛采用Transformer模型来替代递归模型
不仅用于翻译任务
还应用于对话式数据的训练
取得了相当优异的结果
2020 - LLM
2020年开始
大模型进入了百花齐放的时代
神经语言模型和神经对话模型日趋成熟
比如Meena、OpenAI的GPT系列
以及谷歌去年发布的Bard等
在这个基础上
出现了基于Transformer架构的大型语言模型项目
比如GPT-3/GPT-4,谷歌的PaLM
DeepMind的Chinchilla
谷歌的PaLM 2以及由Jeff Dean和奥里奥尔共同领导的Gemini项目
在去年启动Gemini项目的时候
谷歌的目标是训练全球最佳的多模态模型
并在谷歌内部广泛应用
Gemini项目从一开始
就以实现真正的多模态处理为核心目标
除了文本信息以为
还致力于整合图像、视频以及音频等多种数据类型
首先,他们将这些不同模态的数据
转换成一系列的token
并基于这些token来训练Transformer架构的模型
这个模型具有多个解码路径
一条路径用于学习生成的文本token
另一条则是通过初始化解码器的状态
利用Transformer学到的知识
从该状态生成完整的图像像素集合
值得一提的是
Gemini支持交错式输入序列
比如在处理视频时
可以交替输入视频帧和描述帧内容的文本
或者是将音频字幕嵌入到文本中
这使得Transformer能够跨多种模态
来构建共享的语义表示
Gemini V1版本提供了三种不同的规模选择
其中
V1 Ultra是规模最大且功能最强大的模型;
V1 Pro则适合数据中心部署
适用于各种产品环境;
而V1 Nano模型专为移动设备优化
能在手机或笔记本电脑上高效运行
进行量化处理后体积更小
适应性更强
而最新发布的Gemini 1.5 Pro
支持高达100万token的超长上下文
主打多任务处理
谷歌计算资源
为了实现高度可扩展且灵活的架构设计
谷歌采用了Pods的方式来组织计算资源
由系统智能决定各个部分的最佳放置位置
以及芯片间的通信方式
依据高速网络拓扑结构确保高效的数据传输
这样
研究人员和开发者无需关心底层细节
只需关注模型性能特征差异即可
在故障管理方面
谷歌会尽量减少人为操作引起的故障
并优化了修复与升级流程,比方说
在涉及大规模并行计算时
会选择同时关闭所有相关机器进行内核升级
而不是逐个更新
从而导致持续的故障
在训练数据方面
为了打造一个多模态的模型
谷歌采用了大量多元化的数据集
包括网络文档各类书籍
不同编程语言的代码
以及图像音频和视频数据
同时运用了一系列启发式的方法
来过滤数据
并且结合基于模型的分类技术
来筛选高质量的内容
结果发现
数据的质量极为关键
高质量的数据对模型在任务上的表现有着显著的影响
有时候
甚至比模型的架构本身更为重要
OpenAI研究院
接下来呢
Jeff Dean谈到了OpenAI研究院
Jason Wei提出的思维链Chain-of-Thought技术
这种技术呢
就好像我们上小学时候
老师教我们数学时一样
一步一步地展示解题的步骤
从而将复杂的问题
拆解为更容易处理的小步骤
在解答数学问题方面
思维链的应用呢
可以让大模型的准确率有大幅的提升
随后Jeff Dean借着这个话题
又聊了一下Gemini的多模态的推理能力
也炫了一下Gemini的评估结果
AIGC
接下来呢
Jeff Dean还聊了一些
有关于AIGC方面的一些进展
包括图像生成的工作原理
大模型在智能手机上的应用
以及通用模型将转化为领域专用模型的趋势看法
总结
总的来说
Jeff Dean认为
现在是计算机领域极为振奋人心的时代
我们已经具备了以非常自然的方式
与计算机系统进行交谈的能力
他们能够理解我们的言语表达
并且能够根据需求
以自然的声音做出回应
或者是生成精美的图像
这一切都让人感到无比激动
不过
巨大的机遇面前也伴随着巨大的责任
如何确保AI对社会是有益的
真正为世界带来积极的影响
是我们需要继续深思并且付诸实践的问题















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









