







文章目录
分析目的
“你幸福吗”,“我姓福”。努力的意义究其根本就是为了获取幸福感,让自己愉悦。当阴雨连绵之后的太阳你会觉得幸福,拿到第一份工资会觉得幸福,与幸福感相关的因素成千上万、因人而异,每个人对幸福感都有自己的衡量标准,影响幸福感的因素主要会是什么呢,什么样的人幸福感更强呢?是否能预测出每个人的幸福值呢?
一、数据采集
1、 数据来源
数据来自于阿里云天池,下载链接:一起挖掘幸福感
2、 数据说明
考虑到变量个数较多,部分变量间关系复杂,数据分为完整版和精简版两类。可从精简版入手熟悉赛题后,使用完整版挖掘更多信息。complete文件为变量完整版数据,abbr文件为变量精简版数据。
index文件中包含每个变量对应的问卷题目,以及变量取值的含义。
survey文件是数据源的原版问卷,作为补充以方便理解问题背景。
二、数据传输
将数据导入到PYTHON软件:
train = pd.read_csv('D:\A\幸福感\happiness_train_complete.csv',encoding='ISO-8859-1')
test = pd.read_csv('D:\A\幸福感\happiness_test_complete.csv',encoding='ISO-8859-1')
test_sub=pd.read_csv('D:\A\幸福感\happiness_submit.csv',encoding='ISO-8859-1')三、数据处理
1、查看数据
#查看数据有多少行,多少列
print(train.shape, test.shape)输出结果:(8000, 140) (2968, 139),即训练集8000行,140列,测试集2968行,139列。
2、缺失值处理
#查看缺失值
train.info(verbose=True,null_counts=True)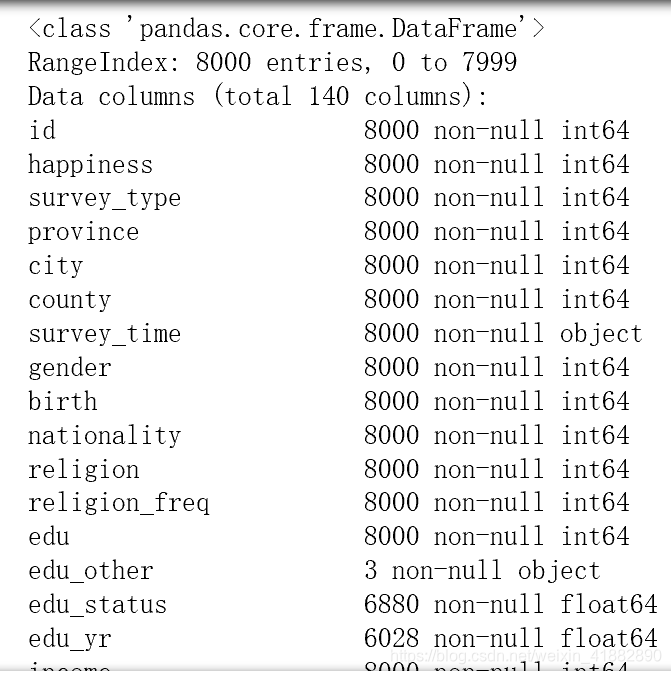
根据结果,一共有8000行数据,其中float型数据25个, int型111个, object型4个。在这些数值型数据中,有很多是实际上是分类数据,原数据集通过对其编码变成了数值型数据。对于分类型数据,将进行One-hot编码后再分析。
family_income有1条数据缺失。
而work_status,work_type, work_manage,work_yr列的数据缺失非常大。缺失较大的进行删除操作,少量缺失则用频繁出现数填充。
#列名class为Python保留字,要改名,不然在操作中很可能报错
train.rename(columns={
'class': 'Class'}, inplace=True)
#列nationality为-8的值,将其替换为8表示其他。
train['nationality'] =train.nationality.replace(-8, 8)
#列religion和religion_freq为-8的值,将其替换为最频繁出现的值1。
train['religion'] = train.religion.replace(-8, 1)
train['religion_freq'] =train.religion_freq.replace(-8, 1)
#列religion和religion_freq为-8的值,将其替换为最频繁出现的值1。
train['religion'] = train.religion.replace(-8, 1)
train['religion_freq'] = train.religion_freq.replace(-8, 1)
#将income列为-1,-2,-3的值,先替换为空值,再用平均值替换
train['income'] = train.income.replace([-1, -2, -3], np.nan)
train['income'] =train.income.replace(np.nan, train['income'].mean())
#列nationality为-8的值,将其替换为最频繁出现的值1。
train['political'] = train.political.replace(-8, 1)
#列health,health_problem为-8的值,将其替换为3,表示一般。
train['health'] =train.health.replace(-8, 3)
train['health_problem'] = train.health_problem.replace(-8, 3)
#列depression为-8的值,将其替换为3,表示一般。
train['depression'] = train.depression.replace(-8, 3)
#列socialize,relax,learn为-8的值,将其替换为3,表示有时。
train['socialize'] = train.socialize.replace(-8, 3)
train['relax'] =train.relax.replace(-8, 3)
train['learn'] = train.learn.replace(-8, 3)
#列equity为-8的值,将其替换为3,表示中间态度。
train['equity'] = train.equity.replace(-8, 3)
#列class为-8的值,将其替换为最频繁出现的5。
train['Class'] = train.Class.replace(-8, 5)
#将family_income列为-1,-2,-3的值,先替换为空值,再用平均值替换
train['family_income'] = train.family_income.replace([-1, -2, -3], np.nan)
train['family_income'] = train.family_income.replace(np.nan, train['family_income'].mean())
#将family_m列为-1,-2,-3的值,替换为1
train['family_m'] = train.family_m.replace([-1, -2, -3], 1)
#列family_status为-8的值,将其替换为3,表示平均水平
train['family_status'] = train.family_status.replace(-8, 3)
#将house列为-1,-2,-3的值,替换为0
train['house'] = train.house.replace([-1, -2, -3], 0)
#将car列为-8的值,替换为最频繁出现的2
train['car'] = train.car.replace(-8, 2)
#将status_peer,status_3_before,view列为-8的值,替换为差不多(一般)
train['status_peer'] = train.status_peer.replace(-8, 2)
train['status_3_before'] = train.status_3_before.replace(-8, 2)
train['view'] = train.view.replace(-8, 3)
#inc_ability缺失值过多,将inc_ability列为-8的值,替换为0
train['inc_ability'] = train.inc_ability.replace(-8, 0)
#查看happiness的label分布
y_train_=train["happiness"]
y_train_.value_counts()
#将happiness列为-8的值,替换为3 "说不上幸福不幸福"
y_train_=y_train_.map(lambda x:3 if x==-8 else x)
train=train.drop(['work_status','work_type','work_manage','work_yr'], axis=1)3、合并数据集
合并数据集,方便同时对两个数据集进行清洗
data= train.append(test, ignore_index = True, sort=False)
print (data.shape)4、时间数据处理
规范时间格式:
data['survey_time'] = pd.to_datetime(data['survey_time'],format='%Y-%m-%d %H:%M:%S')
data["year"]=data["survey_time"].dt.year
data["quarter"]=data["survey_time"].dt.quarter
data["month"]=data["survey_time"].dt.month
data["weekday"]=data["survey_time"].dt.weekday
data["hour"]=data["survey_time"].dt.hour时间分段:
#把一天的时间分段 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









