






🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据可视化
4.3特征工程
4.4构建模型
4.5模型评估
文末推荐
源代码
1.项目背景
随着工业化和城市化的快速发展,空气污染问题已经成为全球性的挑战。空气中的主要污染物,如PM2.5、PM10、二氧化硫、氮氧化物等,对人类健康和生活质量造成了严重影响。这些污染物不仅会导致呼吸系统疾病、心血管疾病等发病率上升,还会影响农业生产和生态系统平衡。因此,实时监测和预测空气质量对于制定有效的环保政策、保护公众健康以及促进可持续发展具有重要意义。
空气质量数据的收集和分析能够为政府决策、环境保护部门及公众提供科学依据。传统的空气质量预测方法往往需要大量的人力和时间,并且对于实时预测和长期趋势分析的需求无法满足。因此,开发一种准确、高效的空气质量预测模型显得尤为重要。近年来,数据科学与机器学习的发展为空气质量预测提供了新的解决方案。随机森林算法作为一种集成学习算法,通过构建多个决策树并结合这些树的结果来进行分类或回归,能够显著提高预测的准确性和稳定性,减少模型的过拟合现象。它在处理高维数据、特征选择以及并行计算等方面表现出色,被广泛应用于各类机器学习任务。
空气质量的好坏反映了空气污染程度,它是依据空气中污染物浓度的高低来判断的。然而,空气污染是一个复杂的现象,其浓度受到许多因素的影响。人为污染物排放大小是影响空气质量的最主要因素之一,包括车辆、船舶、飞机的尾气排放,工业企业生产排放,居民生活和取暖排放,以及垃圾焚烧等。此外,城市的发展密度、地形地貌、气象条件等也是影响空气质量的重要因素。因此,在构建空气质量预测模型时,需要综合考虑这些影响因素,并选择恰当的模型来描述污染物浓度与解释变量之间的关系。
综上所述,基于随机森林算法的空气质量污染预测模型的研究背景涵盖了空气污染问题的严重性、空气质量数据收集和分析的重要性、传统预测方法的局限性以及随机森林算法在机器学习任务中的优势。这一研究旨在通过数据挖掘技术,利用随机森林算法构建准确、高效的空气质量预测模型,为制定有效的环保政策、保护公众健康以及促进可持续发展提供科学依据。
2.数据集介绍
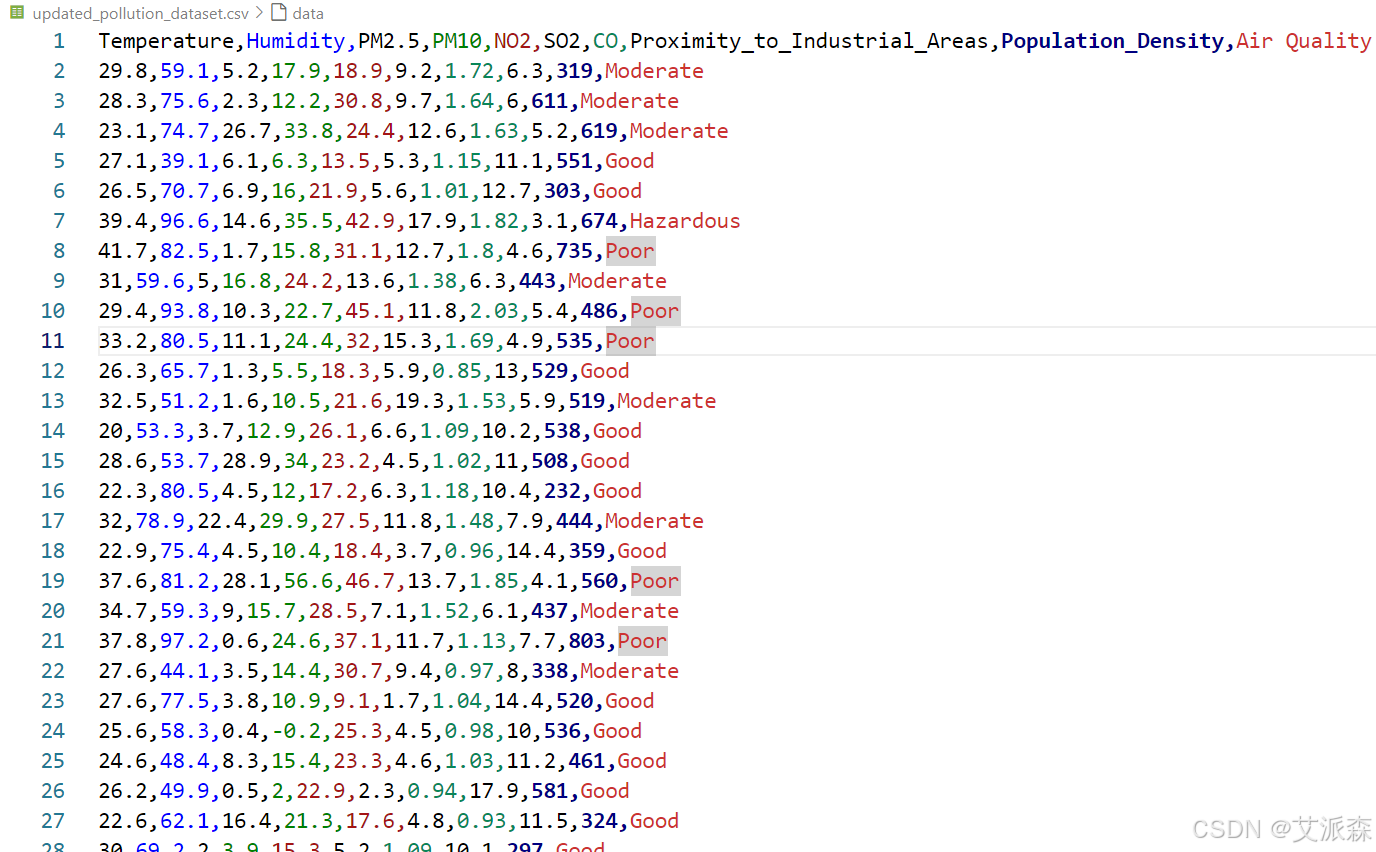
本实验数据集来源于Kaggle,该数据集重点关注各地区的空气质量评估。数据集包含 5000 个样本,并捕获了影响污染水平的关键环境和人口因素。
主要特点:
Temperature(°C):该地区的平均温度。
Humidity(%):该地区记录的相对湿度。
PM2.5 浓度 (µg/m³):细颗粒物水平。
PM10 浓度 (µg/m³):粗颗粒物水平。
NO2 浓度(ppb):二氧化氮水平。
SO2 浓度(ppb):二氧化硫水平。
CO 浓度 (ppm):一氧化碳水平。
Proximity_to_Industrial_Areas(公里):距最近工业区的距离。
Population_Density(人/平方公里):该地区每平方公里的人口数量。
目标变量:Air Quality
优点:空气清新,污染程度低。
中等:空气质量可接受,但存在一些污染物。
差:污染明显,可能对敏感人群造成健康问题。
危险:高度污染的空气对民众的健康造成严重的威胁。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载数据集
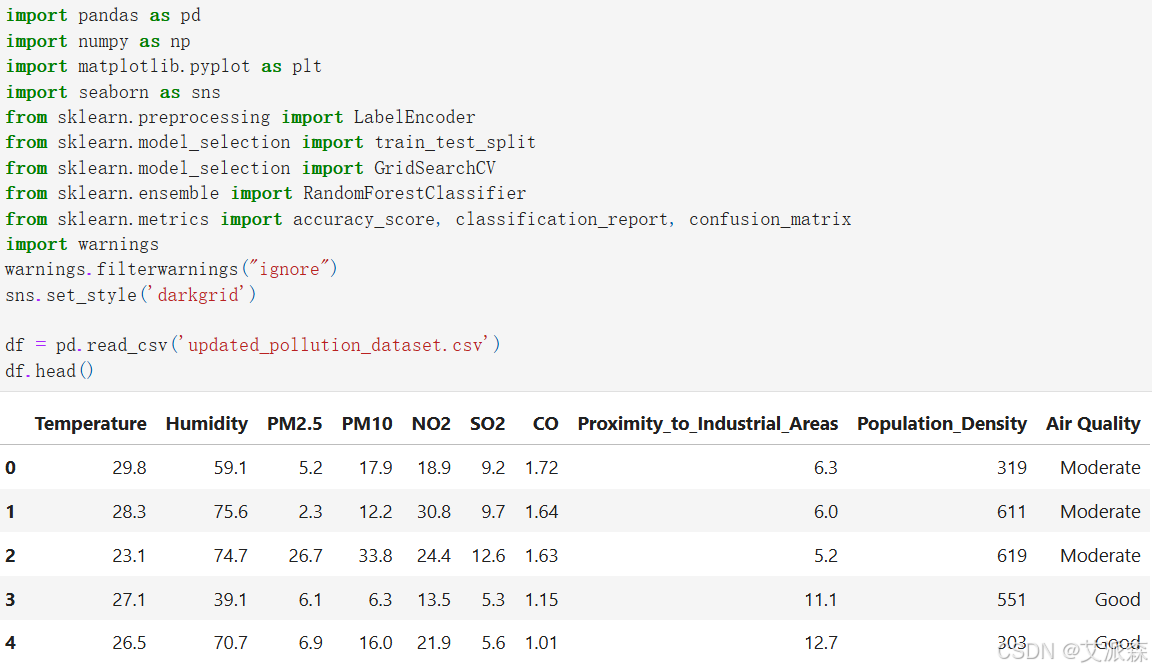
查看数据大小
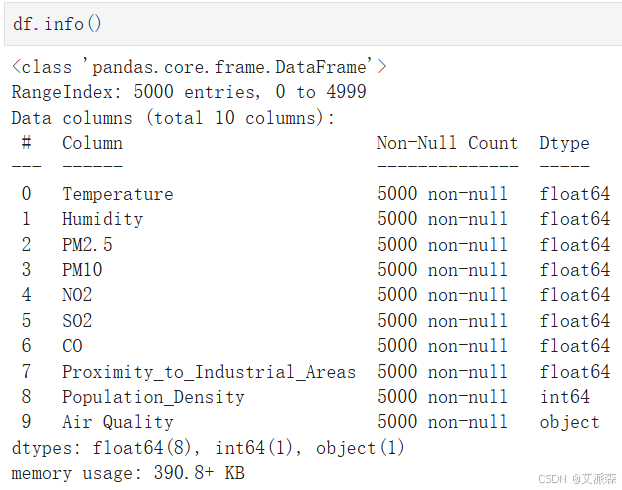
查看数据基本信息
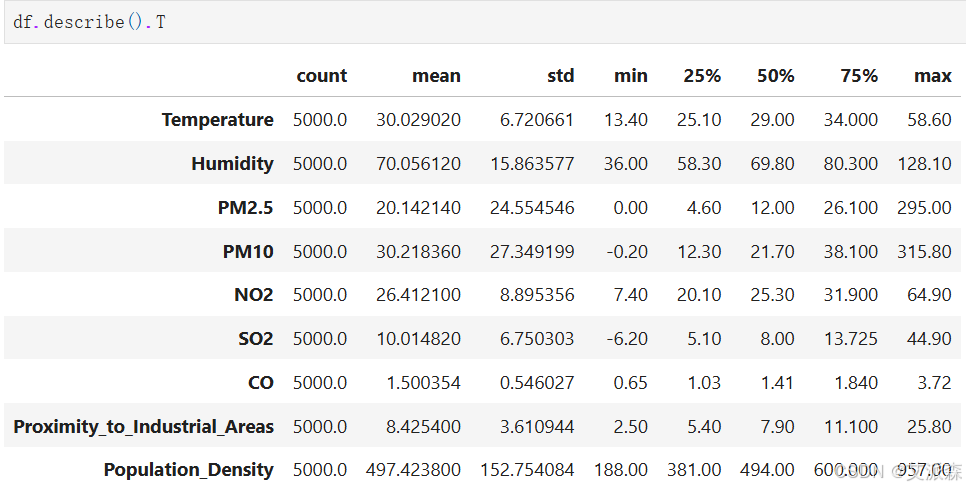
查看数据描述性统计
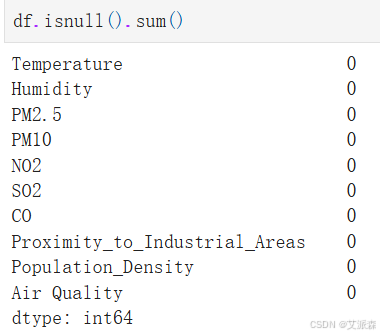
统计缺失值
统计重复值
发现并没有缺失值和重复值,不需要处理
4.2数据可视化

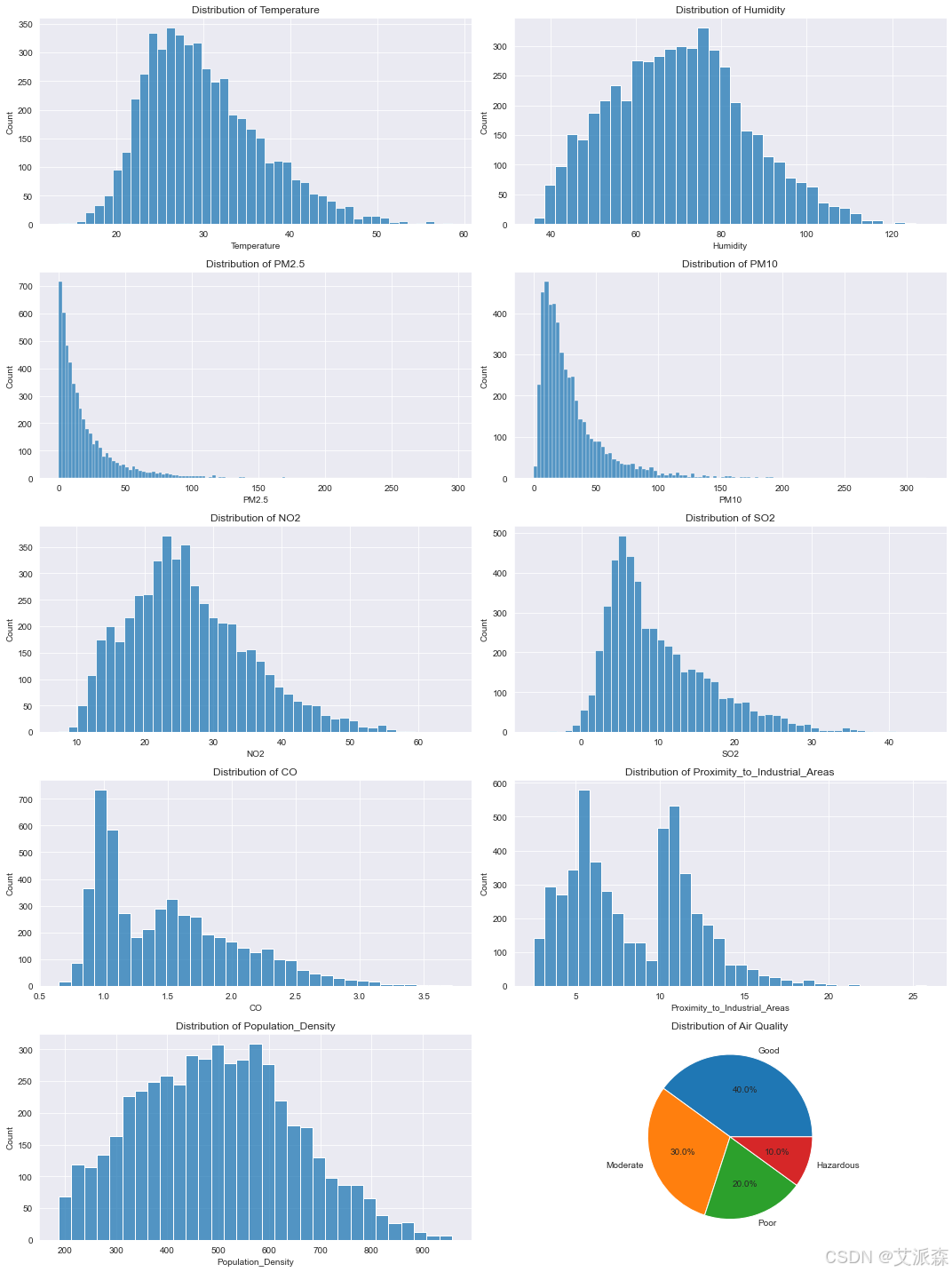

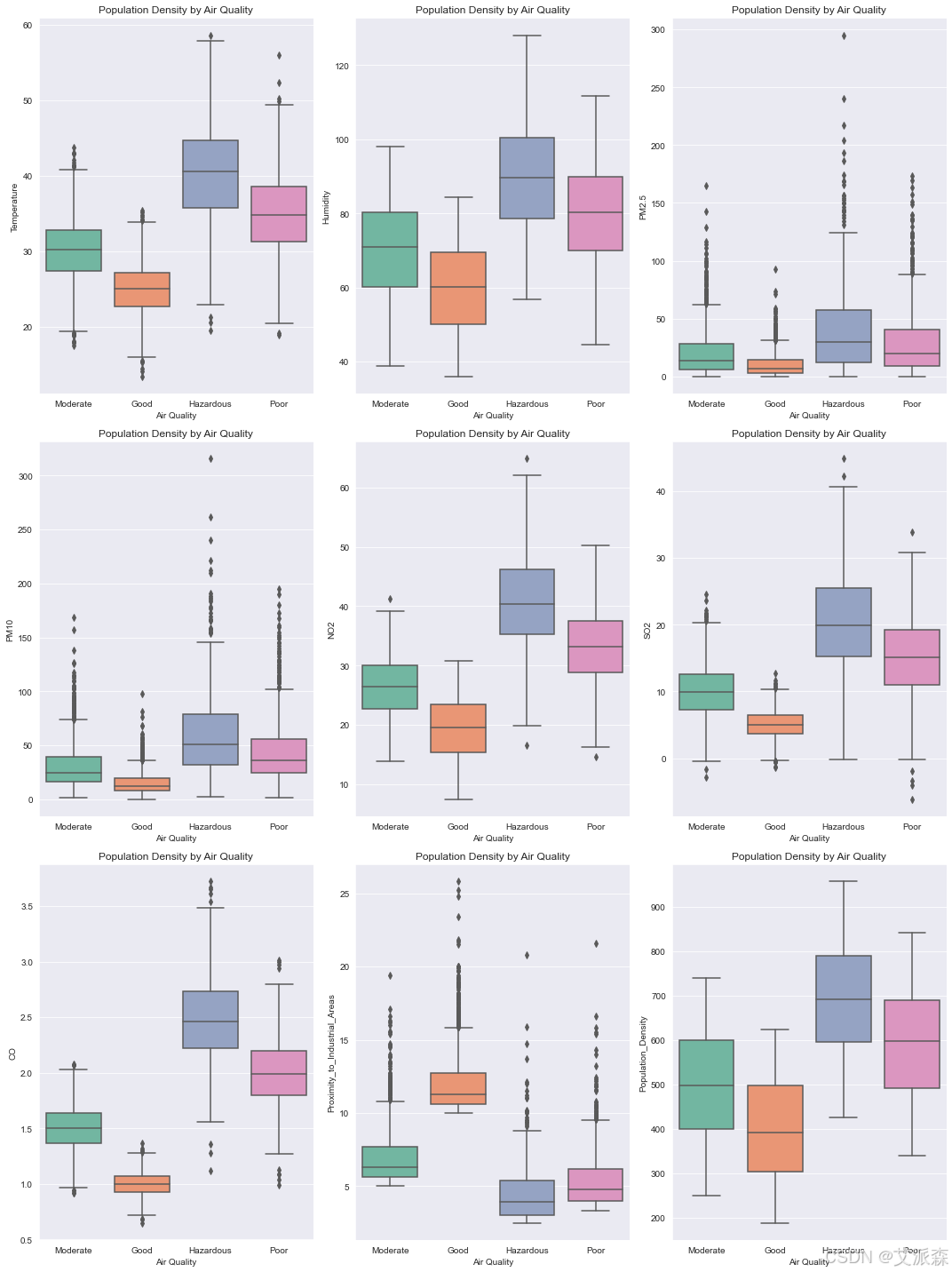
4.3特征工程
对目标变量进行编码处理
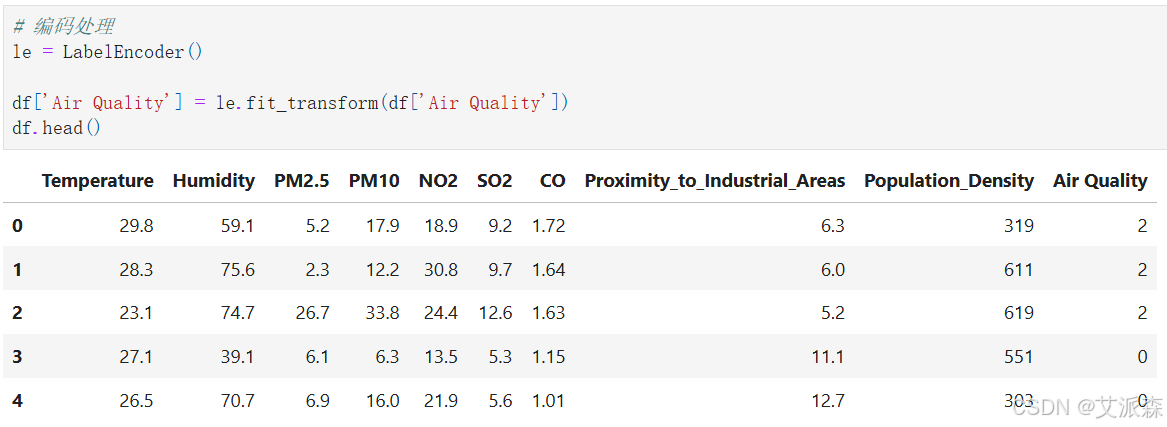

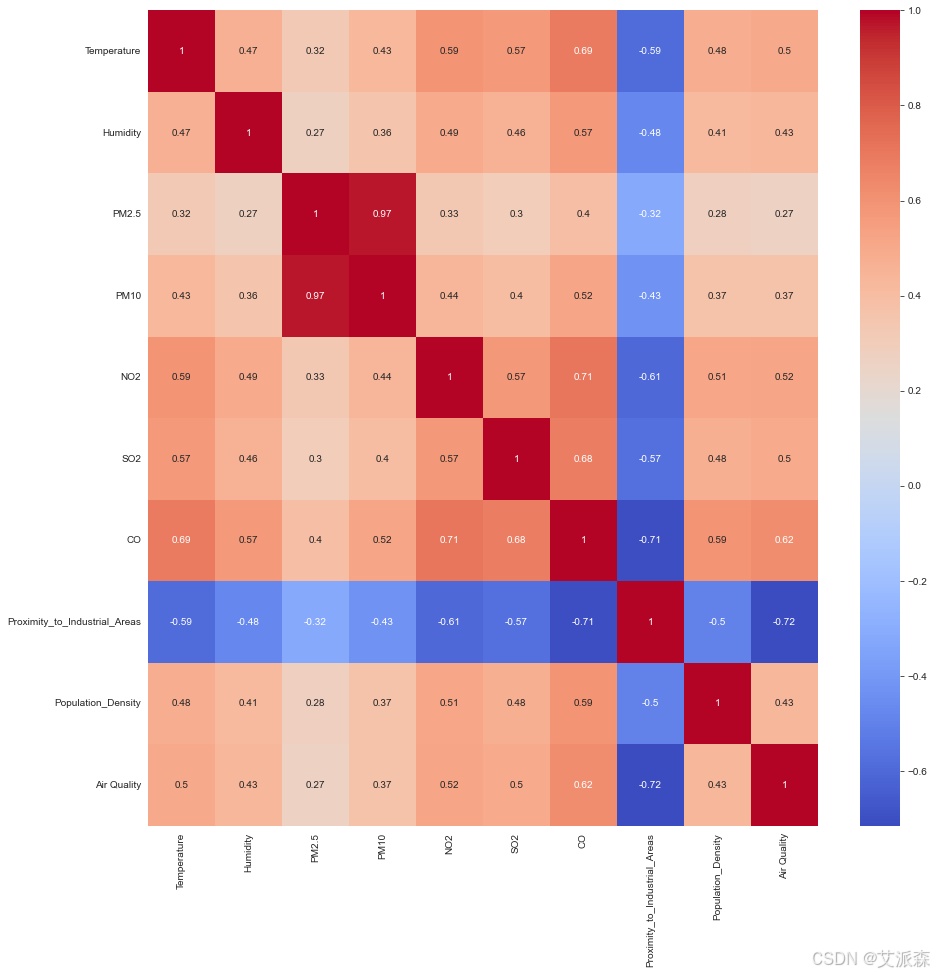

4.4构建模型
构建随机森林模型,并使用网格搜索找出模型的最佳参数

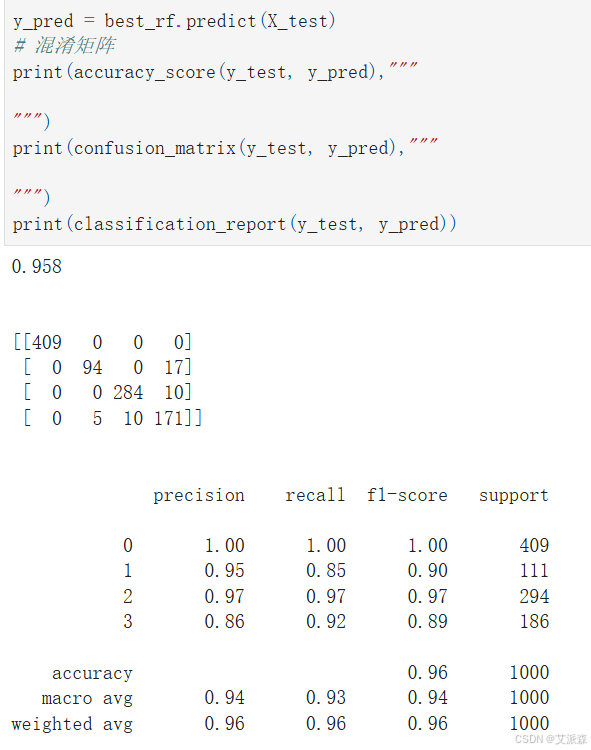
可以看出模型在测试集上的准确率为0.9580
4.5模型评估
打印混淆矩阵和分类报告
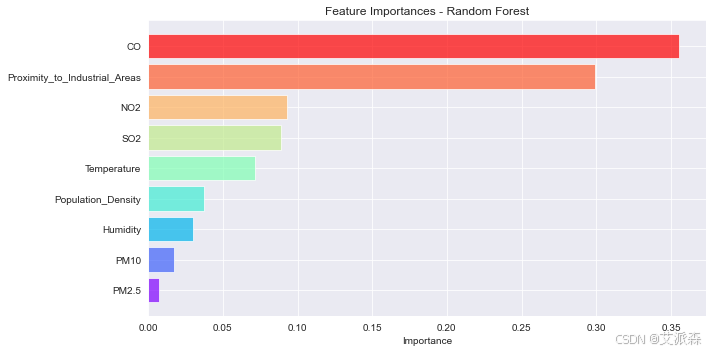
特征重要性
文末推荐
《硬件十万个为什么(电源是怎样炼成的)》

内容简介
本书聚焦于DC/DC电源领域,涵盖了国产化芯片的应用范例。全书分为四个部分,每个部分都深入探讨了电源领域的关键主题。首先,从电源的概念出发,介绍了稳压电源的发展历史、电源的分类及各种电源的基本原理;其次,详细讲解了开关电源的各种拓扑结构,深入研究了基本原理与设计;然后,通过数学基础讲解、电路分析,详细讨论了闭环稳定性评判标准和环路补偿电路的应用;最后,结合实际设计过程探讨了电源的工程问题,包含有关电源完整性、DC/DC的EMI优化及电源的测试和新技术的内容。
本书从基础知识到高级技术,不仅详细介绍了电源技术的理论知识,还结合实例分析,帮助读者深入理解电源设计的方法,为实际工程应用提供了全面而深入的指导。
通过这本书,硬件工程师可以系统地学习和理解DC/DC电源的各个方面,并能应用到实际中。非常适合电子工程、自动化控制等相关专业的师生及工程技术人员阅读,无论是电源技术的初学者还是专业人士,都能从中获得宝贵的知识和经验。
《掌握Revit与BIM,一书在手轻松入门》

内容简介
本书从Revit基础操作入手,结合真实工程案例,全面解析BIM技术应用。从规划体量到出图,详尽介绍建筑设计全过程。案例源于实战,步骤清晰,语言易懂,实用性强。无论是院校师生、爱好者自学,还是建筑设计行业用户,都能从中受益,实现BIM技术从入门到精通。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









