








R-CNN论文学习笔记
【1】R-CNN介绍
传统的目标检测方法一般采用复杂的系统,将多个低级图像特征与高级语境相结合,其性能在近几年稳定下来,没有明显提高。R-CNN的提出,使目标检测性能相对于2012年的先前最佳结果,平均精度(mAP)提高了30%以上,达到53.3%的mAP。
R-CNN包含两个关键的改进:(1)将卷积神经网络(CNN)应用于自下而上的候选区域,将提取的特征用于定位和分割对象。(2)在训练数据稀缺时,利用迁移学习,对网络进行预训练,然后在特定数据上进行微调(fine tuning),从而显著提升性能。由于我们将候选区域与CNN相结合,所以作者将论文中的方法称为R-CNN:具有CNN特征的区域。
【2】R-CNN的模块设计
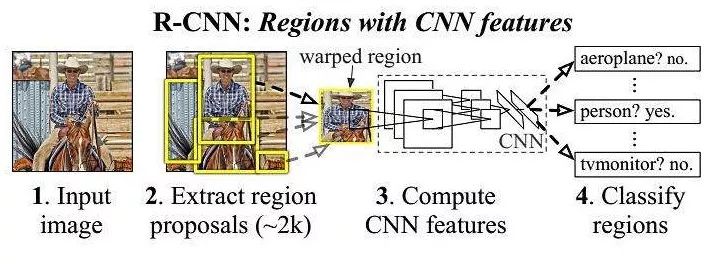
1、提取候选区域。目标检测领域相关论文提出多种提区候选区域的算法,包括:对象性方法(objectness),选择性搜索(selective search),类别无关对象建议(category-independent object proposals),约束参数最小化(CPMC),多尺度组合分组(multi-scale combinatorial grouping)等等。为了便于与先前检测工作经行对比,论文中采用选择性搜索(selective search)算法。由于本文主要关注R-CNN网络本身的设计,因此对提区候选区域具体算法就不在赘述,留给后续文章介绍。
2、特征提取。利用AlexNet网络对每个候选区域提取4096维特征向量(第7层的输出)。首先将候选区域转化为227×227分辨率的RGB图像,以便于可以作为CNN的输入。然后图像通过五个卷积层和两个全连接层向前传播来提取特征。关于AlexNet网络的细节,请访问:AlexNet论文笔记
3、SVM分类器和边框回归。对每个类别训练一个线性SVM分类器,用于对候选区域的4096维特征向量进行分类。针对每个类别,在得到分类评分之后,利用非极大值抑制(NMS)方法去除重叠度较高的一些候选区域。最后利用边框回归(bounding box regression)对最后的结果进行进行精细化处理,使得检测结果边框更准确。有关非极大值抑制(NMS)算法的详细介绍,留给后续文章介绍。
【3】测试与训练
测试过程根据R-CNN的模块设计,按顺序执行。首先对图像进行选择性搜索,得到大约2000个候选区域。然后对每个候选区域进行缩放,作为CNN网络的输入,得到特征向量。最后对特征向量进行分类和边框回归,得到最终结果。训练过程是分阶段的,CNN与SVM分别单独进行训练。
1、训练CNN网络。作者先将完整的AlexNet在ImageNet上进行预训练, 得到一个分类模型。为了使网络适应新任务(检测),将网络的最后一层修改为N + 1维向量(N表示类别数,1表示背景),替换原来的1000维向量(AlexNet原有类别),并将最后一层参数初始化伪随机数,其他层的参数为预训练得到的值。
将所有候选区域与检测框真值之间IoU ≥0.5的区域作为正样本(某一类别),其余的作为负样本(背景)。如果某个候选区域不是背景,则选择与之IOU最大的那个检测框真值的类别作为此候选区域的类别。以0.001(初始学习率的1/10)的学习率开始SGD,这样可以在不破坏初始化的情况下进行微调。在每个SGD迭代中,统一采样32个正样本(所有类别)和96个负样本,以构建大小为128的小批量。
2、训练SVM分类器。为每个类别构建一个SVM分类器。以检测框真值作为正样本,以候选区域与检测框真值之间IoU <0.3的区域作为负样本,其余候选区域直接抛弃掉,不作为训练数据。以CNN网络提取的4096维特征作为SVM分类器训练数据的特征向量。
3、训练边框回归。训练边框回归时,使用数据 ( P i , G i ) , i = 1 , 2 , … , N (P^i,G^i),i=1,2,\dots,N (Pi,Gi),i=1,2,…,N作为训练数据,其中 P i = ( P x i , P y i , P w i , P h i ) P^i=(P^i_x,P^i_y,P^i_w,P^i_h) Pi=(Pxi,Pyi,Pwi,Phi)表示候选区域像素的中心坐标以及宽度和高度, G i = ( G x i , G y i , G w i , G h i ) G^i=(G^i_x,G^i_y,G^i_w,G^i_h) Gi=(Gxi,Gyi,Gwi,Ghi)是检测框真值的对应表示。N是训练数据样本数量。边框回归的目标是学习一个转换,将候选区域P映射到检测框真值G,具体用四个函数 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P), d_y(P), d_w(P), d_h(P) dx(P),dy(P),dw(P),dh(P)来表示这个转换。在学习得到这些函数后,应用下面的转换公式,可以将输入的候选区域P转换成预测的检测框真值G^:
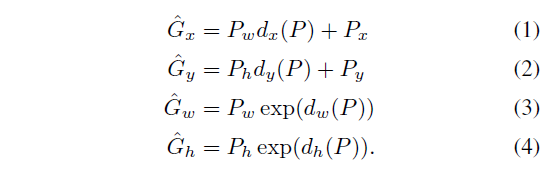
每个函数
d
⋆
(
P
)
d_⋆(P)
d⋆(P)(⋆表示x,y,w,h中的一个)都建模为候选区域在CNN网络Pool5层的特征(记为)的线性函数。即
d
⋆
(
P
)
=
W
⋆
T
ϕ
5
(
P
)
d_⋆(P)=W^T_⋆\phi_5(P)
d⋆(P)=W⋆Tϕ5(P)
其中W⋆表示模型和训练参数的一个向量,通过优化正则化最小二乘法的目标(脊回归)来学习W⋆

训练数据对 ( P , G ) (P,G) (P,G)的回归目标 t ⋆ t_⋆ t⋆定义为
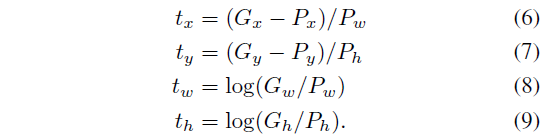
作为标准正则化最小二乘问题,可以有效的找到封闭解。
在实现边框回归的过程中有两个需要注意的问题。第一是正则化是重要的:作者基于验证集,设置λ=1000。第二个问题是,选择使用哪些训练对时,如果P远离所有的检测框真值,那么将P转换为检测框真值G的任务就没有意义。只有当候选区域P至少在一个检测框真值附近时,才参与学习任务。即,将P分配给具有最大IoU的检测框真值G(在重叠多于一个的情况下),并且仅当重叠大于阈值(基于验证集,作者使用的阈值为0.6)。丢弃其他不满足的候选区域。每个类别分别学习一个边框回归,以便学习一组特定于类别的检测框回归器。















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









