







文章目录
1、Episodic Semi-gradient Control
近似控制是求策略的动作值函数, q ^ ≈ q π \hat{q} \approx q_\pi q^≈qπ ,表示为权重向量 θ \theta θ 的参数化函数。
一般的动作值预测的梯度下降更新为:
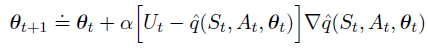
其中,one-step Sarsa方法(episodic semi-gradient one-step Sarsa):
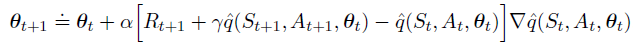

2、n-step Semi-gradient Sarsa
n-step 更新公式:
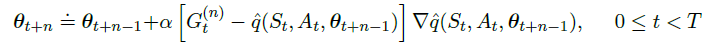
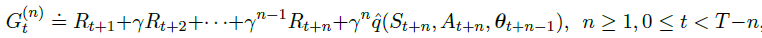
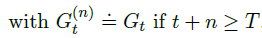

3、Average Reward: A New Problem Setting for Continuing Tasks
由于折扣率(discounting rate)在近似计算中存在一些问题,折扣回报的平均值与平均奖励乘正比。在策略 π \pi π下,折扣回报的平均值总是等于 η ( π ) / ( 1 − γ ) \eta(\pi)/(1-\gamma) η(π)/(1−γ),也就是说其本质就是一个平均奖励 η ( π ) \eta(\pi) η(π)。
因此,在连续性任务中引入了平均奖励(Average Reward):
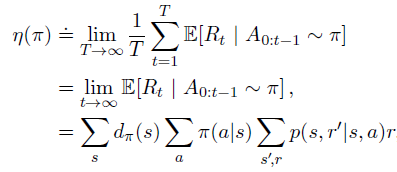
在平均奖励设置中,回报是根据奖励与平均奖励之间的差异来定义的,也叫微分回报:
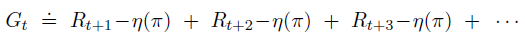
它的相关值函数叫微分值函数,其Bellman方程为:
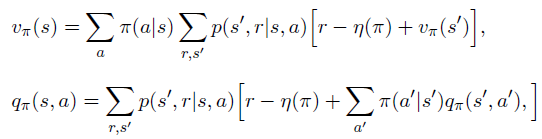
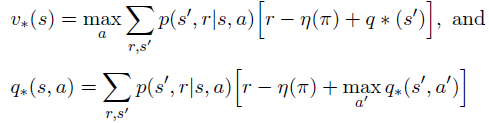
TD errors:
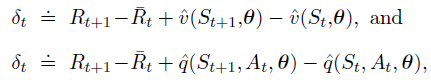
其中,
R
ˉ
\bar{R}
Rˉ 是平均奖励
η
(
π
)
\eta(\pi)
η(π) 的估计值。
平均奖励版本的半梯度Sarsa算法:
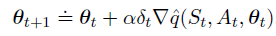

4、n-step Differential Semi-gradient Sarsa
微分形式的 n-step TD error:
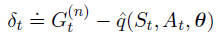
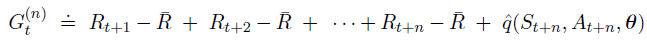
其中,
R
ˉ
\bar{R}
Rˉ 是平均奖励
η
(
π
)
\eta(\pi)
η(π) 的估计值,
n
≥
1
n\geq1
n≥1,
t
+
n
<
T
t+n < T
t+n<T。如果
t
+
n
≥
T
t+n\geq T
t+n≥T,
G
t
(
n
)
≐
G
t
G^{(n)}_t \doteq G_t
Gt(n)≐Gt。

















 2635
2635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









