










摘要
问题:几乎所有的方法都平等地处理图像中的前景和背景区域。
观点:前景物体的深度在三维物体的识别和定位中起着至关重要的作用。迄今为止,如何提高前景目标的深度预测精度还很少被讨论。
提出新方法ForeSeE:前景-背景分离单目深度估计方法,利用单独的优化目标和解码器来估计前景和背景深度。
1.介绍
深度是计算机视觉中二维感知和三维感知之间的桥梁。
当单目方法应用于其他专注于前景物体分析的任务时,如三维物体检测,前景深度精度低存在两个主要障碍:(1)物体中心位置估计差;(2)失真或模糊的物体形状。
物体的位置和形状不准确,使得下游的定位和识别具有挑战性。上述问题可以通过提高前景区域的深度估计性能来解决。然而,所有这些最先进的方法都同样对待前景深度和背景深度,这导致了前景对象的性能不佳。
事实上,前景深度和背景深度显示出不同的数据分布。我们在图1、图2和表1中进行了定性和定量的比较。前景像素倾向于聚集成集群,带来更多、更大的深度变化,在3D空间中看起来像挫折感,而不是像道路和建筑这样的平面。前景像素只占整个场景的一小部分。例如,在KITTI-Object数据集中(Geigeretal.2013)中,90.6%的像素属于背景,而只有9.4%的像素属于前景。此外,并非所有的像素都是相等的。如前所述,前景像素在下游应用中扮演着更重要的角色,如自动驾驶和机器人抓取。例如,汽车上的估计误差与建筑物上的相同误差有很大的不同。汽车不准确的形状和位置对3D物体探测器来说可能是灾难性的。
这些观测结果让人想知道如何在不损害背景的情况下提高前景的估计精度。从图3中可以看出,前景确实并不比背景更难。在语义分类问题中,注意机制被广泛用于关注更有区别性的局部区域,如语义分割和细粒度分类。但对于深度估计来说,情况并非如此。给定场景中汽车的特写,可以对语义类别进行分类,但不能分辨深度。另一种选择是分别训练前景区域和背景区域,因为数据分布不同的。然而,我们表明前景和背景相互依赖,以推断深度和提高性能。
相反,我们将其表述为一个多目标优化问题。将前景深度和背景深度的目标函数分开。深度解码器也是如此。因此,前景深度解码器可以尽可能地适合前景深度,同时对背景没有损伤。综上所述,我们的贡献如下:
- 我们对单目深度估计中前景和背景的差异和相互作用进行了开创性的讨论。我们表明,不同的前景深度和背景深度模式导致前景像素的次优结果。
- 我们提出预测,分别学习和预测前景和背景深度。具体来说,它包含了用于前景和背景区域的单独的深度解码器,一个目标敏感的损失基金来优化相应的解码器,以及一个简单而有效的前景-背景合并策略。
- 通过所提出的ForeSeE,我们能够预测更优越的前景深度,而背景深度不受影响。此外,利用预测的深度图,我们的模型在三维目标检测任务上获得了7.5个AP增益,有效地验证了我们的动机。
2.相关工作
- 单目深度预测:在本研究中,我们致力于提高前景目标的深度预测精度。
-
Not All Pixels are Equal:之前的一些研究注意到, 在密集的预测任务中,平等地对待所有像素是次优的。 塞维等人通过定义不同区域的不同图像运动模型来处理光流估计问题。Li等人使用深层级联,首先分割容易的像素,然后分割较难的像素。Sun等人选择并加权与真实像素相似的合成像素,用于学习语义分割。Yuan等人引入了一个针对视频帧插值问题的实例级对抗性损失。Shen等人提出了一个实例感知图像到图像的转换框架。然而,与上述工作不同的是,我们关注的是深度估计问题,旨在提高三维目标检测的精度。
-
3D目标检测: 深度信息的缺乏对从单个图像中估计三维边界框提出了一个巨大的挑战。许多作品从几何先验和估计的深度信息中寻求帮助。Deep3DBox提出基于2D-三维边界盒一致性约束生成三维提案。ROI-10D在三维边界框回归之前,从输入图像和估计深度图中提取融合特征图。MonoGRNe估计了目标3D边界盒中心的深度,以帮助3D定位。最近,一些作品(Xu和Chen2018;Wang等人,2019;Weng和Kitani2019)提出将估计的深度图转换为类似激光雷达的点云,以帮助定位三维对象。Wang等人(Wangetal.2019)直接对生成的伪激光雷达应用三维目标检测方法,并声称三维点云比二维深度图要优越得多,可以更好地利用深度信息。在这些方法中, 一个可靠的深度图,特别是精确的前景深度,是一个成功的三维目标检测框架的关键。我们使用由我们的深度估计模型生成的伪激光雷达来执行三维目标检测。该方法在很大程度上提高了其性能,且性能优于目前最先进的方法。
3. 观察与分析
3.1 准备
KITTI数据集。
基线方法。我们采用了相同的基于DCNN的基线方法(Wei等人,2019年),该方法已经在几个基准测试上显示出了最先进的性能。其主要结构属于典型的编解码器风格。给定一个输入图像,编码器提取密集的特征,然后解码器获取特征并预测量化的深度范围类别。具体来说,深度值被离散到对数空间中的100个离散的箱子中。量化的标签被分配给每个像素作为它们的分类标签。
3.2 数据分布分析
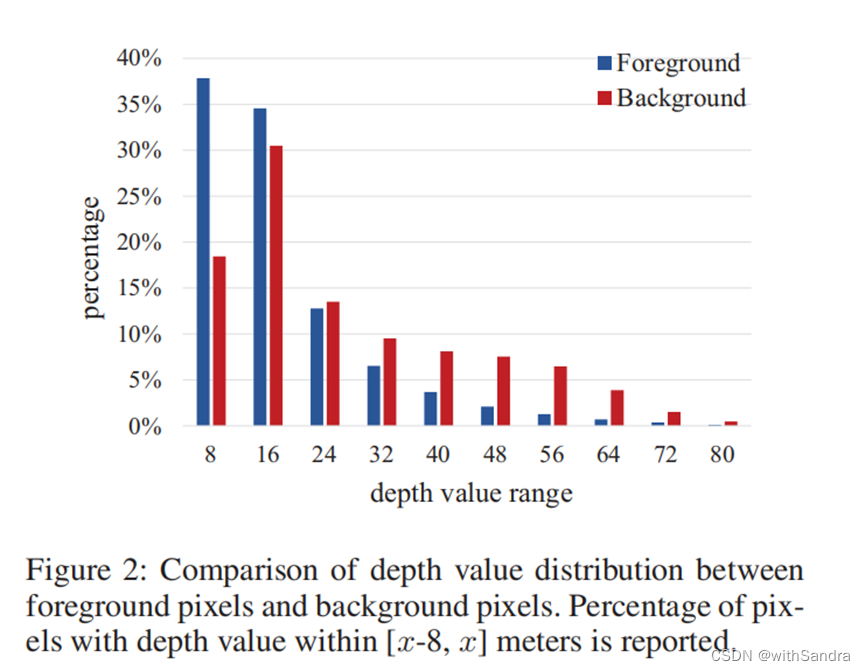
很少有作品(Jiaoetal.2018)对深度分布进行了分析,更不用说前景和背景的深度分布了。本文研究了训练子集中前景像素和背景像素的两种数据分布。图2显示了深度值的分布。如图所示,超过75%的前景像素的深度小于16m,
3.3 分离目标
这些结果是由一个CNN产生的一个单深度预测解码器,但目标函数分离。当λ设置为0时,即只使用背景样本来监督训练,前景上的结果变得非常差。类似地,当λ设置为1.0时,背景上的性能急剧下降。验证了前景深度和背景深度的分布是否不同。当我们将前景权重λ从0增加到0.1时,背景上的结果会有所改善,这说明前景和背景在一定程度上可以相互帮助。此外,需要注意的是,前景和背景的最佳λ值是不同的。例如,当λ=为0.7时,该模型在前景上表现最好,但同时在背景上的结果要差得多。说明前景和背景的优化目标并不一致。为了解决这些问题,在第4节中,提出了前背景分离深度估计的方法,以同时达到最佳点。
3.4 分析总结
我们强调了三个观察结果:前景和背景深度有不同的深度值分布、深度梯度分布和形状模式;前景和背景深度由于其共同的相似性而相互强化;前景和背景深度估计的优化目标不匹配。
4. ForeSeE
4.1独立深度解码器
前景区域从前深度解码器的输出中裁剪出来。对背景深度范围的预测也用同样的方法得到了。全局深度范围预测是由前景和背景区域的无缝合并产生的。然后使用软加权和策略将深度范围预测转换为最终的深度图(Li、Dai和He2018)。
4.2 Foreground-background Sensitive Loss Function
虽然前景深度和背景深度显示出不同的模式,但它们确实有一些相似之处,并可以在适当的比例下相互加强。因此,我们进一步加权了前景和背景样本。
4.3 Inference without Mask
5.实验
数据集。我们在KITTI数据集上进行了实验,该数据集包含了在驾驶汽车上捕获的大规模道路场景,并作为许多与自动驾驶汽车相关的计算机视觉问题的流行基准。具体来说,我们构建了KITTI-对象深度-depth(KOD)数据集来评估前景深度估计,如第3.1节所述。KOD数据集将公开,以方便未来的研究。此外,我们还将我们的方法应用于KITTI-Object数据集上进行单目三维目标检测。
评估指标。对于深度估计的评估,我们遵循一般的做法(Lietal.2018;Wei等人,2019),并使用平均绝对相对误差(absRel)和尺度不变对数误差(SILog)作为主要指标。我们还报告了平均相对平方误差(sqRel)、平均log10误差(log10)和阈值下的精度(δi)。在三维目标检测方面,我们遵循之前的工作(Liuetal.2019;秦,王,和陆2019b),重点关注于“汽车”类。我们报告了在验证集上的三维和鸟瞰视图(BEV)目标检测的结果。计算了IoU阈值为0.7时的常用平均精度(AP)。报告了KITTI简单、中、硬难度水平的结果。
实施细节。对于深度估计,我们遵循基线方法中的大多数设置(Weietal.2019)。使用ImageNet预训练的ResNeXt-101(Xieetal.2017)作为骨干模型。我们训练网络20个epoch,批大小为4,基本学习率设置为0.001。采用随机梯度下降(SGD)求解器对单个GPU上的网络进行了优化。前景-背景敏感损失函数中的λf和λb设置为0.2。给定一个预测的深度图,可以基于针孔摄像机模型重建点云。
定量结果。我们在表2中显示了烧蚀结果。我们的ForeSeE在前景、背景和全球层面上评估的所有指标上都优于基线。具体来说,当在前景水平上进行评估时,我们的方法将基线性能提高了高达8.5%(从0.129提高到0.118absRel)。根据我们的意图,前景是专门设计来提高估计前景深度的能力。我们进一步分析了每个成分的影响。当配备了第3.3节中描述的单独目标(SO)时,基线在前景上获得更好的结果,而在背景像素上进行评估时表现更差。直接使用单独的解码器(SD)可以避免对背景的危害。最后,通过应用前景-背景敏感损失(FSL),进一步提高了前景上的性能。为了与其他最先进的方法进行比较,我们将密度深度(阿尔哈希姆和旺卡2018)应用于KOD基准,该基准报告了KITTI(Geiger等人2013)和NYUv2(西尔伯曼等人2012)的数据集的最佳性能。我们得到了D的结果














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









