







stacking
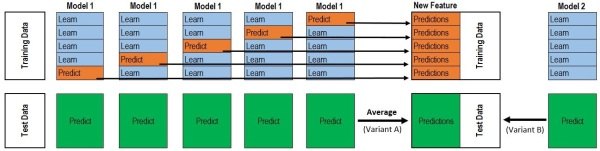
如图,上半部分是用一个基础模型进行5折交叉验证。拿出四折作为training data,另外一折作为testing data。每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到5组关于当前testing data的预测值,记作a1,a2,a3,a4,a5,即图的下半部分5个绿色框,将他们拼凑起来,会形成一个矩阵,记为A1。在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这部分预测值将会作为下一层模型testing data的一部分,记为b1,b2,b3,b4,b5,即右下方的绿色框,我们将它们相加取平均值,得到一个列向量,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。我们把A1,A2,A3,A4,A5并列合并得到一个矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个矩阵作为testing data。让下一层的模型,基于他们进一步训练。















07-13
 1349
1349
1349
04-24
7015
7015
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









