







文章目录
论文画图必备网址:
#画图:https://cbovar.github.io/ConvNetDraw/
搭建网络的步骤
搭建网络class
1、六步法
1)import——导入所需的各种库和包
2)x_train, y_train——导入数据集、自制数据集、数据增强
3)class MyModel(Model) model=MyModel——定义模型
4)model.compile——配置模型
5)model.fit——训练模型、断点续训
6)model.summary——参数提取、acc/loss 可视化、前向推理实现应用
2、用class类封装神经网络函数
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
定义网络结构块
def call(self, x):
调用网络结构块,实现前向传播
return y
#实例化出model
model=MyModel()
init()函数准备搭建网络所需的“积木”
call()函数调用init()中搭好的积木
3、示例
用class为鸢尾花分类
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()
搭建网络sequential
1、六步法
1)import——导入所需的各种库和包
2)x_train, y_train——导入数据集、自制数据集、数据增强
3)model=tf.keras.models.Sequential
4)model.compile——配置模型
5)model.fit——训练模型、断点续训
6)model.summary——参数提取、acc/loss 可视化、前向推理实现应用
2、compile()配置神经网络的训练方法
model.compile(optimizer='优化器',
loss='损失函数',
metrics=['准确率']
)
Optimizer可选:
“sgd” 或者 tf.optimizers.SGD(lr = 学习率,decay = 学习率衰减率,momentum = 动量参数)
“adagrad" 或者 tf.keras.optimizers.Adagrad(lr = 学习率,decay = 学习率衰减率)
”adadelta" 或者 tf.keras.optimizers.Adadelta(lr = 学习率, decay = 学习率衰减率)
“adam" 或者 tf.keras.optimizers.Adam(lr = 学习率,decay = 学习率衰减率)
loss可选:
”mse" 或者 tf.keras.losses.MeanSquaredError()
“sparse_categorical_crossentropy” 或者 tf.keras.losses.SparseCatagoricalCrossentropy(from_logits = False)
***注:损失函数经常需要使用softmax函数来将输出转化为概率分布的形式,在这里from_logits代表是否将输出转为概率分布的形式,为False时表示转换为概率分布,为True时表示不转换,直接输出(即:网络用了’softmax‘则from_logits = False,反之使用True)***。
metrics可选:
“accuracy” : y_ 和 y 都是数值,如y_ = [1] y = [1] #y_为真实值,y为预测值
“sparse_accuracy":y_ 和y都是以独热码 和概率分布表示,如y_ = [0, 1, 0], y = [0.256, 0.695, 0.048]
“sparse_categorical_accuracy” :y_ 是以数值形式给出,y是以独热码给出,如y_ = [1], y = [0.256 0.695, 0.048]
注:使用了’softmax’,输出会变成独热码形式
3、fit()执行训练过程
model.fit(训练集输入,训练集标签,batch_size= , epochs= ,
validation_data=(测试集输入,测试集标签),
validation_split=从训练集划分多少比例给测试集,
validation_freq=1)
4、tf描述卷积层
keras.layers.Conv2D(filters=卷积核个数,kernel_size=卷积核尺寸,strides=滑动步长(默认为1),padding='same' or 'valid',activation='relu' or 'sigmoid' or 'tanh' or 'softmax',input_shape=(高,宽,通道数))
注意:如果卷积后面有批标准化操作(keras.layers.BatchNormalization),这里不用激活,不写激活函数。
完整代码
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
import tensorflow as tf
from tensorflow.keras import datasets, layers, Model, optimizers
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
import matplotlib.pyplot as plt
import json
import pickle
import numpy as np
from tensorflow import keras
import random
import pathlib
import cv2
from skimage import io,transform
import glob
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 忽略低级别警告
class_num=10 #分类数
image_path = '.\\dataset\\dataset'
train_dir = os.path.join(image_path, "train")
validation_dir = os.path.join(image_path, "val")
assert os.path.exists(train_dir), "cannot find {}".format(train_dir)
assert os.path.exists(validation_dir), "cannot find {}".format(validation_dir)
# create direction for saving weights
'''if not os.path.exists("save_weights"):
os.makedirs("save_weights")
'''
im_height = 64
im_width = 64
batch_size = 16
epochs = 10
# data generator with data augmentation
#lable is one-hot coding
train_image_generator = ImageDataGenerator(rescale=1. / 255,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1. / 255)
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,
batch_size=batch_size,
shuffle=True,
target_size=(im_height, im_width),
class_mode='categorical')
total_train = train_data_gen.n
# get class dict
class_indices = train_data_gen.class_indices
# transform value and key of dict
inverse_dict = dict((val, key) for key, val in class_indices.items())
# write dict into json file
json_str = json.dumps(inverse_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,
batch_size=batch_size,
shuffle=False,
target_size=(im_height, im_width),
class_mode='categorical')
total_val = val_data_gen.n
print("using {} images for training, {} images for validation.".format(total_train,
total_val))
##############################################
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(class_num, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
# 配置训练学习过程,设置损失函数,优化器和训练指标
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=["accuracy"])
'''
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
'''
#断点继训
if os.path.exists('./logs/models.ckpt' + '.index'):
print('-------------load the model-----------------')
model.load_weights('./logs/models.ckpt')
##保存训练过程
logdir = os.path.join('logs')#win10下的bug,
if not os.path.exists(logdir):
os.makedirs(logdir)
output_model_file = os.path.join(logdir,'models.ckpt')
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file, monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=True, mode='auto', period=1),
#keras.callbacks.EarlyStopping(patience=5,min_delta=1e-3)
]
'''
output_model_file: 字符串,保存模型的路径。
monitor: 被监测的数据。val_acc或这val_loss
verbose: 详细信息模式,0 或者 1 。0为不打印输出信息,1打印
save_best_only: 如果 save_best_only=True, 将只保存在验证集上性能最好的模型
mode: {auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。 在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。
period: 每个检查点之间的间隔(训练轮数)。
'''
history = model.fit(x=train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=callbacks)
model.summary()
'''
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
'''
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
test_loss, test_acc = model.evaluate(val_data_gen, verbose=2)
print(test_acc)
# 模型保存
save_path = "垃圾分类_model.h5"
model.save(save_path)
备注:运行前先用脚本把图片分为测试集和验证集
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
origin_flower_path = "photos"
assert os.path.exists(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
data_root = os.path.join(cwd, "dataset")
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
单张图片预测
import os
import json
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from model import AlexNet_v1, AlexNet_v2
def main():
im_height = 64
im_width = 64
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# resize image to 64x64
img = img.resize((im_width, im_height))
plt.imshow(img)
# scaling pixel value to (0-1)
img = np.array(img) / 255.
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img, 0))
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = AlexNet_v1(num_classes=5)
weighs_path = "./save_weights/myAlex.h5"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(weighs_path)
model.load_weights(weighs_path)
# prediction
result = np.squeeze(model.predict(img))
predict_class = np.argmax(result)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_class)],
result[predict_class])
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
常见的网络
LeNet
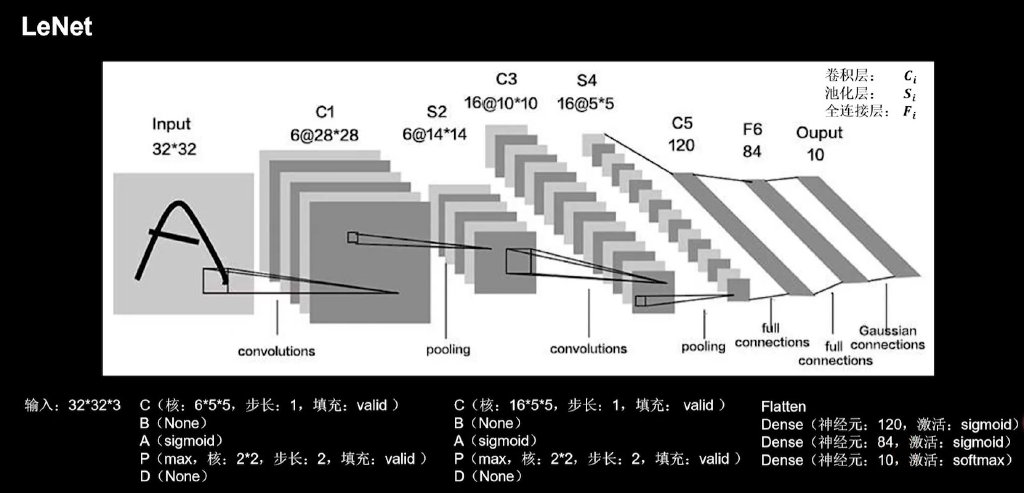
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5),
activation='sigmoid')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.f1 = Dense(120, activation='sigmoid')
self.f2 = Dense(84, activation='sigmoid')
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
model = LeNet5()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/LeNet5.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
AlexNet
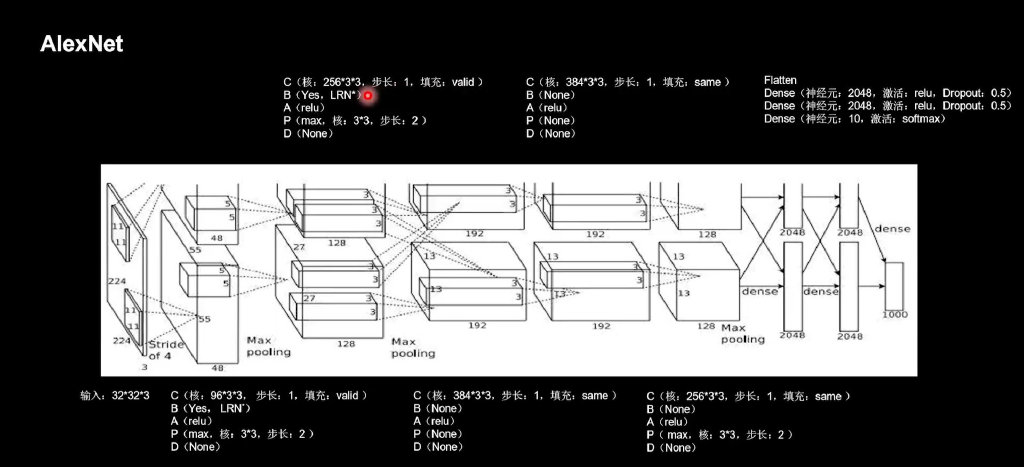
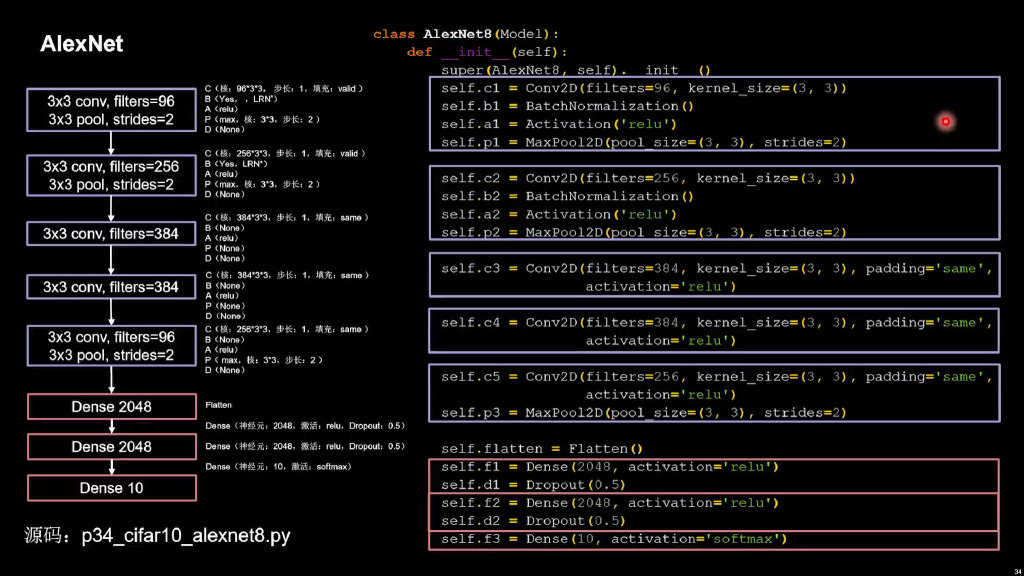
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/AlexNet8.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
VGGNet
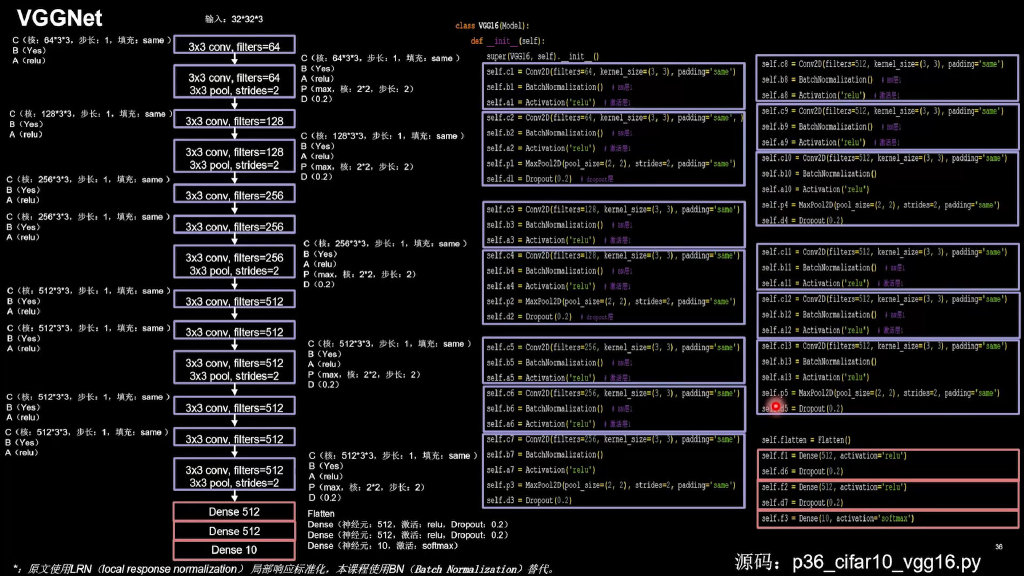
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class VGG16(Model):
def __init__(self):
super(VGG16, self).__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same') # 卷积层1
self.b1 = BatchNormalization() # BN层1
self.a1 = Activation('relu') # 激活层1
self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', )
self.b2 = BatchNormalization() # BN层1
self.a2 = Activation('relu') # 激活层1
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d1 = Dropout(0.2) # dropout层
self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization() # BN层1
self.a3 = Activation('relu') # 激活层1
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization() # BN层1
self.a4 = Activation('relu') # 激活层1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d2 = Dropout(0.2) # dropout层
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization() # BN层1
self.a5 = Activation('relu') # 激活层1
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization() # BN层1
self.a6 = Activation('relu') # 激活层1
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d3 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization() # BN层1
self.a8 = Activation('relu') # 激活层1
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization() # BN层1
self.a9 = Activation('relu') # 激活层1
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d4 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization() # BN层1
self.a11 = Activation('relu') # 激活层1
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization() # BN层1
self.a12 = Activation('relu') # 激活层1
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d5 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(512, activation='relu')
self.d6 = Dropout(0.2)
self.f2 = Dense(512, activation='relu')
self.d7 = Dropout(0.2)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p1(x)
x = self.d1(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p2(x)
x = self.d2(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p3(x)
x = self.d3(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p4(x)
x = self.d4(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p5(x)
x = self.d5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d6(x)
x = self.f2(x)
x = self.d7(x)
y = self.f3(x)
return y
model = VGG16()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/VGG16.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
InceptionNet
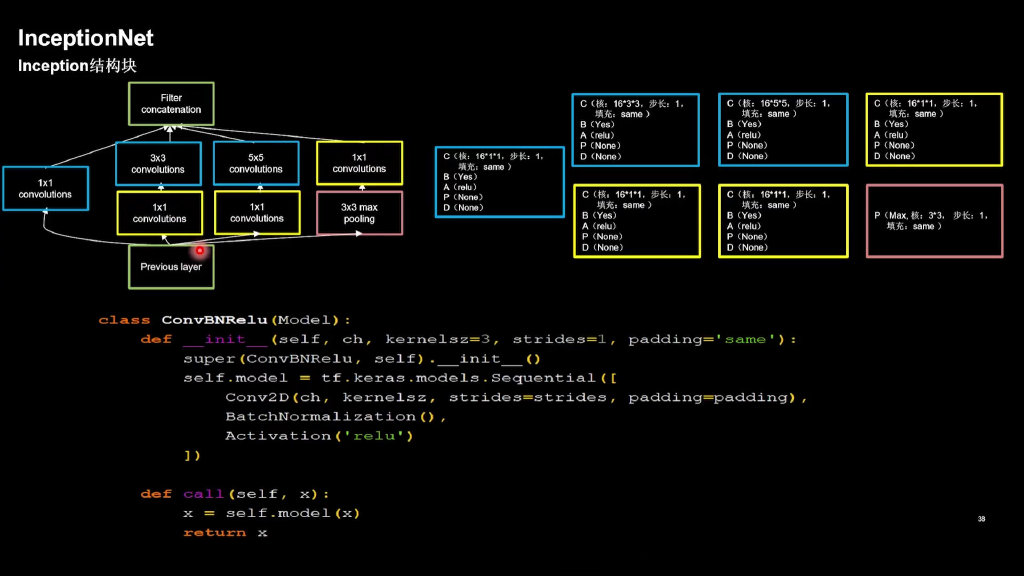
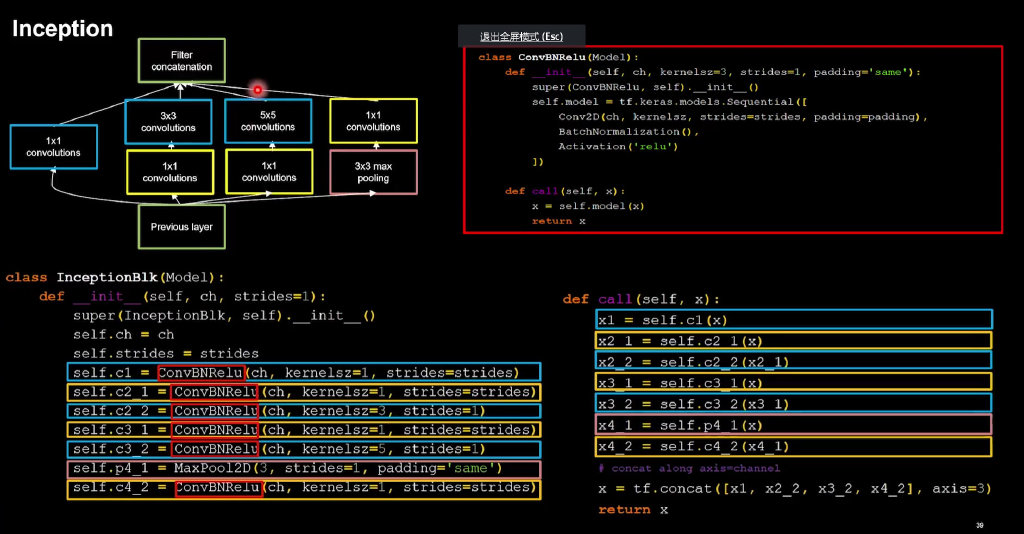
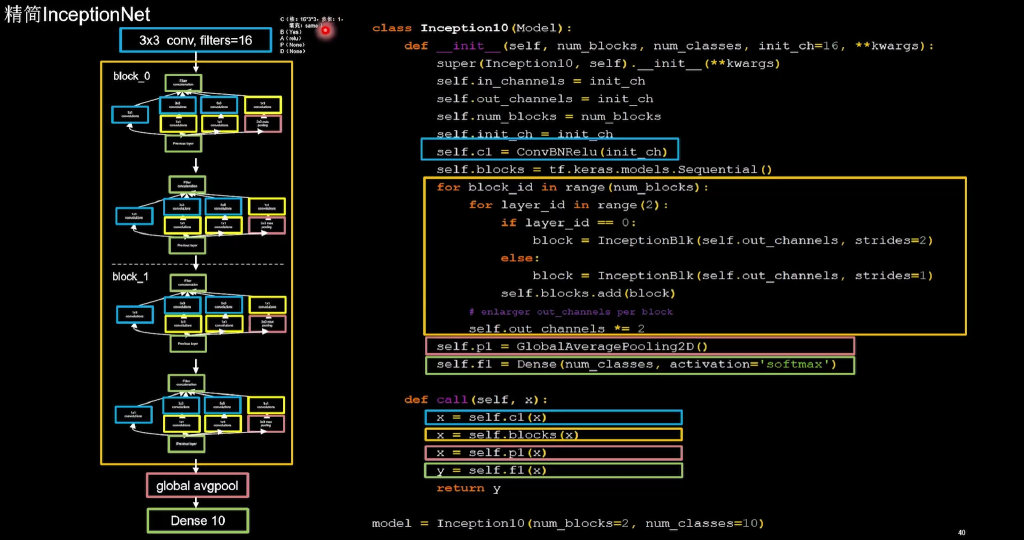
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense, \
GlobalAveragePooling2D
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/Inception10.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
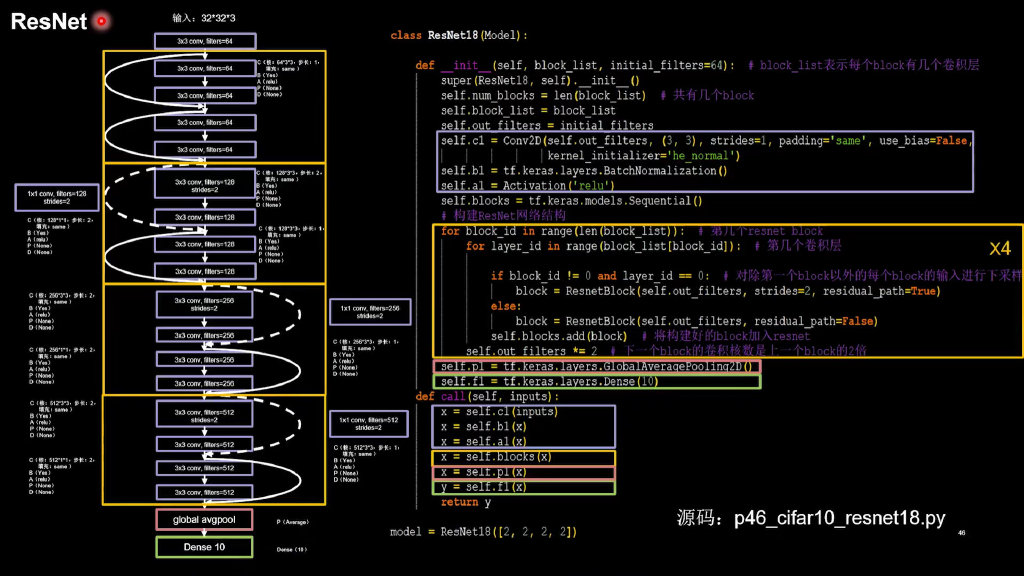
ResNet
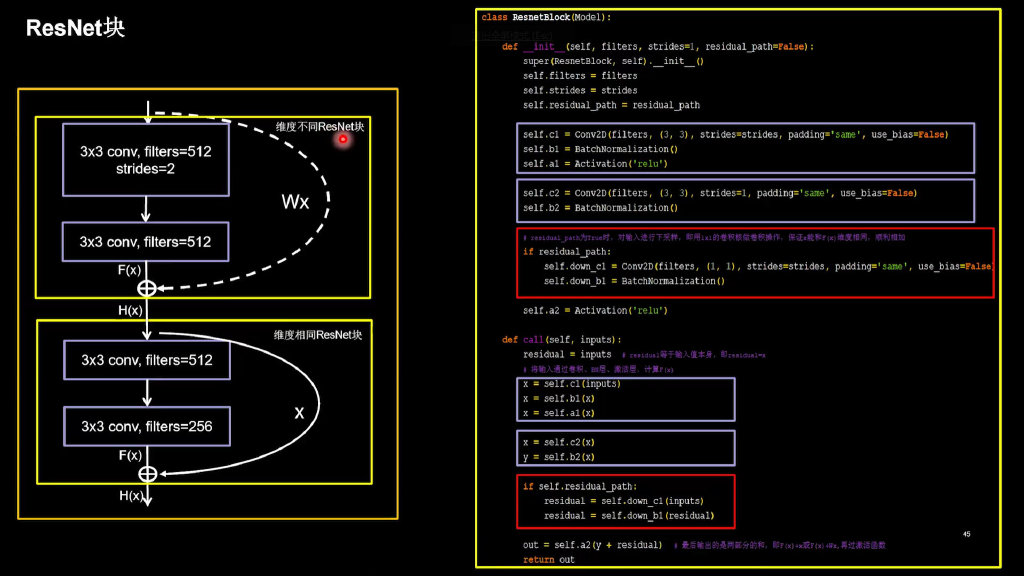
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = ResNet18([2, 2, 2, 2])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/ResNet18.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
总结
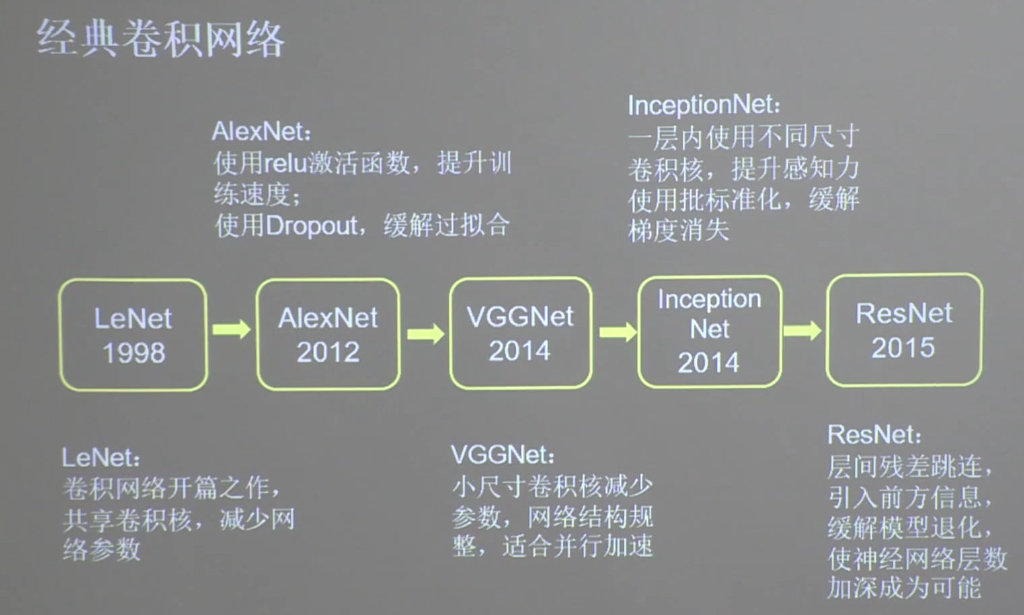
部分截图内容取至:北京大学的tensorflow 2.0课程















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











