







 微软研究团队提出一种基于Transformer的流式语音识别方案,通过改进的掩码机制,有效解决了计算复杂度及延时问题,大幅提升了低延时场景下的解码速度与准确率。
微软研究团队提出一种基于Transformer的流式语音识别方案,通过改进的掩码机制,有效解决了计算复杂度及延时问题,大幅提升了低延时场景下的解码速度与准确率。
从场景上,语音识别可以分为流式语音识别和非流式语音识别。非流式语音识别(离线识别)是指模型在用户说完一句话或一段话之后再进行识别,而流式语音识别则是指模型在用户还在说话的时候便同步进行语音识别。流式语音识别因为其延时低的特点,在工业界中有着广泛的应用,例如听写转录等。
Transformer流式语音识别挑战
目前,Transformer 模型虽然在离线场景下可以进行准确的语音识别,但在流式语音识别中却遭遇了两个致命的问题:
1)计算复杂度和内存储存开销会随着语音时长的增加而变大。
由于 Transformer 使用自注意力模型时会将所有的历史信息进行考虑,因此导致了存储和计算的复杂度会随着语音时长线性增加。而流式语音识别往往本身就有很长的语音输入,所以原生的 Transformer 很难应用于流式语音识别之中。

图1:流式语音识别 Transformer 自注意力示意图
2)Transformer 模型由于层数过多会导致未来窗口大小(lookahead window)传递。
如下图所示,Transformer 模型如果每层往后看一帧,那么最终的向前看(lookahead)会随着 Transformer 层数的增加而累积。例如,一个18层的Transformer,最终会积累18帧的延时,这将在实际应用中带来很大的延时问题,使得语音识别反应速度变慢,用户体验不佳。
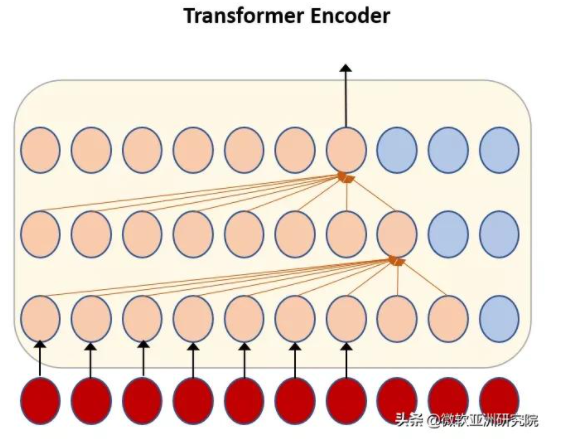
图2:Transformer 的未来窗口随层数而增加
基于块和基于记忆的解决方案
为了解决上述 Transformer 模型在流式语音识别中的问题,科研人员提出了基于块(chunk)和基于记忆(memory)的两种解决方案。
1) 基于块(chunk)的解决方案
第一种方案为基于块的解决方案,如下图所示,其中虚线为块的分隔符。其主体思想是把相邻帧变成一个块,之后根据块进行处理。这种方法的优点是可以快速地进行训练和解码,但由于块之间没有联系,所以导致模型准确率不佳。
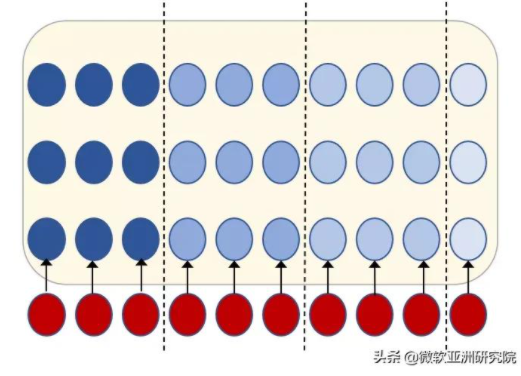
图3:基于块的流式语音识别解决方案
2) 基于记忆(memory)的解决方案
基于记忆的解决方案的主体思想则是在块的基础上引入记忆,让不同块之间可以联系起来。然而,此方法会破坏训练中的非自循环机制,使得模型训练变慢。
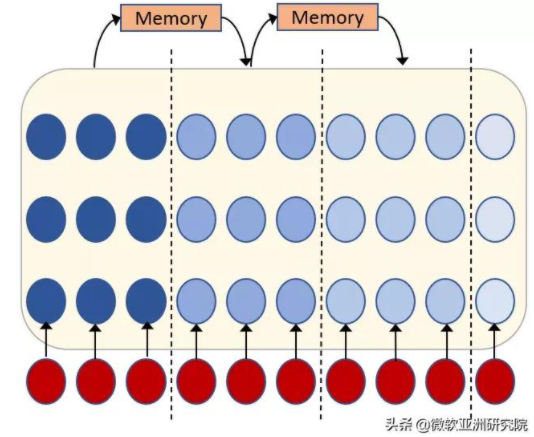
图4:基于记忆的流式语音识别解决方案
工业界中往往有着大量的训练数据,基于记忆的解决方案会让模型训练开销增大。这就促使研究人员需要去寻找可以平衡准确率、训练速度和测试速度的方案。
快速训练和解码,Mask is all you need
针对上述问题,微软的研究员们提出了一种快速进行训练和解码的方法。该方法十分简单,只需要一个掩码矩阵便可以让一个非流的 Transformer 变成流的 Transformer。
下图为非流和0延时的掩码矩阵,其为一个全1矩阵,或者一个下三角阵。
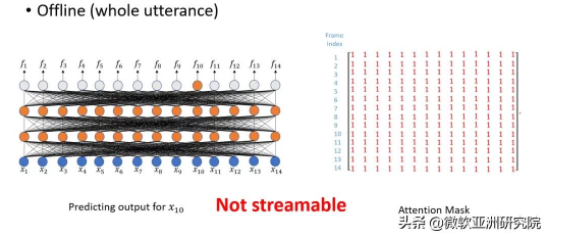
图5:离线语音识别编码器掩码矩阵
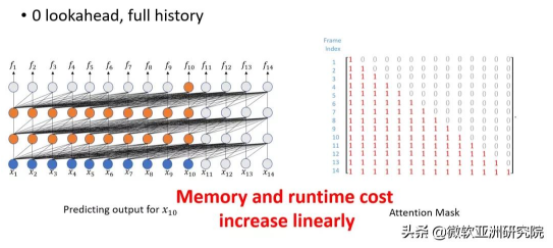
图6:0延时的流式语音识别编码器掩码矩阵
研究员们希望将基于块的方法中的不同块连接起来,并保持 Transformer 并行训练的特点。为了达到这个目的,研究员们提出了一种基于块的流式 Transformer,具体算法如下:
首先,在当前帧左侧,让每一层的每一帧分别向前看 n 帧,这样随着层数的叠加,Transformer 对历史的视野可以积累。如果有 m 层,则可以看到历史的 n*m 帧。虽然看到了额外的 n*m 帧,但这些帧并不会拖慢解码的时间,因为它们的表示会在历史计算时计算好,并不会在当前块进行重复计算。与解码时间相关的,只有每一层可以看到帧的数目。
因为希望未来的信息延时较小,所以要避免层数对视野的累积效应。为了达到这个目的,可以让每一个块最右边的帧没有任何对未来的视野,而块内的帧可以互相看到,这样便可以阻止延时随着层数而增加。
最后,在每个块之间让不同帧都可以相互看到,这样平均延时即块长度的二分之一。
此方法可以让 Transformer 保持并行训练的优势,快速进行训练,其得到的掩码矩阵如下。
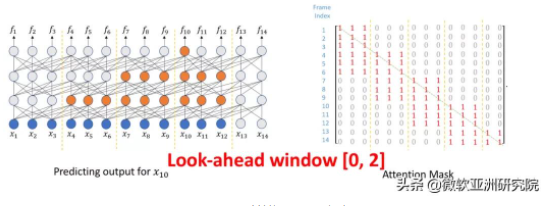
图7:所提出方法的编码器掩码矩阵
在解码过程中,解码时间主要由块的大小而决定。将之前的 key 和 value 进行缓存,这样可以避免重复计算,以加速解码。该方法的公式如下,历史的 key 和 value(标红)在进行注意力权重(attention weight)计算中被缓存。
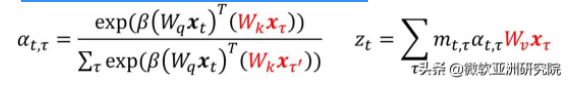
实验
数据集与模型设置
研究员们的实验在微软内部进行了6.5万小时以上的训练,并在微软内部约180万词的测试集上进行了测试。实验使用了32个 GPU,以混合精度的方式训练了约两天可以使模型收敛,并且使用 torchjit 进行测速。研究员们使用 Transducer 框架实现语音识别流式识别,实验对比了 Transformer Transducer (T-T)、Conformer Transducer (C-T)以及 RNN Transducer(RNN-T),其中 Transformer 和 Conformer 的编码部分使用了18层,每层 hidden state(隐藏状态)= 512的参数量。而 Transducer 中的预测网络(predictor network)则使用了 LSTM 网络结构,并包含两层,每层 hidden state = 1024。RNN-T 也与其大小相似。
低延时解码效果
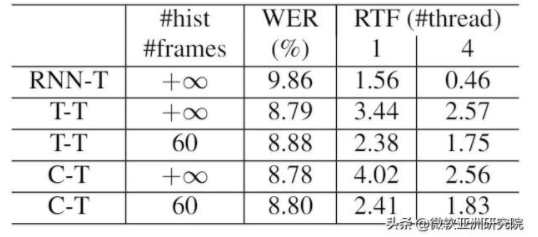
表1:低延时解码效果
从表1可以看到:1)在低延时的情况下,T-T 和 C-T 会比 RNN-T 消除10% 的词错率( Word Error Rate,WER);2)如果每层向左看60帧(1.8s),它和看全部历史的结果相比,性能损失不大,约1%左右;3)然而 T-T 的速度却比 RNN-T 慢了一些,在四线程的情况下 Transformer 速度比 RNN 慢了3倍左右。这个问题可以尝试利用批(batch)的方法来解决,即把相邻的几帧一起进行解码,再利用 Transformer 的并行能力,加速解码。
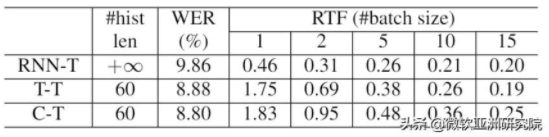
表2:Transformer 的实时率
表2是根据批(batch)中帧的数目的不同,所对应的不同的 Transformer 的实时率。可以看到在两帧一起解码时,Transformer 就已经达到了 RTF<1,而在5帧一起时,RTF<5。据此可以得出结论,在牺牲很少的延时的情况下(2帧约为 40ms),T-T 可以不做量化便可在实际场景中应用。
低延时解码效果
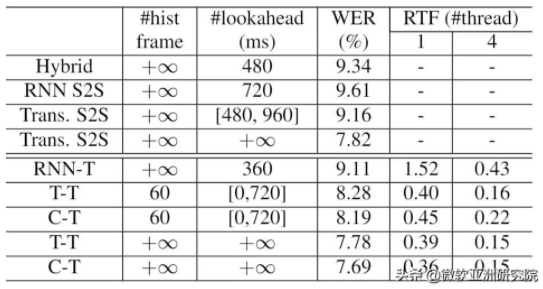
表3:低延时解码效果
而在低延时的情况下,Transformer Transducer 家族的优势更是得以突显。对比传统混合(hybrid)模型,T-T有着13%的 WER改 善,对比流式的 S2S 模型(参数量一致),Transducer 模型往往会达到更好的效果(对比 RNN S2S 和 Trans S2S)。而在同样的 Transducer 框架下,Transformer 模型会比 RNN 模型达到更好的效果,并且速度上也有显著的优势。令人惊讶的是,通过上述方法,目前 T-T 的离线和流式的距离不足10%,这就证明了研究员们提出的流式方法的有效性,可以最大程度避免精度的损失。
8比特量化
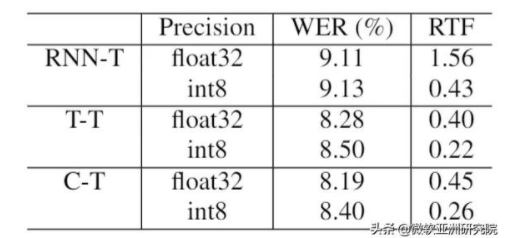
表4:8比特量化结果
经过8比特量化,可以得到更快的 Transducer 模型。在单线程的情况下,Transformer 可以提升一倍的速度,不过,RNN-T 可以提升约4倍的速度。其中,Transformer 速度提升有限的原因是,SoftMax 和 Layer Norm 等操作,难以通过8比特进行加速。
结语
在本文中,微软 Azure 语音团队与微软亚洲研究院的研究员们一起提出了一套结合 Transformer 家族的编码器和流式 Transducer 框架的流式语音识别方案解决方案。该方案利用 Mask is all you need 的机制,可以对流式语音识别模型进行快速训练以及解码。在六万五千小时的大规模训练数据的实验中,可以看到 Transformer 模型比 RNN 模型在识别准确率上有着显著地提高,并在低延时的场景下,解码速度更快。
未来,研究员们将继续研究基于 Transformer 的语音识别模型,力争进一步降低解码的运算消耗,在0延时的场景下,让 Transformer 模型可以与 RNN 模型达到相同的解码速度。
【编辑推荐】

















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









