







 超级会员免费看
超级会员免费看
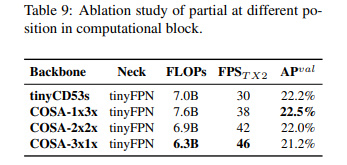
We design an experiment to show how flexible can be if one uses CSPNet with partial functions in computational blocks. We also compare with CSPDarknet53, in which we perform linear scaling down on width and depth.
算法性能
Finally, we put YOLOv4-tiny on different embedded GPUs for testing, including Xavier AGX, Xavier NX, Jetson TX2, Jetson NANO. We also use TensorRT FP32 (FP16 if supported) for testing. All frame rates obtained by different models are listed in Table 14. It is apparent that YOLOv4-tiny can achieve real-time performance no matter which device is used. If we adopt FP16 and batch size 4 to test Xavier AGX and Xavier NX, the frame rate can reach 380 FPS and 199 FPS respectively. In addition, if one uses
TensorRT FP16 to run YOLOv4-tiny on general GPU RTX 2080ti, when the batch size respectively equals to 1 and 4, the respective frame rate can reach 773 FPS and 1774 FPS, which is extremely fast.















 7903
7903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











