






EML定义
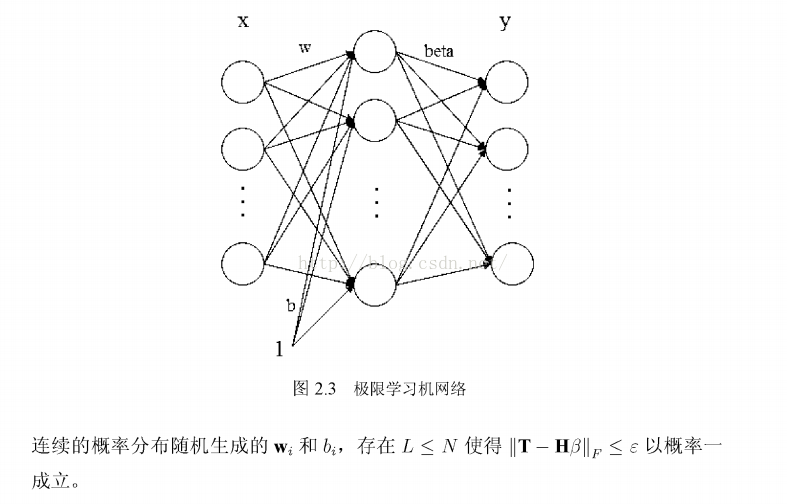
极限学习机器( Extreme Learning Machine,ELM) 是神经网络研究中的一种算法,是一种泛化的单隐层前馈神经网络( Single-hidden Layer Feed forward Network,SLFN)。
SLFN:单隐层前馈神经网络
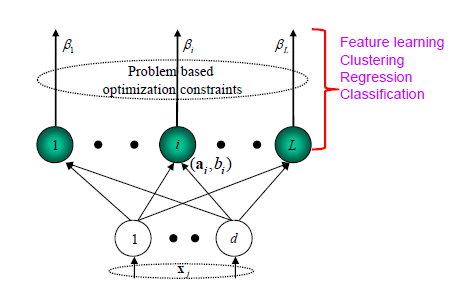
以SLFN为例,传统的神经网络训练方法:
1.初始化参数(输入层到隐层的权重与偏置,隐层到输出层的权重与偏置),
2.计算输出层误差并反向传播,迭代直至误差满足要求。
BP算法利用迭代,将误差逐步降低,然而迭代率过低则训练速度慢,过高则无法收敛,导致需要不断调参。
在ELM模型理论中,提出的问题是,这些权重真的需要进行不断地迭进行求解吗?
黄广斌教授给出了一个新的思路:从输入层到隐层的权重根本不需要进行迭代优化,随机赋值即可。并在论文中给出了严格的数学证明。
EML算法原理
输入权值和隐层阈值进行随机赋值,输出层权值则通过最小二乘法直接计算。整个学习过程一次完成,无需迭代,因而能达到极快的学习速度。
两个重要理论:





n x(L+1) +Lx(m+1)个值,且反向传播算法为了保证系统的稳定性通常选取较小的学习率,使得学习时间大大加长。因此极限学习机在这一方法优势非常巨大,在实验中 ,极限学习机往往在数秒内就完成了运算。而一些比较经典的算法在训练一个单隐藏层神经网络的时候即使是很小的应用也要花费大量的时间,似乎这些算法存在着一个无法逾越的虚拟速度壁垒。
(2)在大多数的应用中,极限学习机的泛化能力大于类似于误差反向传播算法这类的基于梯度的算法。
( 3 ) 传统的基于梯度的算法需要面对诸如局部最小,合适的学习率、过拟合等问题 ,而极限学习机一步到位直接构建起单隐藏层反馈神经网络,避免了这些难以处理的棘手问题。
极限学习机由于这些优势,广大研究人员对极限学习机报以极大的兴趣,使得这几年极限学习机的理论发展很快,应用也在不断地拓宽。
小结
本文主要对极限学习机的本质原理和来龙去脉作了详尽的介绍,阐明极限学习机所具有的各种各样优势吸引广大学者进行研究。然而极限学习机也有自己的劣势,接下来我们将对极限学习机的劣势进行分析和研究并加以改进。
EML算法实战
%% I. 清空环境变量
clear all
clc
%% II. 训练集/测试集产生
%%
% 1. 导入数据
load iris_data.mat
%%
% 2. 随机产生训练集和测试集
P_train = [];
T_train = [];
P_test = [];
T_test = [];
for i = 1:3
temp_input = features((i-1)*50+1:i*50,:);
temp_output = classes((i-1)*50+1:i*50,:);
n = randperm(50);
% 训练集――120个样本
P_train = [P_train temp_input(n(1:40),:)'];
T_train = [T_train temp_output(n(1:40),:)'];
% 测试集――30个样本
P_test = [P_test temp_input(n(41:50),:)'];
T_test = [T_test temp_output(n(41:50),:)'];
end
%% III. ELM创建/训练
[IW,B,LW,TF,TYPE] = elmtrain(P_train,T_train,20,'sig',1);
%% IV. ELM仿真测试
T_sim_1 = elmpredict(P_train,IW,B,LW,TF,TYPE);
T_sim_2 = elmpredict(P_test,IW,B,LW,TF,TYPE);
%% V. 结果对比
result_1 = [T_train' T_sim_1'];
result_2 = [T_test' T_sim_2'];
%%
% 1. 训练集正确率
k1 = length(find(T_train == T_sim_1));
n1 = length(T_train);
Accuracy_1 = k1 / n1 * 100;
disp(['训练集正确率Accuracy = ' num2str(Accuracy_1) '%(' num2str(k1) '/' num2str(n1) ')'])
%%
% 2. 测试集正确率
k2 = length(find(T_test == T_sim_2));
n2 = length(T_test);
Accuracy_2 = k2 / n2 * 100;
disp(['测试集正确率Accuracy = ' num2str(Accuracy_2) '%(' num2str(k2) '/' num2str(n2) ')'])
%% VI. 绘图
figure(2)
plot(1:30,T_test,'bo',1:30,T_sim_2,'r-*')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'测试集预测结果对比(ELM)';['(正确率Accuracy = ' num2str(Accuracy_2) '%)' ]};
title(string)
legend('真实值','ELM预测值')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









