







前言
1.本文重点是Focal Loss,尽量用较少篇幅表达清楚论文算法,其他一些不影响理解算法的东西不做赘述
2.博客主要是学习记录,为了更好理解和方便以后查看,当然如果能为别人提供帮助就更好了,如果有不对的地方请指正(论文中的链接是我经过大量搜索,个人认为讲解最清楚的参考)
创新点
1.提出Focal Loss,并以Focal Loss为损失设计一个one-stage的检测算法RetinaNet
问题引出
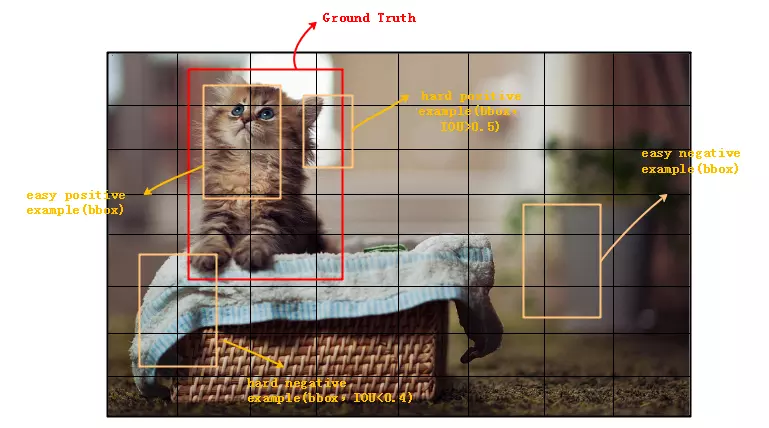
我们都知道目标检测分为一刀流和二刀流,前者速度快精度低,后者速度慢精度高。如果一刀流精度也提上来那岂不是完美,要提高一刀流的精度就得知道它为何精度低,主要原因就是正样本(positive example)和负样本(negative example)以及难分类样本(hard example)和易分类样本(easy example)的不平衡,那什么是正负样本不平衡呢?就是说一张图片中的目标实际上也就一个或者几个,但是候选框的数量能达到百万个,这样一来负样本(候选框里是背景)就会比正样本多的多的多,在这种情况下训练网络,就算正样本的loss非常大也会被数量庞大的负样本中和掉。难分类样本在正负样本的过渡区域上,不是很容易分类,单个hard example的loss大,但是数量少;易分类样本就是不在正负样本的过渡区域上,是正是负很明显,所以容易分类,单个easy example的loss很小,但是数量庞大,把一些hard example的loss覆盖掉,导致求和之后他们依然会支配整个批次样本的收敛方向。说白了就是网络虽然收敛,但是正样本和难分类样本根本没训练好,而正样本恰恰是我们最需要训练好的,这就是一刀流检测算法精度低的原因
二刀流检测算法精度高是因为第一阶段选择候选框(如RPN)的时候会根据得分使用nms来过滤掉很多候选框(如R-CNN系列只留2000个),这样就会过滤掉大部分负样本(背景),同时它是根据前景得分高低来过滤的,所以会把前景概率低(即背景概率高,也就是easy negative example)的过滤掉,这样易分类样本也会减少;第二阶段采用启发式采样(如固定正负样本比为1:3,HEM或OHEM,链接),进一步维持正负样本的平衡可控。而一刀流检测算法直接处理百万个框,尽管也能使用类似的启发式采样,但是训练始终被负样本所支配,没有什么效果
Focal Loss
针对以上问题提出Focal Loss,比之前处理失衡的办法更有效
1.二分类交叉熵损失 (Cross-entropy Error,CE)

其中y={1,-1}是gt的标签,p∈[0,1]是模型为样本估计的概率,为了方便,定义

此时二分类交叉熵损失形式为
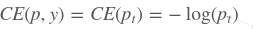
2.解决正负样本不平衡
解决方式很直接,为正负样本分配不同的权重α∈[0,1]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









