






前言
今天给大家介绍一篇音乐生成文本的paper,具体的是生成描述当前这个音乐的文本,同时还可以学一下其中作者设计的一个对比学习,笔者也贴了一下自己对其基本的代码实现,感兴趣的小伙伴可以收藏一下~
论文链接:https://arxiv.org/pdf/2210.00434.pdf
硬广
哈哈,在开始之前,如果有小伙伴对多模态感兴趣,笔者之前也写过几篇,大家感兴趣也可以看看,不过都是关于图文的:
https://zhuanlan.zhihu.com/p/435697429
https://zhuanlan.zhihu.com/p/453581899
https://zhuanlan.zhihu.com/p/454314421
https://zhuanlan.zhihu.com/p/570332906
数据集
为啥要做这个任务呢?作者也是给了一些case如下:
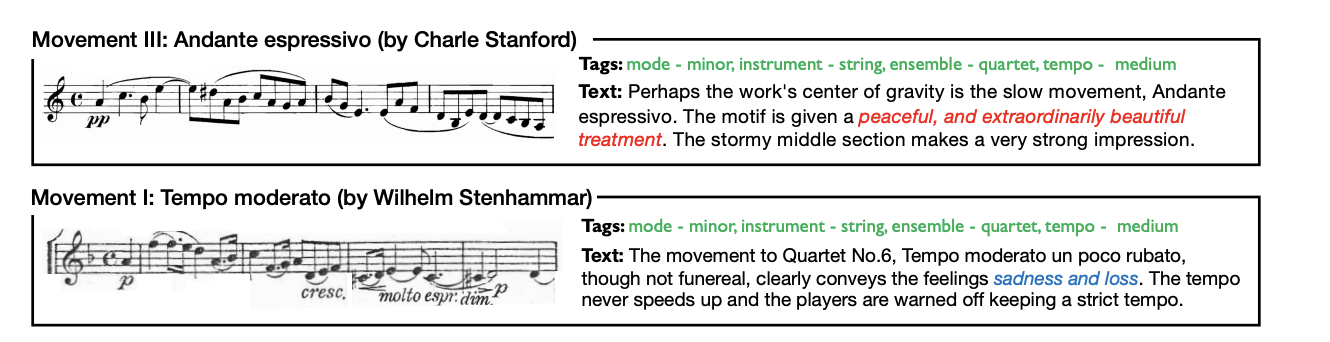
可以看到这里列出了两首乐章,以往的工作基本上都是对音乐进行分类,比如上图中的Tags,两首乐章的Tags是相同的,但是实际上两首乐章的风格其实有比较大的区别的,一首是比较优美的(peaceful, and extraordinarily beautiful treatment),而另外一首是比较悲伤的(sadness and loss),为此作者认为有必要做这项研究。
由于这个任务比较新,之前没有相关的工作做过,也就没有相关的公开标注数据集拿来训练,于是作者第一步就是需要构建数据集。
其实最主要的就是构建music-text pairs,作者选择爬取数据的网站是:https://www.earsense.org/,数据集中的95%的音乐时长是2.5min到14min不等,对应的描述性文本长度是14到192不等,最后共收集到了2380个文本,其中1955个有对应的音乐。
模型
可以看到这个任务其实是一个跨模态生成任务:
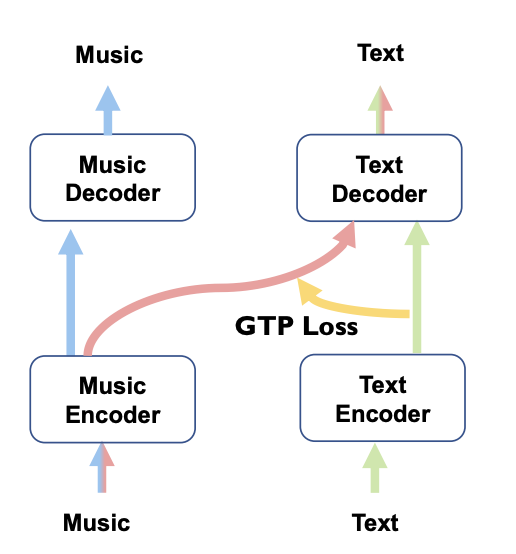
具体做的都也很常规,不过值得看一下的是paper中说的一个对比学习: Group Topology-Preservation Loss (GTP Loss)。
首先需要encoder和对应的decoder来分别对music和text提取特征和重建,具体的作者分别选用的是CNN和transformer。
所以各个模态编码解码对应两个loss如下,公式(1)是音频模态,公式(2)是文本模态:


接下来就是一个跨模态对齐loss:

可以看到也很简单,就是直接加一层MLP映射,然后求L2距离即可。
说完了上面常见的,作者重点讲述了一下自己提出的创新点即paper中所说的的GTP Loss:

作者讲了很多理论和故事来阐述这个设计,这里笔者不想按部就班的讲作者的故事,而是通过一个例子来阐述一下:
假设当前batch=4,那么对应的输入数据中文本假设是[a,b,c,d],音乐是[e,f,g,h],也就是说文本a是音乐e的描述性语言,同理b和f、c和g、d和h分别是对应的pair。
假设a和b、c、d相似度(sfotmax后的)分别是0.2、0.6、0.2;假设e和f、g、h相似度(sfotmax后的)分别是0.1、0.7、0.3
好,到这里最重要的一个对比学习思想来了:
a和b、c、d相似度分布应该尽可能与e和f、g、h相似度相似,换句话说:[0.2、0.6、0.2]和[0.1、0.7、0.3]尽可能的相似。
同理b和a、c、d相似度分布应该尽可能与f和e、g、h相似度相似,以此类推。
看到这里相信大家也比较明白了,其实就是个对比学习,不过相比于作者设计的这个对比学习,还有一个设计方式其实更容易想到,那就是:
a和e的相似度要大于a和f、g、h相似度,同理b和f的相似度要大于b和e、g、h相似度。
同时作者这里也借鉴目前对比学习的代码,分别实现一下上述两个对比学习loss(pytorch版本的),大家有兴趣也可以在自己的工作中加个对比学习loss试一下
wai_user_embedding和nei_user_embedding可以看成是两个模态的emb(对应到本篇就是音乐和文本的表征),维度都是[batch, hidden_size],这里笔者在量化分布相似的时候用的是KL散度,没用作者所说的L2,大家都可以改着试试。
def GroupTopologyPreservationLoss(self, wai_user_embedding, nei_user_embedding):
wai_user_embedding_similarity = F.cosine_similarity(wai_user_embedding.unsqueeze(1), wai_user_embedding.unsqueeze(0), dim=-1)
nei_user_embedding_similarity = F.cosine_similarity(nei_user_embedding.unsqueeze(1), nei_user_embedding.unsqueeze(0), dim=-1)
n = wai_user_embedding_similarity.size()[0]
wai_user_embedding_similarity = wai_user_embedding_similarity.flatten()[:-1].view(n-1,n+1)[:,1:].flatten().view(n, n-1)
nei_user_embedding_similarity = nei_user_embedding_similarity.flatten()[:-1].view(n-1,n+1)[:,1:].flatten().view(n, n-1)
kl_wai_nei = F.kl_div(F.log_softmax(wai_user_embedding_similarity, dim=-1), F.softmax(nei_user_embedding_similarity, dim=-1), reduction='sum')
kl_nei_wai = F.kl_div(F.log_softmax(nei_user_embedding_similarity, dim=-1), F.softmax(wai_user_embedding_similarity, dim=-1), reduction='sum')
loss = (kl_wai_nei+kl_nei_wai)/2
return loss
另外一种就是笔者所说的第二种常见的,大家可以看一下这里https://blog.csdn.net/weixin_44966641/article/details/120382198
不过需要说明的是,上述链接中预先定义了一个negatives_mask buff,其大小是固定的,但是有的时候我们的代码在跑的时候,最后一个batch有可能不够预设的大小即我们的样本总数是102,每个batch假设是25,那么最后一个batch其实是2,这个时候在用这个negatives_mask buff计算loss的时候就会出错,那怎么办呢?很简单我们多加两行代码:
def contrastiveLoss(self, emb_i, emb_j):
temp_batch_size = emb_i.size()[0]
negatives_mask = self.negatives_mask[:temp_batch_size*2, :temp_batch_size*2]
...
可以看到是为了适配当前传进来embedding的大小。
看到这里,笔者就再多说一句吧,有的时候我们处理的不是多模态,假设是文本和文本之间的对比学习,最后我们还是想得到类似emb_i, emb_j两个矩阵来进行对比学习,那这两个emb怎么得到呢?要过两次模型(比如bert模型)吗?其实很简单,只需要在bert模型输入的时候将两部分样本进行cat成一批,然后输进去,在输出的时候再按顺序拿到对应的emb即可,只不过为了加对比学习,总体可跑的batch可能就要减半了。
总结
(1)今天给大家介绍了一个很好玩的研究方向,其实还可以反过来,根据文本生成bgm,这个感觉更有意思。
(2)介绍了点对比学习和代码,希望对大家有用。
关注
欢迎关注,下期再见啦~
本文由 mdnice 多平台发布

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









