









3D mesh重建003-DO 2D GANS KNOW 3D SHAPE?
0 摘要
众所周知,GAN在图像的生成领域取得了前所唯有的辉煌成就,当然目前的扩散模型大有取代的趋势。但是如何从图像中挖掘3D的知识,依然是探索的比较少的领域,这篇论文就是尝试做了这么一项工作。
架构的核心是一个迭代策略,它探索和利用了GAN图像流形中的不同视角和照明变化。该框架不需要二维关键点或三维标注,或对物体形状的强假设(例如,形状是对称的),但它成功地恢复了对人脸、汽车、建筑等的高精度的三维形状。恢复的三维形状立即允许高质量的图像编辑,如打光和对象旋转。
正常关于对称这个假设,简化计算也约束了表现力。作者强调了在编辑的时候也有不错效果,因为是解耦操作,所以不同属性可以单独操作。
之所以看这篇论文刚好是最近整理相关的论文textured 3d gan和convmesh等用GAN来生成3d的论文。

1 论文整体结构
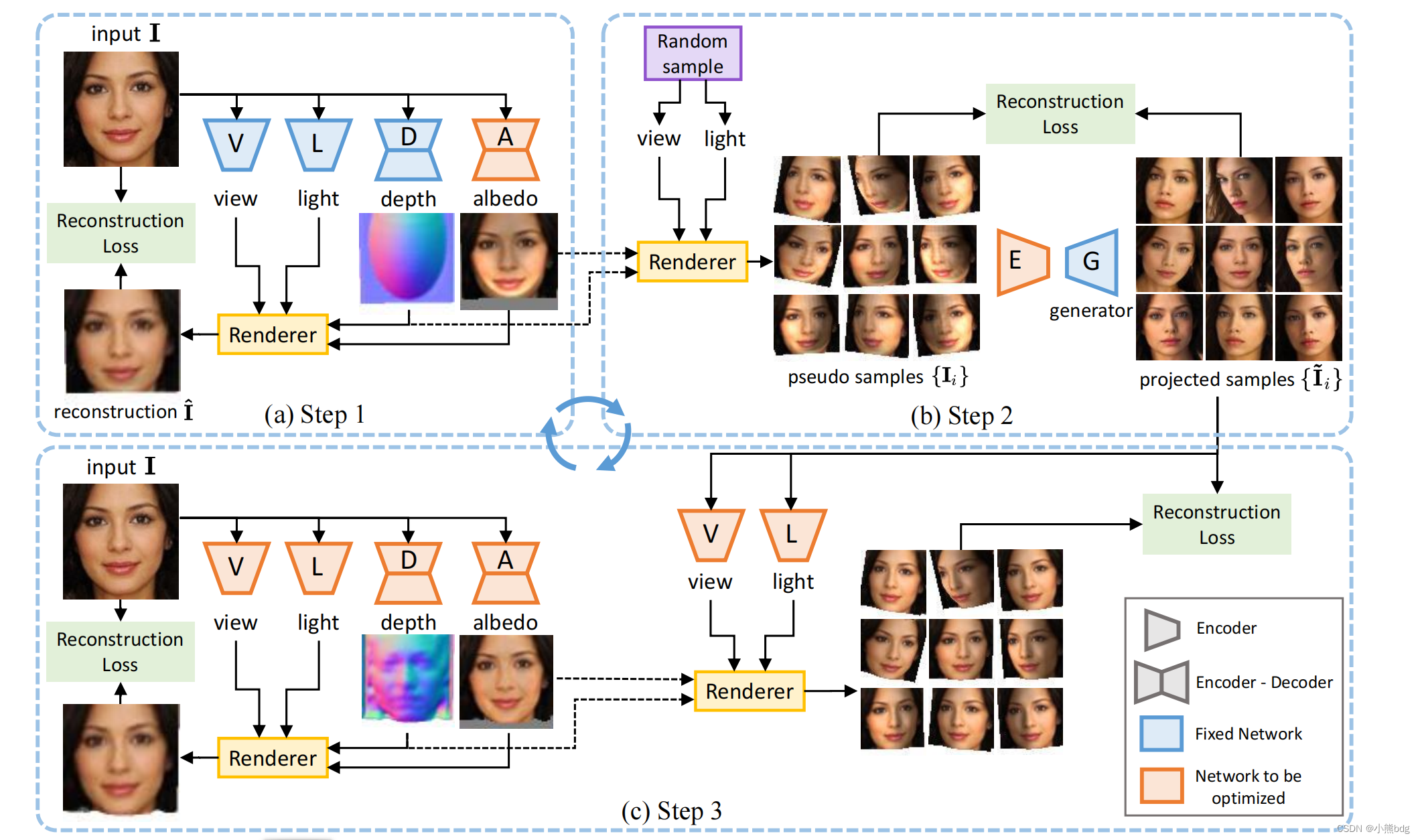
论文的整体结构如下图所示
论文
代码
给定一个由GAN生成的图像,我们使用一个椭球体作为其初始的三维对象形状,并呈现一些不自然的图像,称为“伪样本”,具有各种随机采样的视点和d照明条件如图上所示。通过利用GAN对其进行重建,这些伪样本可以引导原始图像进入GAN 图像流中的采样视点和光照条件,产生了许多自然外观的图像,被称为“投影样本”。这些投影样本可以作为可微渲染过程的地面真相来细化三维形状(即一个椭球体)。为了获得更精确的结果,我们进一步将细化后的形状视为初始形状,并重复上述步骤,逐步细化的三维形状。
依旧是以可微分渲染为桥梁,用4个encoder学习四个属性,把四个属性VLDA输入进去产生渲染视图,在第一步只学习A的编码器。第二步就是训练GAN-INV的那个E编码器,该部分会在章节2中介绍,简单说就是一个latent code z通过G生成图像I,我们训练编码器E能根据图像恢复出原来的z;第三步在调整之后用多个渲染采样视角和G出来的视角做比较,优化调整四个编码器。
2 相关细节
关于思想上继承了styleGAN2的思想在生成器中使用两个编码器,经过两次编码才变成图像。
step1中没有太多额外的补充,基本上就是四个编码器提供四个属性到渲染器里面。
step2步骤简单补充一下GAN-inverson。下图来自In-Domain GAN Inversion
for Real Image Editing主要使用GAN-inv进行图像的编辑,基本思想就是把z到图像的过程反转一下,得到z,然后尝试对z做部分修改实现图片空间上一些语义的修改。
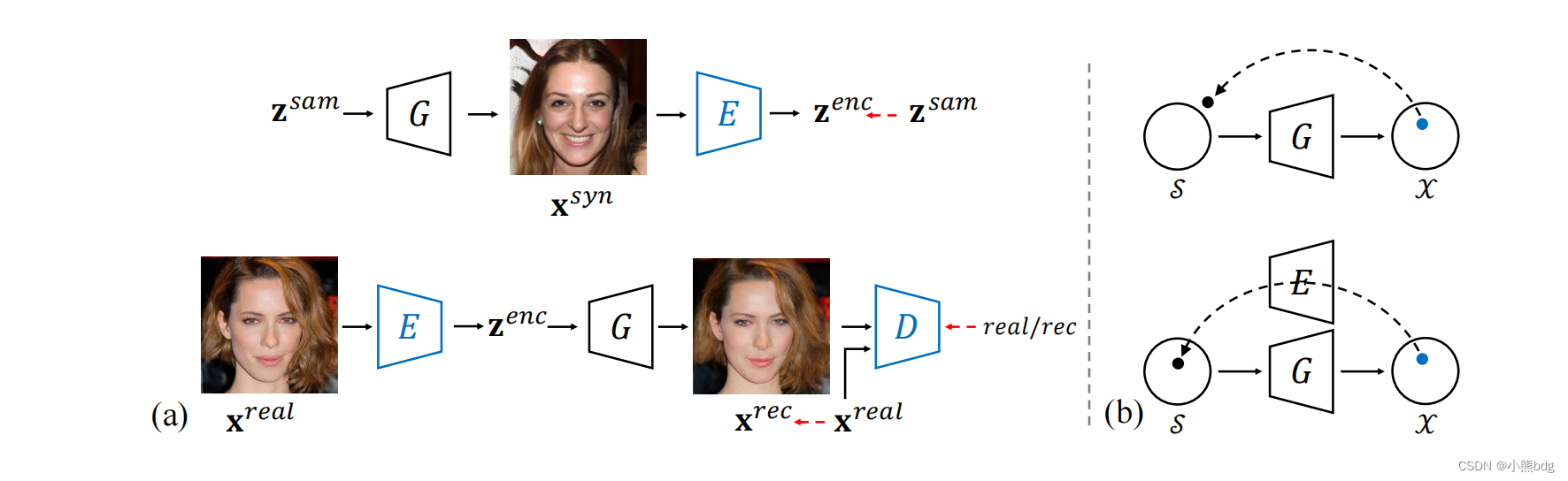 具体优化方式如下,前面提到的生成器的两个编码器G和E,通过计算图像之间的L1距离进行,后面的正则项应该是为了防止
w
w
w过大,造成图像失真等情况。
具体优化方式如下,前面提到的生成器的两个编码器G和E,通过计算图像之间的L1距离进行,后面的正则项应该是为了防止
w
w
w过大,造成图像失真等情况。
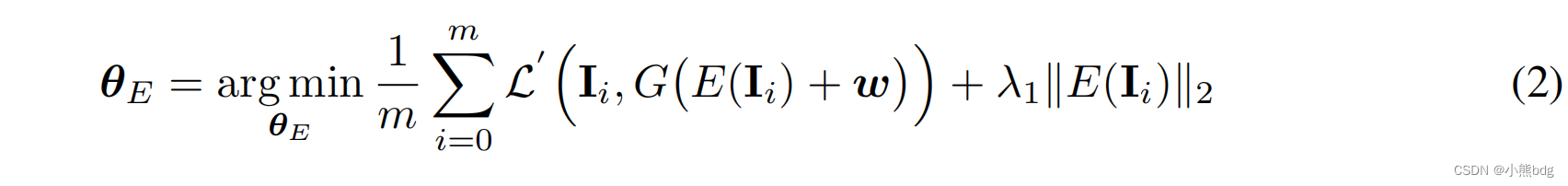
step3主要补充的优化方式,主要包括step1的i和step3的
I
i
I_i
Ii,并不使用step2中的图像。
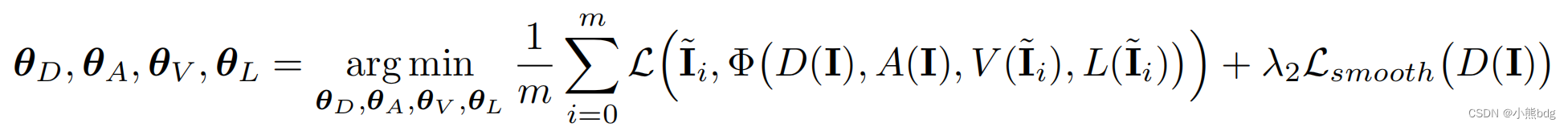
论文有提到一个点就是说实际上训练不仅可以在一个目标上进行也可以在多个目标上进行,而且还能提升归纳偏差和泛化能力。
3 实验
这是2020年论文,现在只展示论文中的实验结果,不评价效果。
















 4479
4479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









