






参考:
(1)官方学习途径:https://github.com/huggingface/diffusion-models-class/tree/main/unit2
(2)视频课程讲解:https://www.youtube.com/watch?v=Vl8-1f1rOpI&list=PLAr9oL1AT4OGtvIACGQWo5lYvPeoOGO5v&index=3
实战训练
改进思路:
mimic上面加一个referencenet,其余全部都不变,想办法让学习更多的细节

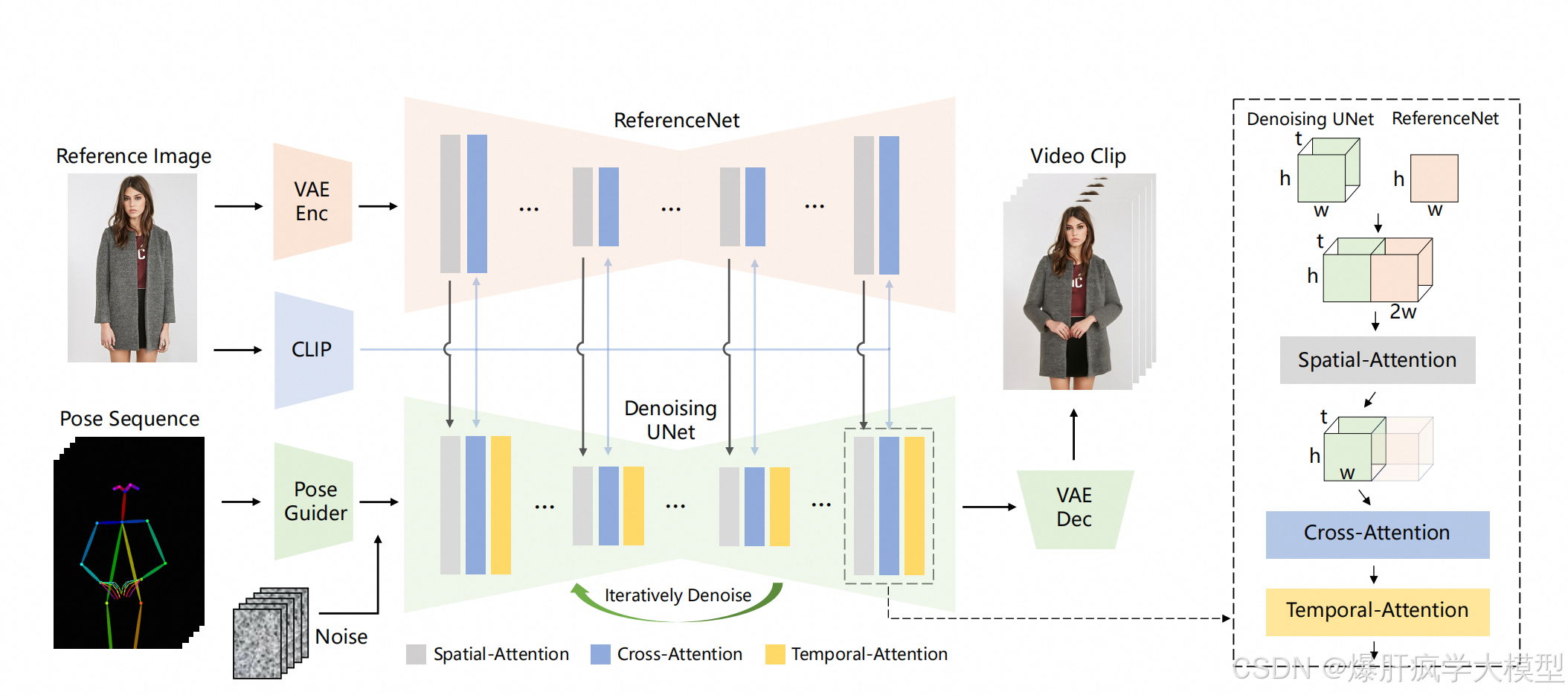
攻克难点
svd相关问题
参考:svd介绍
SVD 的训练由三个阶段组成:文生图预训练、视频预训练、高质量视频微调。
SVD 提出了一种系统性的数据精制流程,包含数据的标注与过滤这两部分的策略。
- 为什么svd生成的效果不好,具体在哪里进行使用
所有的底层架构用的都是svd模型的,虽然我认为可以更换为sd的试试,详情可看下面代码
feature_extractor = CLIPImageProcessor.from_pretrained(
args.pretrained_model_name_or_path, subfolder="feature_extractor", revision=args.revision
)
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_model_name_or_path, subfolder="image_encoder", revision=args.revision
)
vae = AutoencoderKLTemporalDecoder.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
noise_scheduler = EulerDiscreteScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler")
unet = UNetSpatioTemporalConditionModel.from_config(
args.pretrained_model_name_or_path, subfolder="unet"
)
# 对应musepose
val_noise_scheduler = DDIMScheduler(**sched_kwargs)
sched_kwargs.update({"beta_schedule": "scaled_linear"})
train_noise_scheduler = DDIMScheduler(**sched_kwargs)
clip_image_processor = CLIPImageProcessor()
image_enc = CLIPVisionModelWithProjection.from_pretrained(
cfg.pretrained_base_model_path,
subfolder="image_encoder",
).to(dtype=weight_dtype, device=accelerator.device)
vae = AutoencoderKL.from_pretrained(cfg.pretrained_vae_path).to(
accelerator.device, dtype=weight_dtype
)
reference_unet = UNet2DConditionModel.from_pretrained(
cfg.pretrained_base_model_path,
subfolder="unet",
).to(accelerator.device)
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
cfg.pretrained_base_model_path,
"",
subfolder="unet",
unet_additional_kwargs={
"use_motion_module": False,
"unet_use_temporal_attention": False,
},
).to(accelerator.device)
- 既然svd效果不好,可以直接换成sd去使用吗
animateanyone中的referencenet进行嵌入
规划在哪里嵌入
-
musepose的上半部分
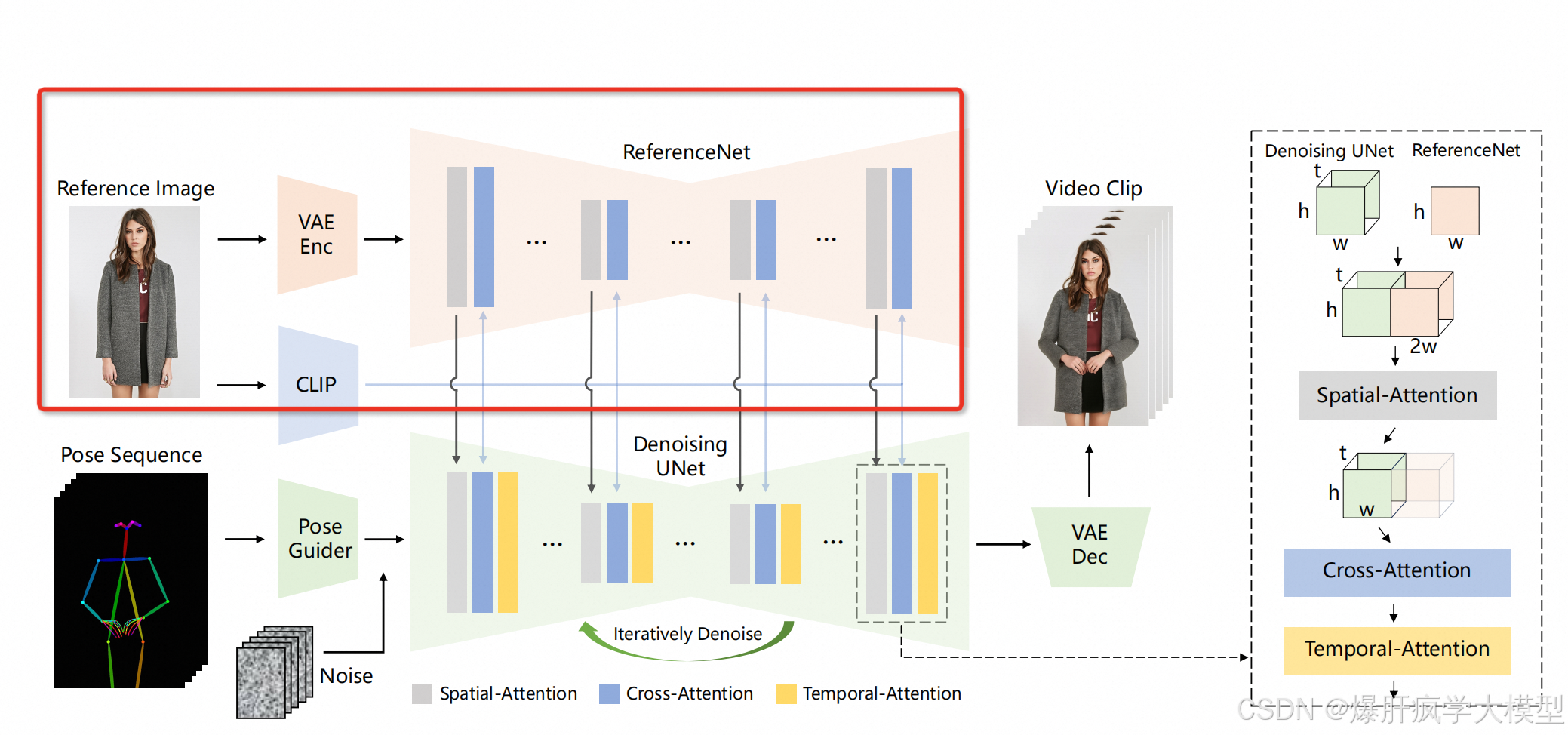
-
结合mimicmotion的下部分
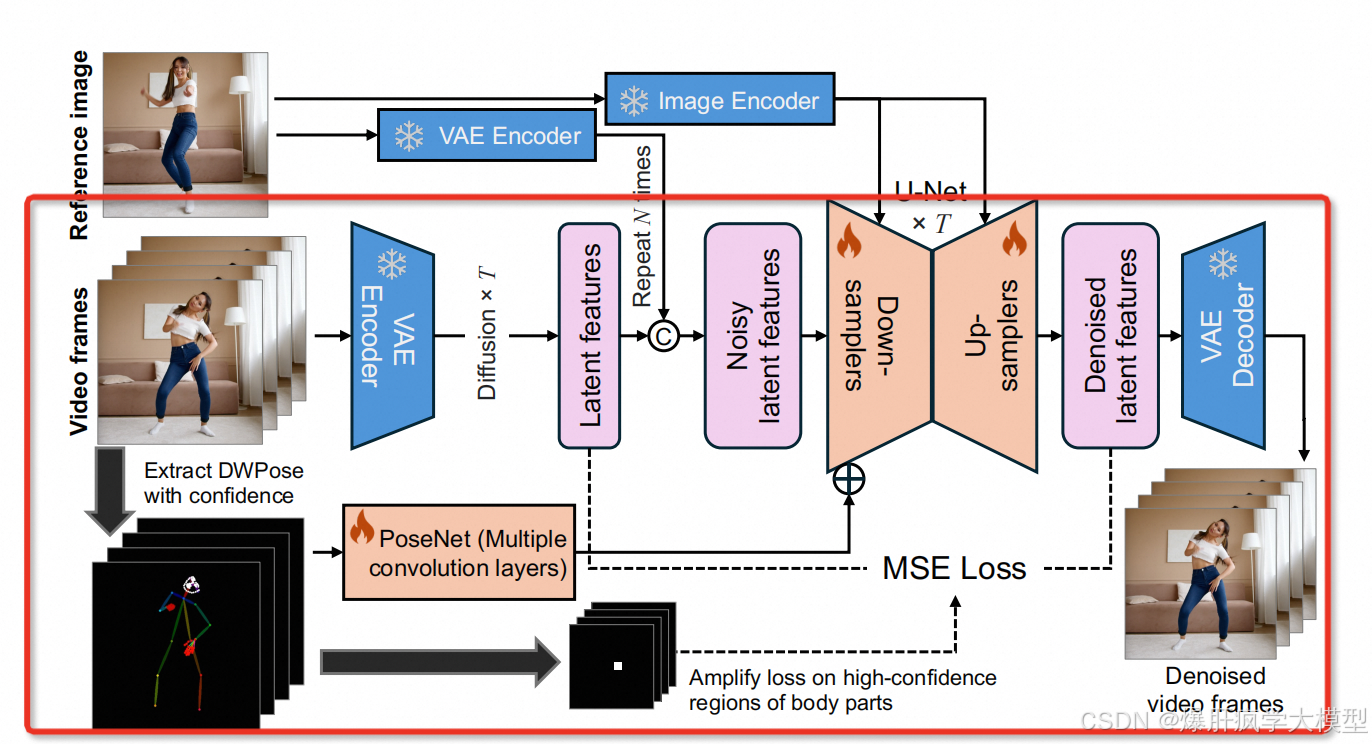
-
如果效果还不好,就把mimic的底层模型改为sd
-
还可以考虑musepose的denoising unet也换过来
根据规划内容看mimic目前具体架构
- 获取参考图片image encoder
def encode_image(pixel_values):
# pixel: [-1, 1]
pixel_values = _resize_with_antialiasing(pixel_values, (224, 224))
# We unnormalize it after resizing.
pixel_values = (pixel_values + 1.0) / 2.0
# Normalize the image with for CLIP input
pixel_values = feature_extractor(
images=pixel_values,
do_normalize=True,
do_center_crop=False,
do_resize=False,
do_rescale=False,
return_tensors="pt",
).pixel_values
pixel_values = pixel_values.to(
device=accelerator.device, dtype=weight_dtype)
image_embeddings = image_encoder(pixel_values).image_embeds
image_embeddings = image_embeddings.unsqueeze(1)
return image_embeddings
# first, convert images to latent space.
# Get the text embedding for conditioning.
encoder_hidden_states = encode_image(pixel_values_ref)
- 获取参考图片的vae encoder
def tensor_to_vae_latent(t, vae, scale=True):
video_length = t.shape[1]
t = rearrange(t, "b f c h w -> (b f) c h w")
latents = vae.encode(t).latent_dist.sample()
latents = rearrange(latents, "(b f) c h w -> b f c h w", f=video_length)
if scale:
latents = latents * vae.config.scaling_factor
return latents
train_noise_aug = 0.0
pixel_values_ref = pixel_values_ref + train_noise_aug * torch.randn_like(pixel_values_ref)
# Sample masks for the original images.
image_mask_dtype = ref_latents.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(
image_mask_dtype)
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
ref_latents = tensor_to_vae_latent(pixel_values_ref[:, None], vae, scale=scale_latents)[:, 0]
# Final image conditioning.
ref_latents = image_mask * ref_latents
- inp_noisy_latents的生成
# 1. 视频转化为latent,因为这部不怎么需要变,所以不再过多去介绍
latents = tensor_to_vae_latent(pixel_values_vid, vae)
sigmas = rand_log_normal(shape=[bsz, ], loc=0.7, scale=1.6).to(latents.device)
noise = torch.randn_like(latents)
noisy_latents = latents + noise * sigmas
inp_noisy_latents = noisy_latents / ((sigmas ** 2 + 1) ** 0.5)
# 2.结合上一部分ref_latents的介绍,直接转换
inp_noisy_latents = torch.cat([inp_noisy_latents, ref_latents], dim=2)
- 条件输入unet内
model_pred = unet(
inp_noisy_latents,
timesteps,
encoder_hidden_states, # image encoder
added_time_ids=added_time_ids,
pose_latents=pose_latents.flatten(0, 1)
).sample
# 解释下上面的具体输入
# 1.一种转换方法吧,代码中是这样描述的,Here I input a fixed numerical value for 'motion_bucket_id', which is not reasonable.However, I am unable to fully align with the calculation method of the motion score, so I adopted this approach. The same applies to the 'fps' (frames per second).
added_time_ids = _get_add_time_ids(
7, # fixed
127, # motion_bucket_id = 127, fixed
train_noise_aug, # noise_aug_strength == cond_sigmas
encoder_hidden_states.dtype,
bsz,
)
added_time_ids = added_time_ids.to(latents.device)
# 2. pose_latents,这个应该不会动,所以可以保留
# 3. timesteps,定值,可以不动
musepose看怎么把信息提取出来
# 找到ref_image_latents
vae = AutoencoderKL.from_pretrained(cfg.pretrained_vae_path).to(
accelerator.device, dtype=weight_dtype
)
# Freeze and train
vae.requires_grad_(False)
pixel_values_ref = batch["pixel_values_ref"].to(weight_dtype).to(
accelerator.device, non_blocking=True
with torch.no_grad():
ref_image_latents = vae.encode(
pixel_values_ref
).latent_dist.sample()
ref_image_latents = ref_image_latents * 0.18215
# 找到image_prompt_embeds
clip_image_processor = CLIPImageProcessor()
image_enc = CLIPVisionModelWithProjection.from_pretrained(
cfg.pretrained_base_model_path,
subfolder="image_encoder",
).to(dtype=weight_dtype, device=accelerator.device)
# Freeze and train
image_enc.requires_grad_(False)
ref_image_latents = vae.encode(
pixel_values_ref
).latent_dist.sample() # (bs, d, 64, 64)
pixel_values_clip = F.interpolate(pixel_values_ref, (224, 224), mode="bilinear", align_corners=True)
pixel_values_clip = (pixel_values_clip + 1) / 2.0
pixel_values_clip = clip_image_processor(
images=pixel_values_clip,
do_normalize=True,
do_center_crop=False,
do_resize=False,
do_rescale=False,
return_tensors="pt",
).pixel_values
clip_image_embeds = image_enc(
pixel_values_clip.to(accelerator.device, dtype=weight_dtype)
).image_embeds
image_prompt_embeds = clip_image_embeds.unsqueeze(1) # (bs, 1, d)
# 找到timesteps todo:先不用这个,看看效果
# Sample a random timestep for each video
train_noise_scheduler = DDIMScheduler(**sched_kwargs)
timesteps = torch.randint(
0,
train_noise_scheduler.num_train_timesteps,
(bsz,),
device=latents.device,
)
timesteps = timesteps.long()
# musepose 的
model_pred = net(
noisy_latents, # noisy
timesteps, # timesteps
ref_image_latents, # vae
image_prompt_embeds, # clip
pixel_values_cond # ?
)
# 我们需要改的
model_pred = unet( ref_image_latents,# musepose reference_unet
image_prompt_embeds, # musepose reference_unet
inp_noisy_latents,
timesteps,
ref_latents,
added_time_ids,
encoder_hidden_states,
pose_latents.flatten(0, 1)
)
ref_timesteps = torch.zeros_like(timesteps)
self.reference_unet(
ref_image_latents,
ref_timesteps,
encoder_hidden_states=encoder_hidden_states,
return_dict=False,
)
unet(
inp_noisy_latents,
timesteps,
encoder_hidden_states,
added_time_ids=added_time_ids,
pose_latents=pose_latents.flatten(0, 1)
).sample
model_pred = self.denoising_unet(
inp_noisy_latents,
timesteps,
encoder_hidden_states,
added_time_ids=added_time_ids,
pose_latents=pose_latents.flatten(0, 1)
).sample
# 最终输入
model_pred = net(
noisy_latents,
timesteps,
ref_image_latents,
image_prompt_embeds,
pixel_values_cond,
uncond_fwd
)
方法准备
# 扰动
val_noise_scheduler = DDIMScheduler(**sched_kwargs)
# unet会用到
sched_kwargs.update({"beta_schedule": "scaled_linear"})
# 扰动
train_noise_scheduler = DDIMScheduler(**sched_kwargs)
# vae编码
vae = AutoencoderKL.from_pretrained(cfg.pretrained_vae_path).to(
accelerator.device, dtype=weight_dtype
)
# reference_unet,本项目特定的,应该是根据sd迁移过来的unet模块
reference_unet = UNet2DConditionModel.from_pretrained(
cfg.pretrained_base_model_path,
subfolder="unet",
).to(accelerator.device)
# denoising_unet,本项目特定的,应该是根据sd迁移过来的unet模块
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
cfg.pretrained_base_model_path,
"",
subfolder="unet",
unet_additional_kwargs={
"use_motion_module": False,
"unet_use_temporal_attention": False,
},
).to(accelerator.device)
# clip,获取image_enc
clip_image_processor = CLIPImageProcessor()
image_enc = CLIPVisionModelWithProjection.from_pretrained(
cfg.pretrained_base_model_path,
subfolder="image_encoder",
).to(dtype=weight_dtype, device=accelerator.device)
# pose_guider,姿态信息提取
pose_guider = PoseGuider(320, block_out_channels=(16, 32, 96, 256)).to(device=accelerator.device)
参数导入
# load pretrained weights
if cfg.denoising_unet_path and os.path.exists(cfg.denoising_unet_path):
logger.info(f"loading pretrained denoising_unet_path: {cfg.denoising_unet_path}")
denoising_unet.load_state_dict(
torch.load(cfg.denoising_unet_path, map_location="cpu"),
strict=False,
)
if cfg.reference_unet_path and os.path.exists(cfg.reference_unet_path):
logger.info(f"loading pretrained reference_unet_path: {cfg.reference_unet_path}")
reference_unet.load_state_dict(
torch.load(cfg.reference_unet_path, map_location="cpu"),
)
if cfg.pose_guider_path and os.path.exists(cfg.pose_guider_path):
logger.info(f"loading pretrained pose_guider_path: {cfg.pose_guider_path}")
pose_guider.load_state_dict(
torch.load(cfg.pose_guider_path, map_location="cpu"),
)
grad
requires_grad:如果一个Tensor的requires_grad属性被设置为True,PyTorch会追踪所有与这个张量有关的操作。这样在进行反向传播时,就可以自动得到这个Tensor的梯度了。
.backward():当你完成了前向传递并计算出了损失之后,可以调用损失Tensor上的.backward()方法来计算梯度。这个操作会计算损失相对于模型参数的梯度。
.grad:在调用.backward()之后,所有参与运算并设置了requires_grad=True的Tensor的梯度将累积在它们的.grad属性中。
.detach():如果你希望从计算历史中移除一个Tensor,使其以后的操作不再追踪计算梯度,可以使用.detach()方法。
# Freeze and train
vae.requires_grad_(False)
image_enc.requires_grad_(False)
denoising_unet.requires_grad_(True)
reference_unet.requires_grad_(True)
pose_guider.requires_grad_(True)
# Some top layer parames of reference_unet don't need grad
# reference_unet一些置顶的层级不需要grad
for name, param in reference_unet.named_parameters():
if "up_blocks.3" in name:
param.requires_grad_(False)
else:
param.requires_grad_(True)
reference_control_writer、reference_control_reader
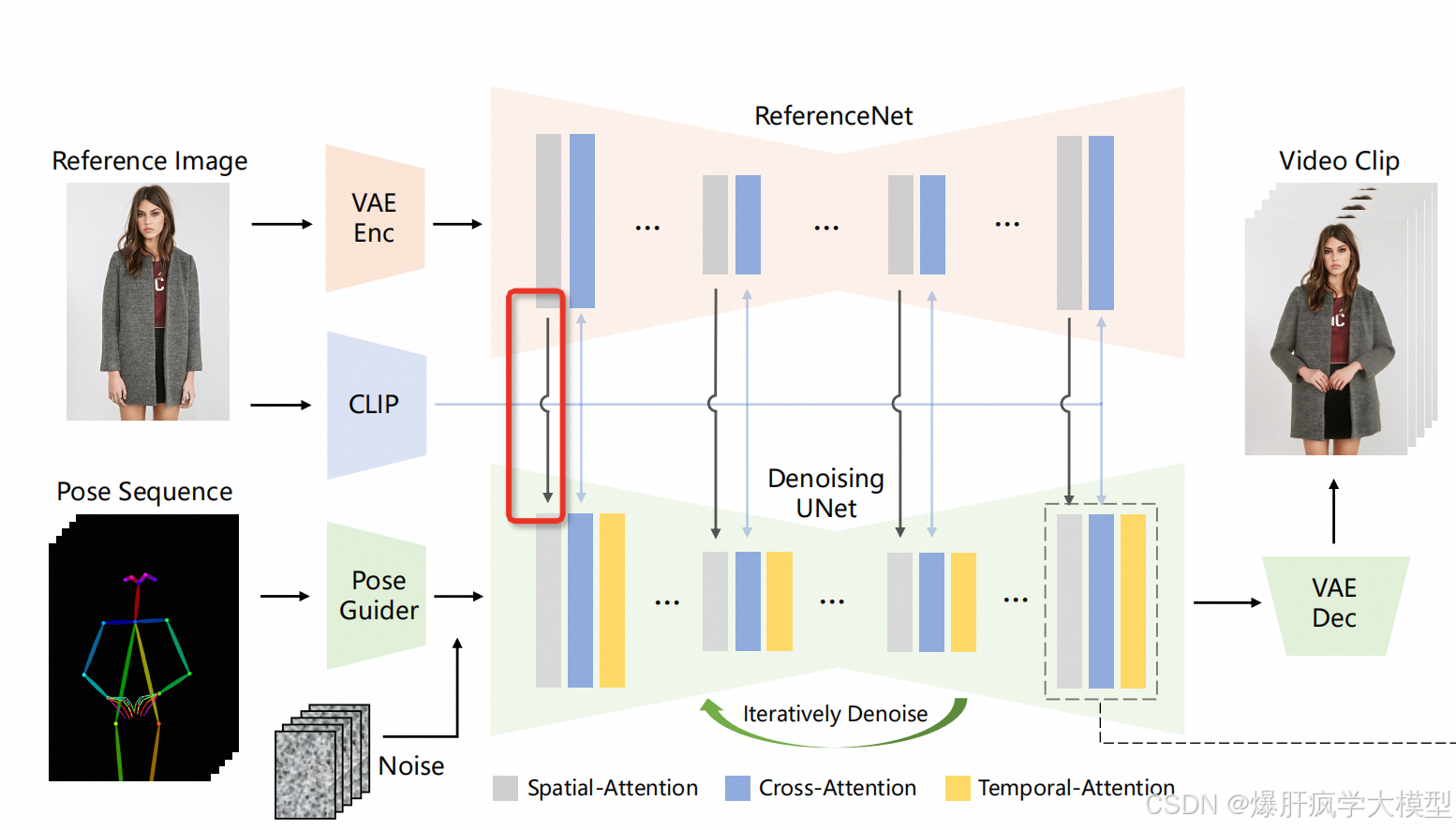
很巧妙的设计,referencenet负责写spatial-attention的权重,后面会通过self.reference_control_reader.update(self.reference_control_writer)的方式,将referencenet中spatial-attention的结果更新到denoising unet上。
reference_control_writer = ReferenceAttentionControl(
reference_unet,
mode="write",
fusion_blocks="full",
)
reference_control_reader = ReferenceAttentionControl(
denoising_unet,
mode="read",
fusion_blocks="full",
)
- ReferenceAttentionControl介绍
class ReferenceAttentionControl:
def __init__(
self,
unet,
mode="write",
attention_auto_machine_weight=float("inf"),
gn_auto_machine_weight=1.0,
style_fidelity=1.0,
reference_attn=True,
reference_adain=False,
fusion_blocks="midup",
batch_size=1,
) -> None:
# 10. Modify self attention and group norm
self.unet = unet
assert mode in ["read", "write"]
assert fusion_blocks in ["midup", "full"]
self.reference_attn = reference_attn
self.reference_adain = reference_adain
self.fusion_blocks = fusion_blocks
self.register_reference_hooks(
mode,
attention_auto_machine_weight,
gn_auto_machine_weight,
style_fidelity,
reference_attn,
reference_adain,
fusion_blocks,
batch_size=batch_size,
)
# 先看下forward操作
if self.reference_attn:
if self.fusion_blocks == "midup":
attn_modules = [
module
for module in (
torch_dfs(self.unet.mid_block) + torch_dfs(self.unet.up_blocks)
)
if isinstance(module, BasicTransformerBlock)
or isinstance(module, TemporalBasicTransformerBlock)
]
elif self.fusion_blocks == "full":
attn_modules = [
module
for module in torch_dfs(self.unet)
if isinstance(module, BasicTransformerBlock)
or isinstance(module, TemporalBasicTransformerBlock)
]
attn_modules = sorted(
attn_modules, key=lambda x: -x.norm1.normalized_shape[0]
)
#
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
if isinstance(module, BasicTransformerBlock):
module.forward = hacked_basic_transformer_inner_forward.__get__(
module, BasicTransformerBlock
)
if isinstance(module, TemporalBasicTransformerBlock):
module.forward = hacked_basic_transformer_inner_forward.__get__(
module, TemporalBasicTransformerBlock
)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
# 写操作的计算逻辑
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
# self.only_cross_attention = False
cross_attention_kwargs = (
cross_attention_kwargs if cross_attention_kwargs is not None else {}
)
if MODE == "write":
self.bank.append(norm_hidden_states.clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states
if self.only_cross_attention
else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep)
if self.use_ada_layer_norm
else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
执行逻辑在hacked_basic_transformer_inner_forward函数里看
# 1. Self-Attention
# self.only_cross_attention = False
# self attent的时候直接计算
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states
if self.only_cross_attention
else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
# referencenet计算的时候,很常规计算self.attn1
if MODE == "write":
self.bank.append(norm_hidden_states.clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states
if self.only_cross_attention
else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
# denosenet计算的时候读referencenet的信息
if MODE == "read":
bank_fea = [
rearrange(
d.unsqueeze(1).repeat(1, video_length, 1, 1),
"b t l c -> (b t) l c",
)
for d in self.bank
]
modify_norm_hidden_states = torch.cat(
[norm_hidden_states] + bank_fea, dim=1
)
hidden_states_uc = (
self.attn1(
norm_hidden_states,
encoder_hidden_states=modify_norm_hidden_states,
attention_mask=attention_mask,
)
+ hidden_states
)
if do_classifier_free_guidance:
hidden_states_c = hidden_states_uc.clone()
_uc_mask = uc_mask.clone()
if hidden_states.shape[0] != _uc_mask.shape[0]:
_uc_mask = (
torch.Tensor(
[1] * (hidden_states.shape[0] // 2)
+ [0] * (hidden_states.shape[0] // 2)
)
.to(device)
.bool()
)
hidden_states_c[_uc_mask] = (
self.attn1(
norm_hidden_states[_uc_mask],
encoder_hidden_states=norm_hidden_states[_uc_mask],
attention_mask=attention_mask,
)
+ hidden_states[_uc_mask]
)
hidden_states = hidden_states_c.clone()
else:
hidden_states = hidden_states_uc
# self.bank.clear()
if self.attn2 is not None:
# Cross-Attention
norm_hidden_states = (
self.norm2(hidden_states, timestep)
if self.use_ada_layer_norm
else self.norm2(hidden_states)
)
hidden_states = (
self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
)
+ hidden_states
)
# Feed-forward
hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states
# Temporal-Attention
if self.unet_use_temporal_attention:
d = hidden_states.shape[1]
hidden_states = rearrange(
hidden_states, "(b f) d c -> (b d) f c", f=video_length
)
norm_hidden_states = (
self.norm_temp(hidden_states, timestep)
if self.use_ada_layer_norm
else self.norm_temp(hidden_states)
)
hidden_states = (
self.attn_temp(norm_hidden_states) + hidden_states
)
hidden_states = rearrange(
hidden_states, "(b d) f c -> (b f) d c", d=d
)
return hidden_states
整合整个网络架构
net = Net(
reference_unet,
denoising_unet,
pose_guider,
reference_control_writer,
reference_control_reader,
)
代码解析
数据源创建
train_dataset = MimicMotionVideoDataset(
img_size=(args.height, args.width),
img_scale=(0.8, 1.0),
img_ratio=(0.5, 0.6),
sample_rate=1,
n_sample_frames=args.num_frames,
cond_type=args.cond_type,
meta_paths=[
"./data/TikTok",
"./data/UBC_fashion",
"./data/cartoon_0830",
"./data/cartoon_0831",
"./data/youtube_man",
"./data/yht",
"./data/youtube_0818",
"./data/youtube_0821",
"./data/youtube_man_0907",
],
)
模型介绍:
- CLIP
介绍:利用文本和图像的对应关系组建的数据集进行模型训练,能够表示出图片和文本的关联关系。
参考:
(1)深度学习/计算机视觉实验常用技巧(以CLIP模型训练为例)
(2)clip原理详解 - VAE
介绍:stable diffusion的模型基础,常用于生成式训练。自动编码器模块,我们将使用它来将潜在表示解码为真实图像。
参考:(1)vae原理介绍 - unet
介绍:stable diffusion的模型基础,进行噪声预测
参考:(1)unet模型详解以及训练自己的unet模型
(2)Stable Diffusion 超详细讲解 - posenet
介绍:多层卷积层。被设计用来获取姿态序列的特征。
# Load img encoder, tokenizer and models.
# 图片预处理器,调用其中的preprocess方法,在返回值中获取pixel_values
feature_extractor = CLIPImageProcessor.from_pretrained(
args.pretrained_model_name_or_path, subfolder="feature_extractor", revision=args.revision
)
# 视觉编码器
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_model_name_or_path, subfolder="image_encoder", revision=args.revision
)
vae = AutoencoderKLTemporalDecoder.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
noise_scheduler = EulerDiscreteScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler")
unet = UNetSpatioTemporalConditionModel.from_config(
args.pretrained_model_name_or_path, subfolder="unet"
)
# PoseNet, which is implemented with multiple convolution layers, is designed as a trainable module for extracting features of the input sequence of poses.
cond_net = PoseNet(noise_latent_channels=unet.config.block_out_channels[0])
mimicmotion
for epoch in range(first_epoch, args.num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
unet.train()
# cond_net.train()
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
with accelerator.accumulate(unet, cond_net):
# pixel_values_vid 视频每一帧的值
pixel_values_vid = batch["pixel_values_vid"].to(weight_dtype).to(
accelerator.device, non_blocking=True
)
# pose视频的每一帧
pixel_values_cond = batch["pixel_values_cond"].to(weight_dtype).to(
accelerator.device, non_blocking=True
)
# 目标图片的像素值
pixel_values_ref = batch["pixel_values_ref"].to(weight_dtype).to(
accelerator.device, non_blocking=True
)
if "mask_values_cond" in batch:
mask_values_cond = batch["mask_values_cond"].to(weight_dtype).to(
accelerator.device, non_blocking=True
)
# 重新调整图片比例
if random.random() > 0.:
with torch.no_grad():
org_B, org_F, org_C, org_H, org_W = pixel_values_vid.shape
# 随机选择新的宽度和高度
new_width = org_W
# new_width = random.choice(range(320, org_W + 1, 64)) # 320到576之间的随机宽度,步长为64
new_height = random.choice(range(576, org_H + 1, 64)) # 576到1024之间的随机高度,步长为64
# 计算缩放比例
scale_factor_w = new_width / org_W
scale_factor_h = new_height / org_H
# 缩放因子影响到F的维度,面积缩放比例为w*h,F的缩放因子为sqrt(w*h)
scale_factor_f = (scale_factor_w * scale_factor_h) ** 0.5
scale_factor_f = int(scale_factor_f * 10) / 10.0
# new_F = min(int(16 / scale_factor_f), org_F)
new_F = org_F
start_ind = random.randint(0, org_F - new_F)
pixel_values_vid = rearrange(pixel_values_vid, "b f c h w -> (b f) c h w")
pixel_values_vid = F.interpolate(pixel_values_vid, size=(new_height, new_width),
mode='bilinear', align_corners=True)
pixel_values_vid = rearrange(pixel_values_vid, "(b f) c h w -> b f c h w", b=org_B)
pixel_values_vid = pixel_values_vid[:, start_ind:start_ind + new_F].contiguous()
pixel_values_cond = rearrange(pixel_values_cond, "b f c h w -> (b f) c h w")
pixel_values_cond = F.interpolate(pixel_values_cond, size=(new_height, new_width),
mode='bilinear', align_corners=True)
pixel_values_cond = rearrange(pixel_values_cond, "(b f) c h w -> b f c h w", b=org_B)
pixel_values_cond = pixel_values_cond[:, start_ind:start_ind + new_F].contiguous()
pixel_values_ref = F.interpolate(pixel_values_ref, size=(new_height, new_width), mode='bilinear',
align_corners=True)
if "mask_values_cond" in batch:
mask_values_cond = rearrange(mask_values_cond, "b f c h w -> (b f) c h w")
mask_values_cond = F.interpolate(mask_values_cond, size=(new_height, new_width), mode='nearest')
mask_values_cond = rearrange(mask_values_cond, "(b f) c h w -> b f c h w", b=org_B)
mask_values_cond = mask_values_cond[:, start_ind:start_ind + new_F].contiguous()
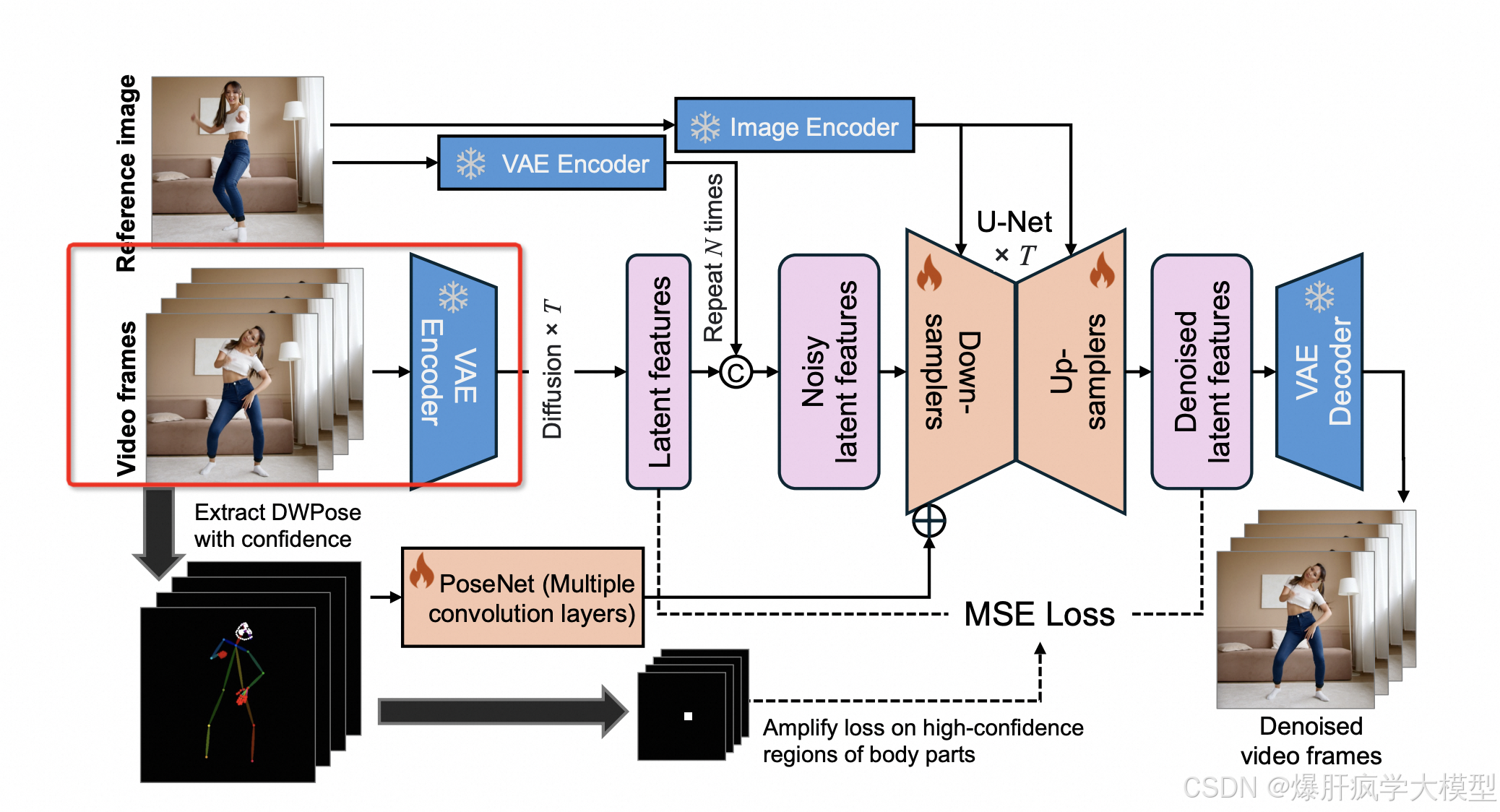
mimicmotion视频图片进行vae编码
# 将图片映射到latent space
def tensor_to_vae_latent(t, vae, scale=True):
video_length = t.shape[1]
t = rearrange(t, "b f c h w -> (b f) c h w")
latents = vae.encode(t).latent_dist.sample()
latents = rearrange(latents, "(b f) c h w -> b f c h w", f=video_length)
if scale:
latents = latents * vae.config.scaling_factor
return latents
# first, convert images to latent space.
latents = tensor_to_vae_latent(pixel_values_vid, vae)
bsz = latents.shape[0]
if "mask_values_cond" in batch:
mask_values_cond = rearrange(mask_values_cond, "b f c h w -> (b f) c h w")
mask_values_cond = F.interpolate(mask_values_cond, size=latents.shape[-2:], mode='nearest')
mask_values_cond = rearrange(mask_values_cond, "(b f) c h w -> b f c h w", b=bsz)
mimicmotion进行图像编码
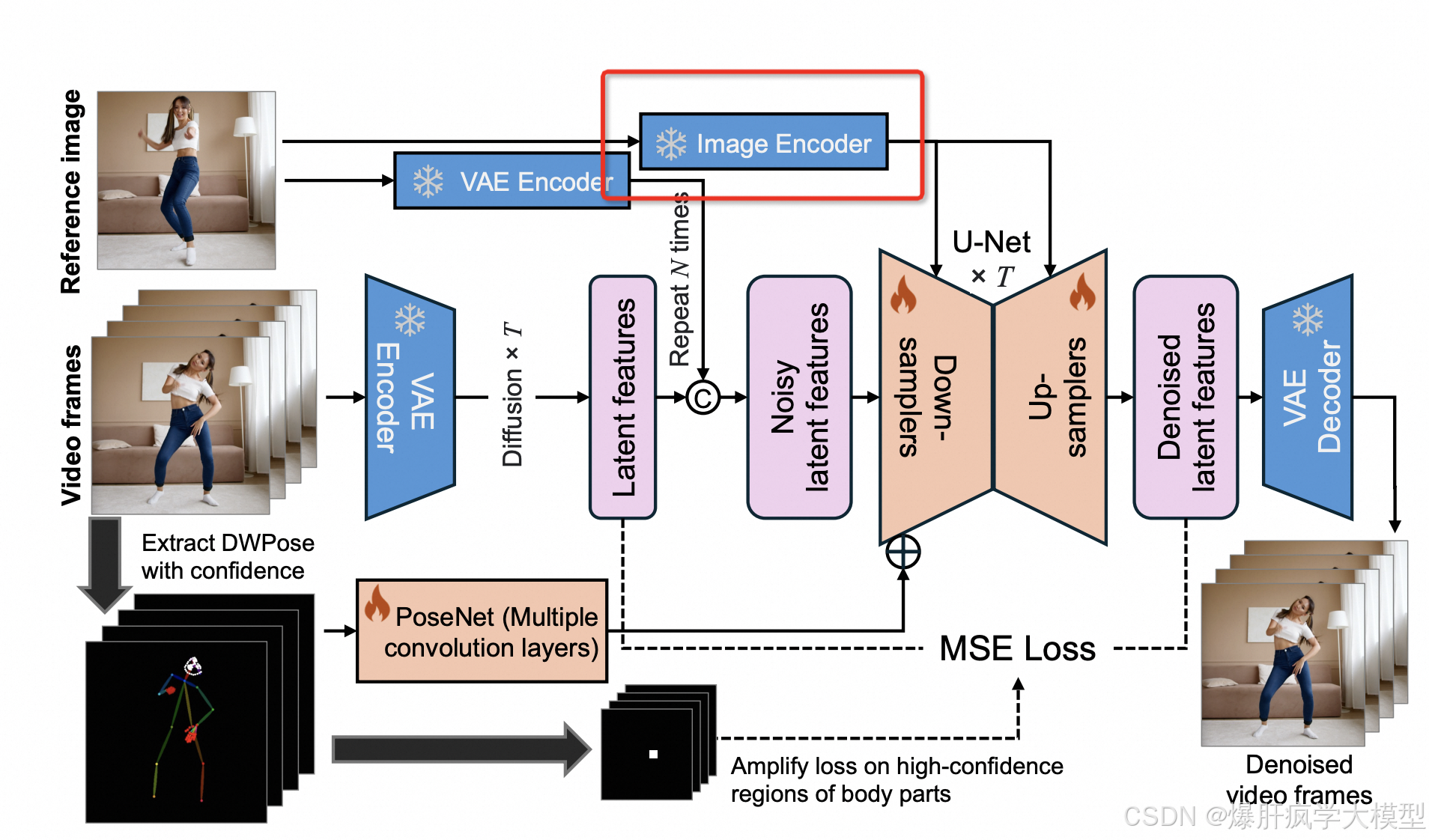
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_model_name_or_path, subfolder="image_encoder", revision=args.revision
)
feature_extractor = CLIPImageProcessor.from_pretrained(
args.pretrained_model_name_or_path, subfolder="feature_extractor", revision=args.revision
)
def encode_image(pixel_values):
# pixel: [-1, 1]
pixel_values = _resize_with_antialiasing(pixel_values, (224, 224))
# We unnormalize it after resizing.
pixel_values = (pixel_values + 1.0) / 2.0
# Normalize the image with for CLIP input
pixel_values = feature_extractor(
images=pixel_values,
do_normalize=True,
do_center_crop=False,
do_resize=False,
do_rescale=False,
return_tensors="pt",
).pixel_values
pixel_values = pixel_values.to(
device=accelerator.device, dtype=weight_dtype)
image_embeddings = image_encoder(pixel_values).image_embeds
image_embeddings = image_embeddings.unsqueeze(1)
return image_embeddings
# Get the text embedding for conditioning.
encoder_hidden_states = encode_image(pixel_values_ref)
# 查看encoder_hidden_states的debug 信息
encoder_hidden_states.shape
torch.Size([1, 1, 1024])
ref images 进行vae encoder
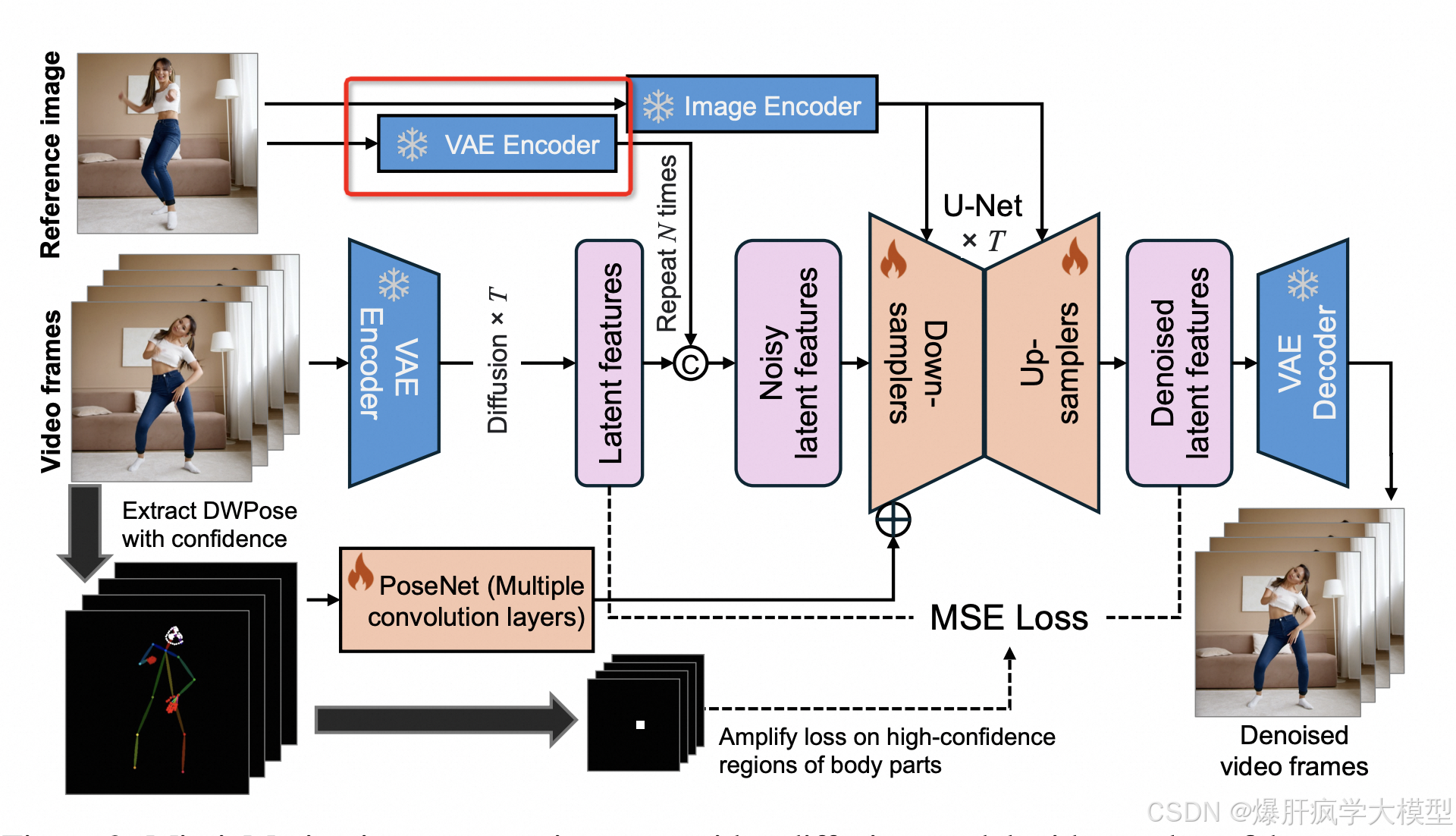
def tensor_to_vae_latent(t, vae, scale=True):
video_length = t.shape[1]
t = rearrange(t, "b f c h w -> (b f) c h w")
latents = vae.encode(t).latent_dist.sample()
latents = rearrange(latents, "(b f) c h w -> b f c h w", f=video_length)
if scale:
latents = latents * vae.config.scaling_factor
return latents
train_noise_aug = 0.0
pixel_values_ref = pixel_values_ref + train_noise_aug * torch.randn_like(pixel_values_ref)
ref_latents = tensor_to_vae_latent(pixel_values_ref[:, None], vae, scale=scale_latents)[:, 0]
mimicmotion进行加噪声
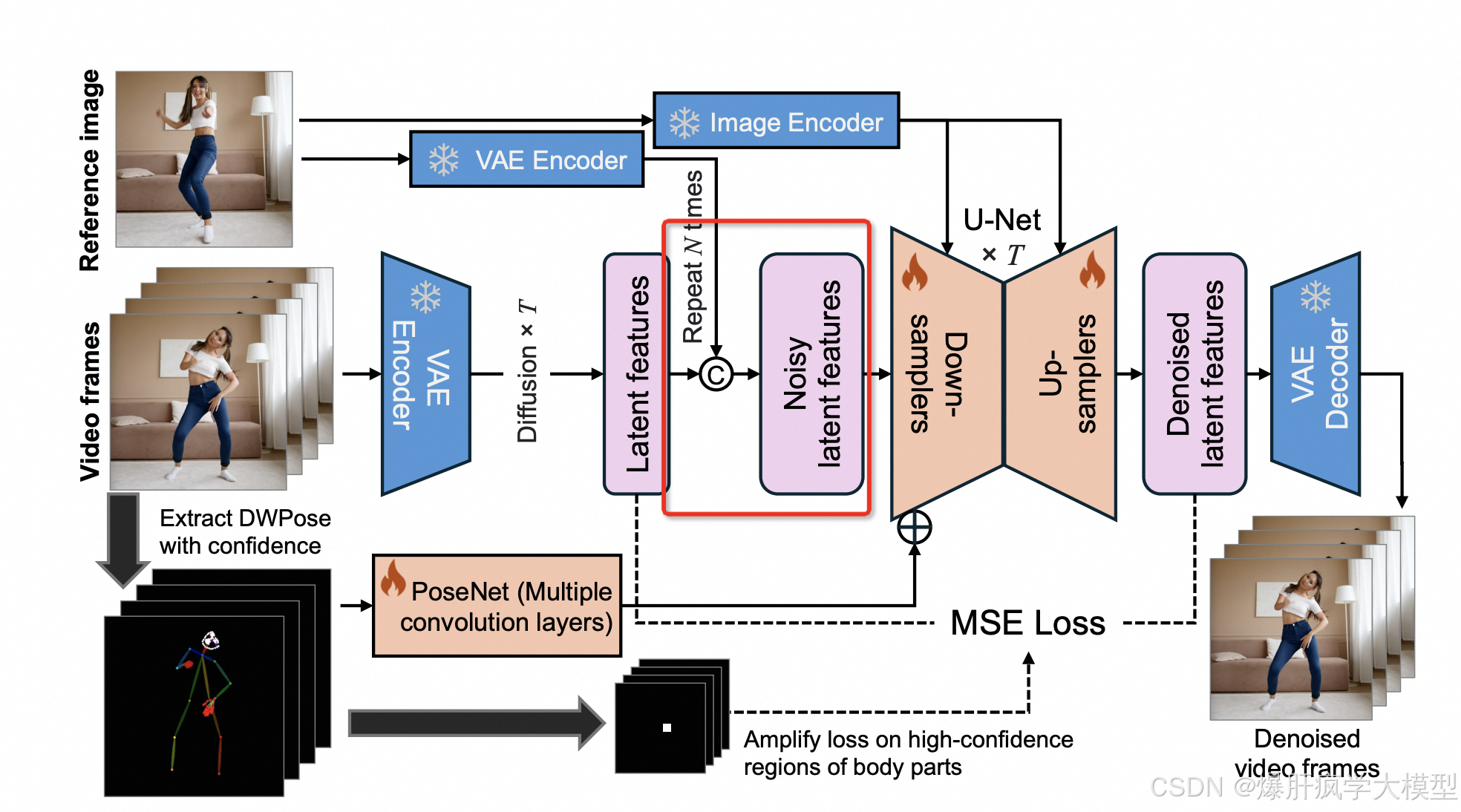
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
sigmas = rand_log_normal(shape=[bsz, ], loc=0.7, scale=1.6).to(latents.device)
sigmas = sigmas[:, None, None, None, None]
noisy_latents = latents + noise * sigmas
timesteps = torch.Tensor([0.25 * sigma.log() for sigma in sigmas]).to(accelerator.device)
inp_noisy_latents = noisy_latents / ((sigmas ** 2 + 1) ** 0.5)
mimicmotion进行posenet条件加入
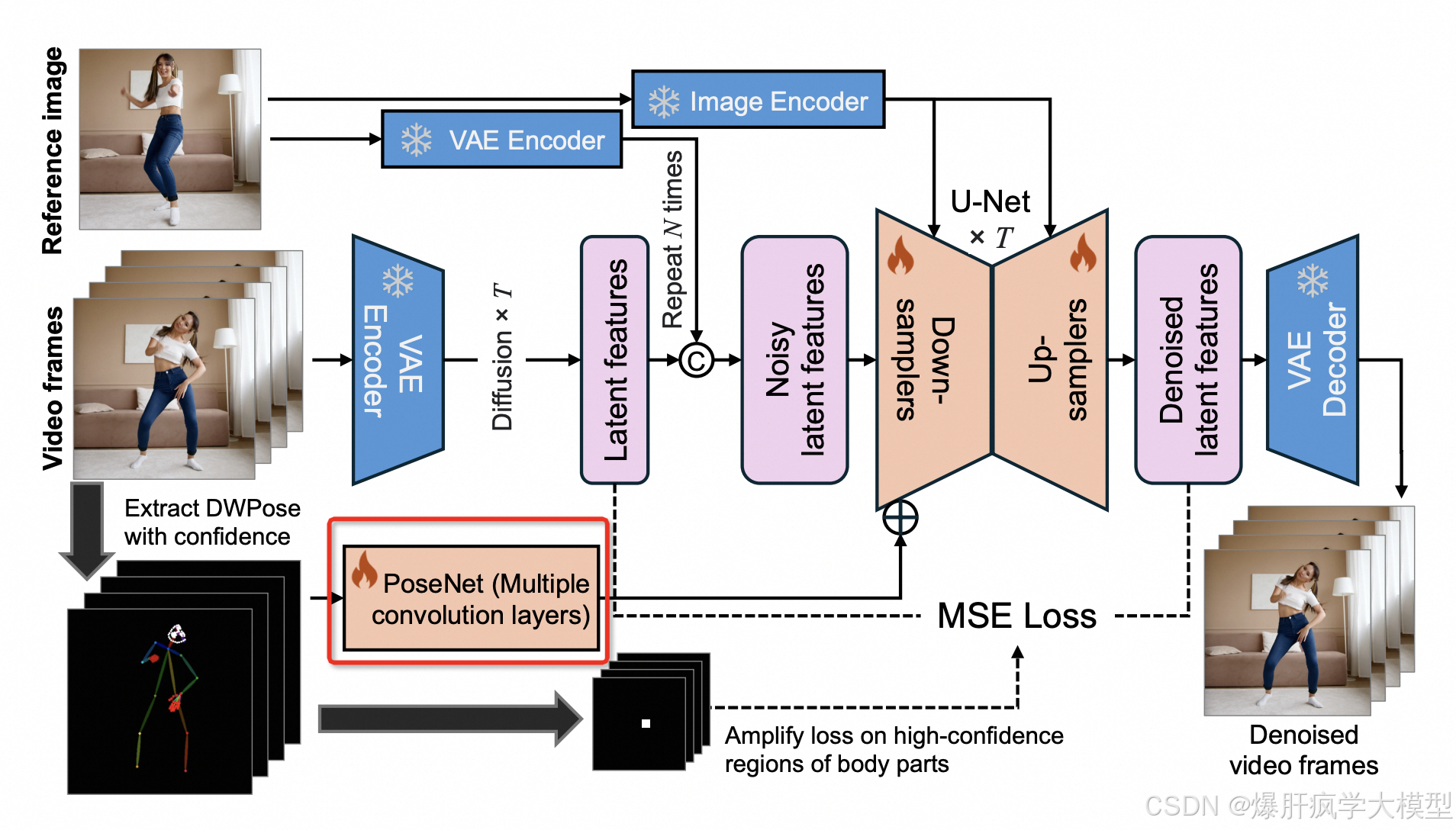
cond_net = PoseNet(noise_latent_channels=unet.config.block_out_channels[0])
# cond net
pixel_values_cond = rearrange(pixel_values_cond, "b f c h w -> (b f) c h w")
pose_latents = cond_net(pixel_values_cond)
pose_latents = rearrange(pose_latents, "(b f) c h w -> b f c h w", b=bsz)
mimicmotion加入unet
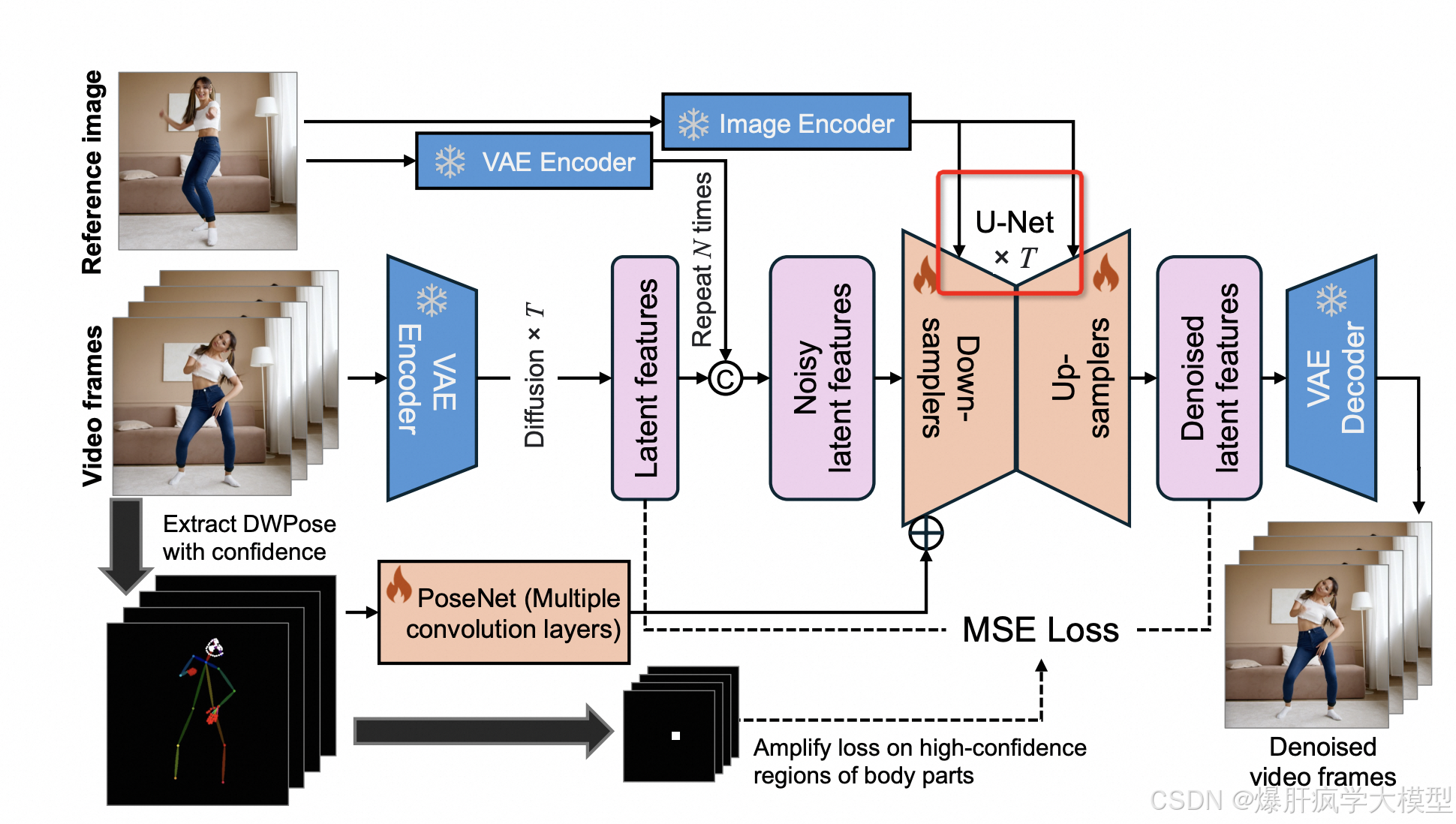
- encoder_hidden_states信息处理(其中一个论文方法,以后有机会再看)
Conditioning dropout to support classifier-free guidance during inference. For more details
check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
# Final text conditioning.
# 创造一个白噪声,target
null_conditioning = torch.zeros_like(encoder_hidden_states)
# 建立一个条件引导,能搞保证图片信息中添加
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
# 其中
prompt_mask.shape # torch.Size([1, 1, 1])
null_conditioning.shape # torch.Size([1, 1, 1024])
encoder_hidden_states.shape # torch.Size([1, 1, 1024])
encoder_hidden_states.shape # torch.Size([1, 1, 1024])
- 聚焦于encoder_hidden_states怎么应用于unet里
先看使用函数
model_pred = unet(
inp_noisy_latents,
timesteps,
encoder_hidden_states,
added_time_ids=added_time_ids,
pose_latents=pose_latents.flatten(0, 1)
).sample
跳转到unet_spatio_temporal_condition_v2.py文件下的UNetSpatioTemporalConditionModel函数中
(1)encoder_hidden_states简单处理数据形式
# 形式转换 encoder_hidden_states: [batch, 1, channels] -> [batch * frames, 1, channels]
# 之前torch.Size([1, 1, 1024])之后torch.Size([8, 1, 1024])
encoder_hidden_states = encoder_hidden_states.repeat_interleave(num_frames, dim=0)
(2)进入下采样downsample_block
for i, downsample_block in enumerate(self.down_blocks):
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
image_only_indicator=image_only_indicator,
)
else:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
image_only_indicator=image_only_indicator,
)
#
len(res_samples) # 3
res_samples[0].shape # torch.Size([8, 320, 120, 72])
sample.shape # torch.Size([8, 320, 60, 36])
解释一点,downsample_block来自self.down_blocks中,如下所示详细展示其来源,
from diffusers.models.unets.unet_3d_blocks import get_down_block
down_block_types: Tuple[str] = (
"CrossAttnDownBlockSpatioTemporal",
"CrossAttnDownBlockSpatioTemporal",
"CrossAttnDownBlockSpatioTemporal",
"DownBlockSpatioTemporal",
)
for i, down_block_type in enumerate(down_block_types):
input_channel = output_channel
output_channel = block_out_channels[i]
is_final_block = i == len(block_out_channels) - 1
down_block = get_down_block(
down_block_type,
num_layers=layers_per_block[i],
transformer_layers_per_block=transformer_layers_per_block[i],
in_channels=input_channel,
out_channels=output_channel,
temb_channels=blocks_time_embed_dim,
add_downsample=not is_final_block,
resnet_eps=1e-5,
cross_attention_dim=cross_attention_dim[i],
num_attention_heads=num_attention_heads[i],
resnet_act_fn="silu",
)
self.down_blocks.append(down_block)
了解downsample_block如何形成后,我们继续深一步探究其内部结构
elif down_block_type == "CrossAttnDownBlockSpatioTemporal":
# added for SDV
if cross_attention_dim is None:
raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlockSpatioTemporal")
return CrossAttnDownBlockSpatioTemporal(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
num_layers=num_layers,
transformer_layers_per_block=transformer_layers_per_block,
add_downsample=add_downsample,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads,
)
CrossAttnDownBlockSpatioTemporal函数在unet_3d_blocks.py中
class CrossAttnDownBlockSpatioTemporal(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
num_layers: int = 1,
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
num_attention_heads: int = 1,
cross_attention_dim: int = 1280,
add_downsample: bool = True,
):
attentions = []
...
for i in range(num_layers):
...
attentions.append(
TransformerSpatioTemporalModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=transformer_layers_per_block[i],
cross_attention_dim=cross_attention_dim,
)
)
...
self.attentions = nn.ModuleList(attentions)
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
image_only_indicator: Optional[torch.Tensor] = None,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
output_states = ()
...
blocks = list(zip(self.resnets, self.attentions))
for resnet, attn in blocks:
...
hidden_states = resnet(
hidden_states,
temb,
image_only_indicator=image_only_indicator,
)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
image_only_indicator=image_only_indicator,
return_dict=False,
)[0]
attn来自blocks,blocks来自self.attentions,self.attentions来自attentions,attentions来自TransformerSpatioTemporalModel,接下来看详解
class TransformerSpatioTemporalModel(nn.Module):
def __init__(
self,
num_attention_heads: int = 16,
attention_head_dim: int = 88,
in_channels: int = 320,
out_channels: Optional[int] = None,
num_layers: int = 1,
cross_attention_dim: Optional[int] = None,
):
# 2. Define input layers
self.in_channels = in_channels
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6)
self.proj_in = nn.Linear(in_channels, inner_dim)
# 3. Define transformers blocks
self.transformer_blocks = nn.ModuleList(
[
BasicTransformerBlock(
inner_dim,
num_attention_heads,
attention_head_dim,
cross_attention_dim=cross_attention_dim,
)
for d in range(num_layers)
]
)
time_mix_inner_dim = inner_dim
self.temporal_transformer_blocks = nn.ModuleList(
[
TemporalBasicTransformerBlock(
inner_dim,
time_mix_inner_dim,
num_attention_heads,
attention_head_dim,
cross_attention_dim=cross_attention_dim,
)
for _ in range(num_layers)
]
)
def forward(
self,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
image_only_indicator: Optional[torch.Tensor] = None,
return_dict: bool = True,
):
# 1. Input
time_context = encoder_hidden_states
time_context_first_timestep = time_context[None, :].reshape(
batch_size, num_frames, -1, time_context.shape[-1]
)[:, 0]
time_context = time_context_first_timestep[None, :].broadcast_to(
height * width, batch_size, 1, time_context.shape[-1]
)
time_context = time_context.reshape(height * width * batch_size, 1, time_context.shape[-1])
...
# 2. Blocks
for block, temporal_block in zip(self.transformer_blocks, self.temporal_transformer_blocks):
hidden_states = block(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
)
hidden_states_mix = hidden_states
hidden_states_mix = hidden_states_mix + emb
hidden_states_mix = temporal_block(
hidden_states_mix,
num_frames=num_frames,
encoder_hidden_states=time_context,
)
encoder_hidden_states来自time_context,time_context来自temporal_block,temporal_block来自self.temporal_transformer_blocks,self.temporal_transformer_blocks来自TemporalBasicTransformerBlock,TemporalBasicTransformerBlock请看详解attention.py
class TemporalBasicTransformerBlock(nn.Module):
def __init__(
self,
dim: int,
time_mix_inner_dim: int,
num_attention_heads: int,
attention_head_dim: int,
cross_attention_dim: Optional[int] = None,
):
# 1. Self-Attn
self.attn1 = Attention(
query_dim=time_mix_inner_dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
cross_attention_dim=None,
)
# 2. Cross-Attn
self.attn2 = Attention(
query_dim=time_mix_inner_dim,
cross_attention_dim=cross_attention_dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
) # is self-attn if encoder_hidden_states is none
def forward(
self,
hidden_states: torch.FloatTensor,
num_frames: int,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
# 0. Self-Attention
norm_hidden_states = self.norm1(hidden_states)
attn_output = self.attn1(norm_hidden_states, encoder_hidden_states=None)
hidden_states = attn_output + hidden_states
# 3. Cross-Attention
if self.attn2 is not None:
norm_hidden_states = self.norm2(hidden_states)
attn_output = self.attn2(norm_hidden_states, encoder_hidden_states=encoder_hidden_states)
hidden_states = attn_output + hidden_states
去看看attention的详解
# 具体到内部的计算
class Attention(nn.Module):
def __init__(
self,
query_dim: int,
cross_attention_dim: Optional[int] = None,
heads: int = 8,
dim_head: int = 64,
dropout: float = 0.0,
bias: bool = False,
upcast_attention: bool = False,
upcast_softmax: bool = False,
cross_attention_norm: Optional[str] = None,
cross_attention_norm_num_groups: int = 32,
added_kv_proj_dim: Optional[int] = None,
norm_num_groups: Optional[int] = None,
spatial_norm_dim: Optional[int] = None,
out_bias: bool = True,
scale_qk: bool = True,
only_cross_attention: bool = False,
eps: float = 1e-5,
rescale_output_factor: float = 1.0,
residual_connection: bool = False,
_from_deprecated_attn_block: bool = False,
processor: Optional["AttnProcessor"] = None,
out_dim: int = None,
):
def forward(
self,
hidden_states: torch.FloatTensor,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
**cross_attention_kwargs,
) -> torch.Tensor:
return self.processor(
self,
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
class AttnProcessor:
r"""
Default processor for performing attention-related computations.
"""
def __call__(
self,
attn: Attention,
hidden_states: torch.FloatTensor,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
temb: Optional[torch.FloatTensor] = None,
*args,
**kwargs,
) -> torch.Tensor:
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
最终得出结论:image encoder是输入到unet的每个block的下面,只要保证最上面能转化为一致的就行。
latent转化为图片
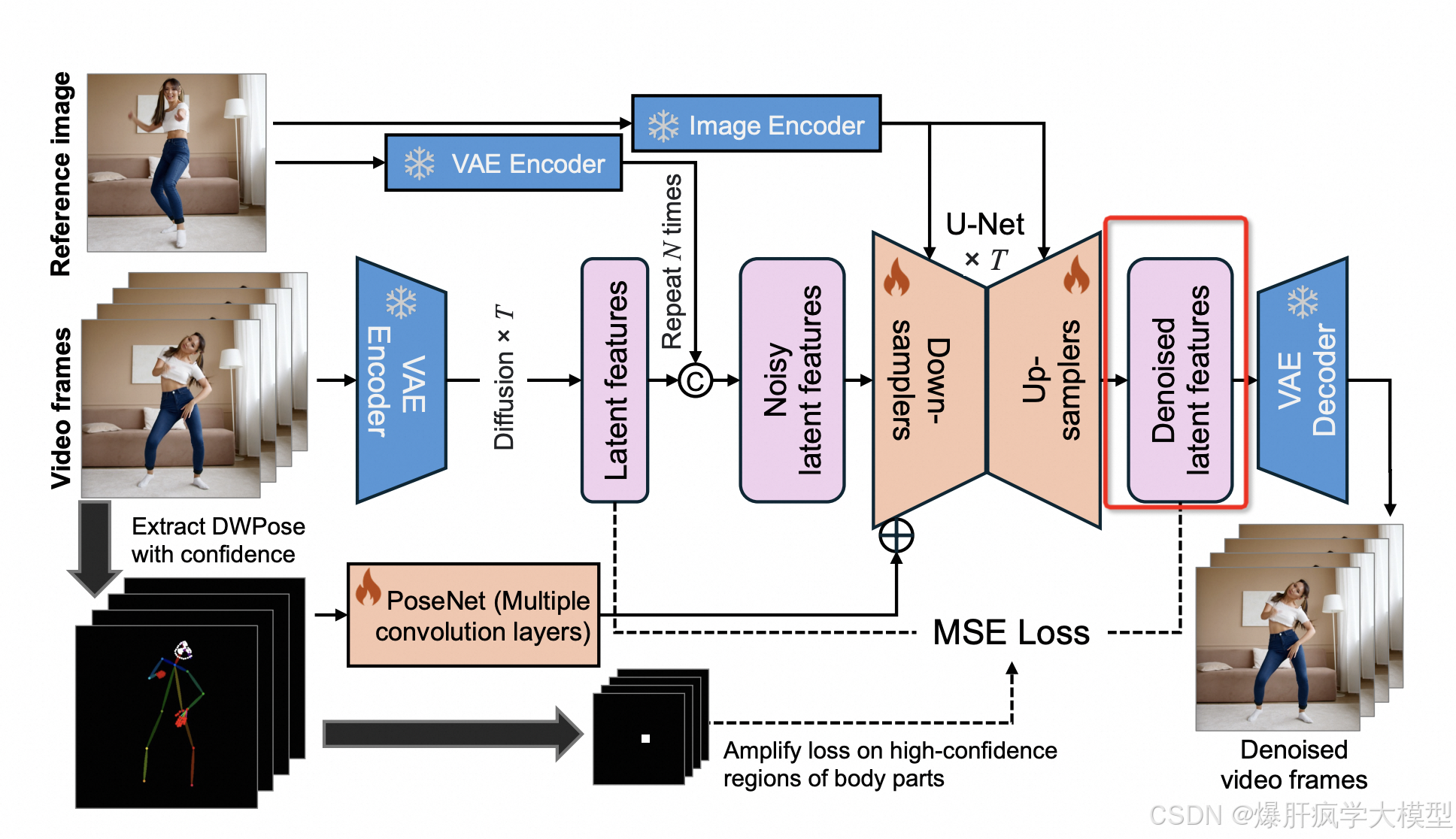
# Denoise the latents
c_out = -sigmas / ((sigmas ** 2 + 1) ** 0.5)
c_skip = 1 / (sigmas ** 2 + 1)
denoised_latents = model_pred * c_out + c_skip * noisy_latents
weighing = (1 + sigmas ** 2) * (sigmas ** -2.0)
mimicmotion进行loss计算
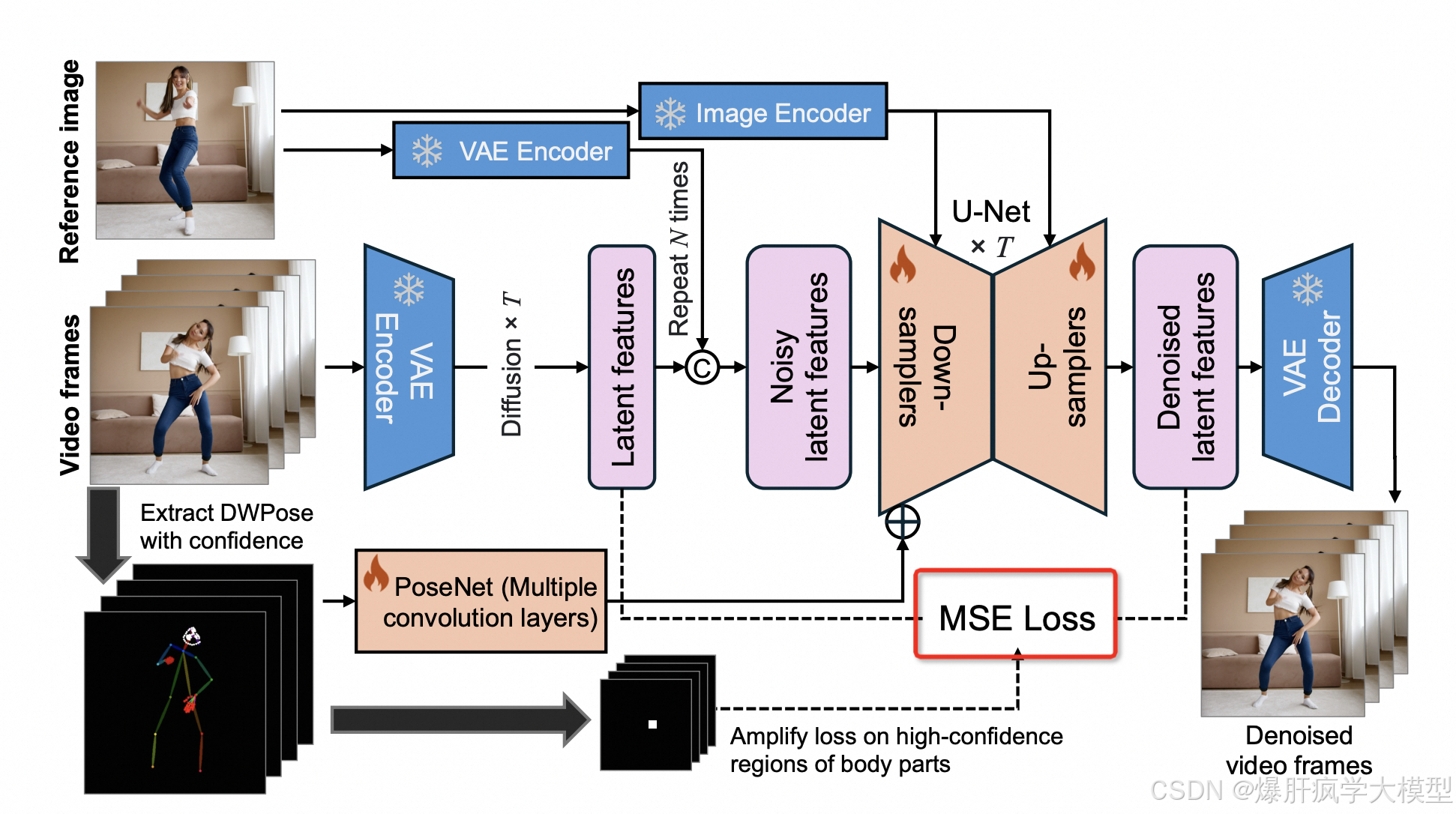
# MSE loss
if "mask_values_cond" in batch:
mask_scale = mask_values_cond.float() * 0.2 + 1.0
else:
mask_scale = torch.ones_like(denoised_latents)
loss = torch.mean(
(weighing.float() * (denoised_latents.float() -
target.float()) ** 2 * mask_scale).reshape(target.shape[0], -1),
dim=1,
).mean()
ema
# ema是一种训练策略
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(unet.parameters(
), model_cls=UNetSpatioTemporalConditionModel, model_config=unet.config)
参考:https://www.cnblogs.com/chester-cs/p/17411578.html
使用xformers进行加速及内存优化
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError(
"xformers is not available. Make sure it is installed correctly")
accelerate的版本下的ema导入及导出
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(
input_dir, "unet_ema"), UNetSpatioTemporalConditionModel)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNetSpatioTemporalConditionModel.from_pretrained(
input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









