






一、 预训练过程:
模型首先在大量无标注的文本数据上进行预训练,学习语言的基本规律和知识,如词汇的语义、语法结构、上下文关系等。
预训练通常包括两个主要任务:语言建模(Language Modeling, LM)和遮蔽语言建模(Masked Language Modeling, MLM)。在LM中,模型学习根据前文预测下一个词;在MLM中,模型学习根据上下文恢复被随机遮蔽的词。
二、 模型微调
1.数据预处理
1.1 收集数据:
数据源:从客服系统中导出历史对话数据,包括用户提问和客服回答。
数据量:确保数据量足够大,以覆盖各种可能的用户查询和场景,我们训练的数据大概在1000万条左右。
1.2 数据清洗:
去噪:移除包含错误、无关或重复信息的对话。
预处理:进行文本清洗,如去除HTML标签、特殊字符、多余空格等。
分词与编码:根据中文特性进行分词处理,并将文本转换为模型可理解的编码格式(如Token ID)。
1.3 数据标注
因为模型需要处理特定类型的任务(如情感分析、意图识别等),则需要对数据进行标注。
例如:(标注悲观情绪,后续模型生成降低悲观数据的优先级等等)
1.4 数据划分
将清洗后的数据划分为训练集、验证集和测试集。通常,训练集占大部分(如80%),验证集和测试集各占一小部分(如10%)。
模型调整
- 加载预训练模型:使用PyTorch等框架加载ChatGLM-4的预训练权重。
- 定义微调任务:设置微调任务为对话生成,即根据用户输入生成相应的回复。
- 修改模型结构(可选):根据任务需求,可能需要对模型结构进行微调,如添加或修改某些层。但在此案例中,我们主要关注微调模型参数。
- 设置训练参数:包括学习率、批处理大小、训练轮次、优化器等。
- 编写训练脚本:编写Python脚本来加载数据、定义模型、设置训练参数,并启动训练过程。
- 训练模型:使用训练集数据对模型进行训练,同时监控验证集上的表现以调整超参数并防止过拟合。
- 保存模型:在训练过程中定期保存模型权重,以便后续评估和部署。
3. 模型评估与调优
1. 评估模型
使用测试集数据评估微调后的模型性能,评估指标可以包括生成文本的流畅性、相关性、准确性等。
采用人工评估和自动评估(如BLEU、ROUGE等)相结合的方式进行模型评估。
2. 调优模型
根据评估结果调整模型结构、训练参数或数据预处理方式等,以进一步提升模型性能。
三、 文本生成过程:
在文本生成阶段,模型接收一个输入文本(如用户提问或对话历史)作为条件。
模型利用预训练学到的知识和微调过程中学到的特定任务知识,对输入文本进行编码,生成一个内部表示(通常是一系列的向量)。
然后,模型根据这个内部表示进行解码,逐步生成输出文本(如回复)。解码过程可能涉及多种技术,如贪心搜索、束搜索(Beam Search)或采样(Sampling),以平衡生成文本的多样性和质量。
四、模型对话原理
- 输入处理:
对话系统首先接收用户的输入文本,并进行必要的预处理,如文本清洗、分词、编码等。
- 上下文管理:
对话系统维护一个上下文状态,用于记录当前对话的历史信息。这有助于模型理解用户输入的上下文背景,从而生成更加准确和连贯的回复。
- 模型推理:
将预处理后的用户输入和当前上下文状态作为条件输入到预训练或微调后的对话模型中。
模型根据输入和上下文进行推理,生成一个或多个候选回复。
- 回复选择/生成:
在某些情况下,对话系统可能从多个候选回复中选择一个最合适的回复返回给用户。这可以通过排名、打分或其他策略来实现。
在其他情况下,对话系统可能直接生成一个回复文本并返回给用户。
- 反馈循环:
用户收到回复后,可能会继续输入新的文本进行下一轮对话。这样,对话系统就形成了一个持续的反馈循环,不断与用户进行交互。
五、 Transformer模型结构
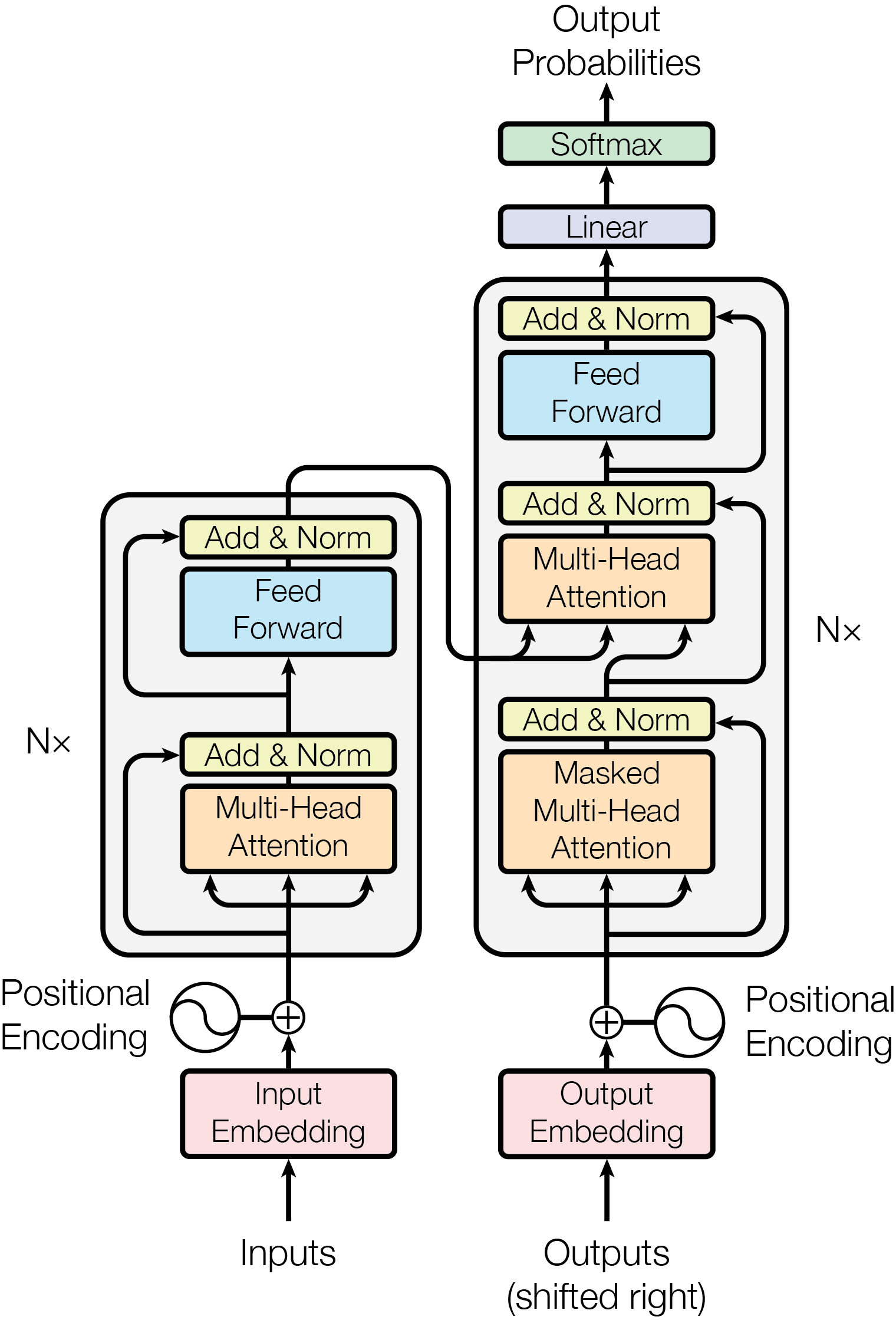
以下是该模型结构的中文描述:
输入编码器(Input Encoding):
首先,输入的文本(或其他类型的数据)被转换为嵌入向量。嵌入层的作用是将输入的离散数据(如单词)转换为连续的向量表示,以便神经网络可以处理。
位置编码(Positional Encoding):
在Transformer模型中,由于自注意力机制本身不考虑序列中元素的顺序,因此需要额外的位置信息来指示每个元素在序列中的位置。这张图中没有明确画出位置编码与输入编码的结合,但通常在Transformer的实践中,位置编码会被加到嵌入向量上。
多头注意力(Multi-Head Attention):
多头注意力是Transformer模型的核心组件之一。它将输入分为多个“头”,每个头独立地执行自注意力操作,然后将结果拼接起来。这样做可以允许模型在不同的表示子空间中同时关注输入的不同部分。
添加与归一化(Add & Norm):
在多头注意力之前和之后,都会进行添加与归一化操作。这通常指的是残差连接(将输入直接加到输出上)和层归一化(对层的输出进行归一化,以保持数值的稳定性)。
前馈网络(Feed Forward):
在多头注意力之后,模型通过一个全连接的前馈网络进行进一步的处理。这个前馈网络通常包括两个线性变换和一个激活函数(如ReLU)。
输出解码器(Output Decoding)
在Transformer模型中的作用是负责生成输出序列。它是Transformer架构中不可或缺的一部分
线性变换(Linear):
紧接着,这些嵌入向量通过一个线性层进行变换,这通常是为了调整向量的维度或进行初步的特征提取。
输出概率(Output Probabilities):
在前馈网络之后,模型通常会通过一个线性层和Softmax函数来生成输出概率。这些输出概率表示了模型对于每个可能输出的预测置信度。
输出(Outputs):
最后,模型输出可能是对输入序列的某种表示,或者是在特定任务(如语言翻译、文本分类等)上的预测结果。















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









