






这篇论文在知乎上讨论比较多,主要原因是引入了太多训练trick,没法看出论文创新点的真正贡献,感觉更像是工程上的创新
论文地址:https://arxiv.org/pdf/2004.08955.pdf
Github:https://github.com/zhanghang1989/ResNeSt

先看一下效果直观展示,超越EfficientNet:

Abstract:
尽管图像分类模型最近不断发展,但是由于其简单且模块化的结构,大多数下游应用(例如目标检测和语义分割)仍将ResNet的变体用作骨干网。本文展示了一个模块化的Split-Attention块,该块可实现跨特征图组的注意力。通过以ResNet样式堆叠这些Split-Attention块,我们获得了一个称为ResNeSt的新ResNet变体。我们的网络保留了完整的ResNet结构,可直接用于下游任务,而不会引入额外的计算成本。
ResNeSt模型的优于其他模型复杂度类似的网络。例如,ResNeSt-50使用224 x 224的单个作物尺寸在ImageNet上实现了81.13%的top-1精度,比以前最好的ResNet变种高出1%以上。此改进还有助于下游任务,包括目标检测,实例分割和语义分割。例如,只需将ResNet-50主干网替换为ResNeSt-50,我们就可以将MS-COCO上的Faster-RCNN的mAP从39.3%提高到42.3%,并将ADE20K上的DeeplabV3的mIoU从42.1%提高到45.1%。
Introduction:


ResNeSt源自于:ResNeXt+SKNet,分别对应了上图。主要借鉴了Multi-path与Feature-map Attention思想,主要贡献如下:
1.ResNeSt-50实现了81%+的top-1 准确率
2.应用在Faster-RCNN与DeeplabV3上,map与miou均提升了3%
3.整合了现有很多的trick,这点保持质疑
Split-Attention Networks:


对应上图所示,ResNeSt中先将输入分为k个组,称为Cardinal Groups(这点与ResNeXt一致),每个Cardinal Group中又分为r个radis。这里结合代码来看 具体过程:
1.先对输入特征,分为k个Cardinal Groups,每个Cardinal Group分为r个radis的子特征
2.对分离的每个组进行 1 x 1 + 3 x 3卷积,得到每个h x w x c的特征
3.对2中得到的特征进行sum操作,得到尺寸为h x w x c的特征
4.对3中特征进行F.adaptive_avg_pool2d操作,得到1 x 1 x c的特征
5.对4中特征,进行两个FC操作,得到1 x 1 x r*c的特征
6.进行r-softmax,再分别与r个组进行点乘操作,即为注意力赋值相加
7.与原图进行残差连接
class SplAtConv2d(Module):
"""Split-Attention Conv2d
"""
def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(0, 0),
dilation=(1, 1), groups=1, bias=True,
radix=2, reduction_factor=4,
rectify=False, rectify_avg=False, norm_layer=None,
dropblock_prob=0.0, **kwargs):
super(SplAtConv2d, self).__init__()
padding = _pair(padding)
self.rectify = rectify and (padding[0] > 0 or padding[1] > 0)
self.rectify_avg = rectify_avg
inter_channels = max(in_channels*radix//reduction_factor, 32)
self.radix = radix
self.cardinality = groups
self.channels = channels
self.dropblock_prob = dropblock_prob
if self.rectify:
from rfconv import RFConv2d
self.conv = RFConv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, average_mode=rectify_avg, **kwargs)
else:
self.conv = Conv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, **kwargs)
self.use_bn = norm_layer is not None
if self.use_bn:
self.bn0 = norm_layer(channels*radix)
self.relu = ReLU(inplace=True)
self.fc1 = Conv2d(channels, inter_channels, 1, groups=self.cardinality)
if self.use_bn:
self.bn1 = norm_layer(inter_channels)
self.fc2 = Conv2d(inter_channels, channels*radix, 1, groups=self.cardinality)
if dropblock_prob > 0.0:
self.dropblock = DropBlock2D(dropblock_prob, 3)
self.rsoftmax = rSoftMax(radix, groups)
def forward(self, x):
x = self.conv(x)
if self.use_bn:
x = self.bn0(x)
if self.dropblock_prob > 0.0:
x = self.dropblock(x)
x = self.relu(x)
batch, rchannel = x.shape[:2]
if self.radix > 1:
splited = torch.split(x, rchannel//self.radix, dim=1)
gap = sum(splited)
else:
gap = x
gap = F.adaptive_avg_pool2d(gap, 1)
gap = self.fc1(gap)
if self.use_bn:
gap = self.bn1(gap)
gap = self.relu(gap)
atten = self.fc2(gap)
atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
if self.radix > 1:
attens = torch.split(atten, rchannel//self.radix, dim=1)
out = sum([att*split for (att, split) in zip(attens, splited)])
else:
out = atten * x
return out.contiguous()
Training skill:
一、网络调整:
1.Average Downsampling: 最近的ResNet实现通常将跨步卷积应用于3 x 3层而不是1 x 1层,以更好地保留此类信息。 卷积层需要使用零填充策略来处理特征图边界,这在转移到其他密集的预测任务时通常不是最佳选择。 而不是在过渡块(对空间分辨率进行下采样)处使用大步卷积,我们使用内核大小为3x 3的平均池化层。
2.Tweaks from ResNet-D:(1)将第一个7x 7卷积层替换为三个连续的3x3卷积层,它们具有相同的感受野大小,并且计算成本与原始设计相似。(2)在步长为2的过渡块的1 x 1卷积层之前,将2 x 2平均池化层添加到快捷连接。
二、训练策略:
1.Large Mini-batch Distributed Training
2.Label Smoothing
3.Auto Augmentation
4.Mixup Training
5.Large Crop Size:与ResNet比较采用224,与其他网络采用256
6.Regularization:DropBlock
Experiments:
1.Ablation Study, Radix vs. Cardinality:
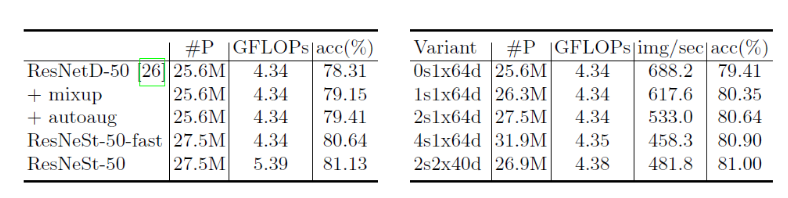
2.ImageNet:

3.Object Detection:

4.Instance Segmentation:

5.Semantic Segmentation:















 4272
4272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









