








最近正在看一本有关医疗图像处理技术的书籍,里面有一整个章节在讲解各种医疗图像分割技术,
与我之前写的两篇文章相比,细分到了医疗领域,医疗图像与其他领域相比,虽万变不离其宗,
但仍有独特之处,所以想针对医疗领域图像分割再写一个系列的文章,希望对从事医疗算法的同行有所帮助,
本系列文章分为如下四部分:
**医疗图像分割概述和基本理论**
基于模糊聚类的医疗图像分割
基于可形变模型的医疗图像分割
基于神经网络的医疗图像分割
本篇文章主要讲解医疗图像分割概述和基本理论
1概述
2基于阈值的分割
2.1全局阈值
2.2局部阈值
2.3图像预处理
3区域增长
4分水岭
5基于边缘的图像分割
6多谱图像分割
6.1多模态
6.2多时域
1概述:
图像分割就是从背景中分离出感兴趣区域,在医疗领域,图像分割可以用来描绘解剖结构和组织类别,例如器官分割,病灶分割等,还可以用于可视化和图像压缩,是图像处理中非常重要的一个领域。
图像分割基本上可以通过两种方式实现,一种是识别出感兴趣区域内所有的像素,另一种先识别出感兴趣区域的边界来进行分割,第一种方法主要依赖于像素的灰度值,但像素的其他属性,例如纹理等也会被应用于图像分割,基于边界的分割方法主要依赖于图像的梯度。
2基于阈值的分割:
有多种基于阈值的图像分割技术,有一部分是基于图像直方图,例如,基于整幅图像的直方图选择一个阈值,
这种方式叫做全局阈值分割;其他的则是基于图像局部属性,例如局部均值和方差,
或者是局部梯度,这种方式叫做局部阈值分割。
2.1全局阈值:
全局阈值假设图像的直方图满足双峰形状:
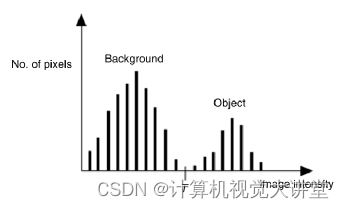
这样选取一个阈值就能将图像一分为二,例如,我们选取阈值T,则分割的结果为:
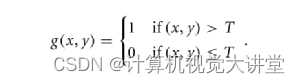
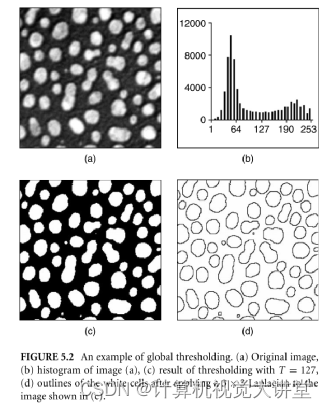
下面是一个全局阈值分割的例子:
除了根据直方图选取分割阈值外,还有许多计算分割阈值的方法,其中一个是基于能够让错分概率最小化的分类模型,下面这篇论文讲述基于该方法实现MR脑部分割:
MR quantification of cerebral ventricular volume using a semiautomated algorithm
他的缺点也很明显,它需要目标与背景有很好的对比度,如果对比度低,或者图像有噪声则效果不理想,现实中很少有图像直方图满足严格的双峰形状。
2.2局部阈值:
当全局阈值不适用时,可以考虑使用局部阈值,局部阈值可以通过如下步骤获得:
1.将整幅图像划分为多个小图像,然后分别计算每个小图像的阈值
2.最简单的可以将所有小图像阈值的均值作为整幅图像的分割阈值
2.3图像预处理:
如果图像对比度低,边界模糊,可以通过图像预处理技术来改善图像直方图,例如中值滤波,如下图所示,图像经中值滤波后直方图出现双峰形状,除了中值滤波还有其他方法,这里就不再一一赘述了。
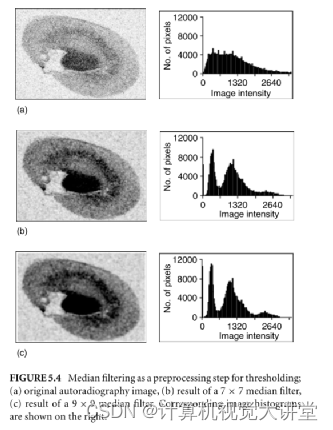
在Opencv中实现了基本的基于阈值的图像分割技术。
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace cv;
using std::cout;
/// Global variables
int threshold_value = 0;
int threshold_type = 3;
int const max_value = 255;
int const max_type = 4;
int const max_binary_value = 255;
Mat src, src_gray, dst;
const char* window_name = "Threshold Demo";
const char* trackbar_type = "Type: \n 0: Binary \n 1: Binary Inverted \n 2: Truncate \n 3: To Zero \n 4: To Zero Inverted";
const char* trackbar_value = "Value";
//![Threshold_Demo]
/**
* @function Threshold_Demo
*/
static void Threshold_Demo( int, void* )
{
/* 0: Binary
1: Binary Inverted
2: Threshold Truncated
3: Threshold to Zero
4: Threshold to Zero Inverted
*/
threshold( src_gray, dst, threshold_value, max_binary_value, cv::THRESH_TRIANGLE );
imshow( window_name, dst );
}
//![Threshold_Demo]
/**
* @function main
*/
int main( int argc, char** argv )
{
//! [load]
String imageName("D:\\basketball2.png"); // by default
if (argc > 1)
{
imageName = argv[1];
}
src = imread( samples::findFile( imageName ), IMREAD_COLOR ); // Load an image
if (src.empty())
{
cout << "Cannot read the image: " << imageName << std::endl;
return -1;
}
cvtColor( src, src_gray, COLOR_BGR2GRAY ); // Convert the image to Gray
//cvtColor( src, src_gray, COLOR_BGR2HSV); // Convert the image to Gray
//! [load]
//! [window]
namedWindow( window_name, WINDOW_AUTOSIZE ); // Create a window to display results
//! [window]
//! [trackbar]
createTrackbar( trackbar_type,
window_name, &threshold_type,
max_type, Threshold_Demo ); // Create a Trackbar to choose type of Threshold
createTrackbar( trackbar_value,
window_name, &threshold_value,
max_value, Threshold_Demo ); // Create a Trackbar to choose Threshold value
//! [trackbar]
Threshold_Demo( 0, 0 ); // Call the function to initialize
/// Wait until the user finishes the program
waitKey();
return 0;
}
3区域增长
区域增长也叫区域融合,就是寻找具有相同灰度值的像素组,需要手动或者自动设置一个种子点,然后不断地检查周边像素,如果周边像素与种子点相似,则将该像素吸纳进来,整个搜索过程不断地进行直到找不到相似像素为止,这个过程中相似性度量非常重要,可以对比像素点的灰度值,也可以对比以像素点为中心的一块区域内的均值。

在opencv中已经实现了对区域增长的封装。
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include <iostream>
#include "math.h"
using namespace cv;
using namespace std;
Point recent_Point, recent_Point1;
Mat RegionGrow(Mat src, Point2i pt, int th)
{
Point2i ptGrowing; //待生长点位置
int nGrowLable = 0; //标记是否生长过
int nSrcValue = 0; //生长起点灰度值
int nCurValue = 0; //当前生长点灰度值
Mat matDst = Mat::zeros(src.size(), CV_8UC1); //创建一个空白区域,填充为黑色
//生长方向顺序数据
int DIR[8][2] = {
{
-1, -1 }, {
0, -1 }, {
1, -1 }, {
1, 0 }, {
1, 1 }, {
0, 1 }, {
-1, 1 }, {
-1, 0 } };
vector<Point2i> vcGrowPt; //生长点栈
vcGrowPt.push_back(pt); //将生长点压入栈中
matDst.at<uchar> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5201
5201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









