







说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
购物篮分析是商业领域最前沿、最具挑战性的问题之一,也是许多企业重点研究的问题。购物篮分析是通过发现顾客在一次购买行为中放入购物篮中不同商品之间的关联,研究顾客的购买行为,从而辅助零售企业制定营销策略的一种数据分析方法。
本项目使用Apriori关联规则算法实现购物篮分析,发现超市不同商品之间的关联关系,并根据商品之间的关联规则制定销售策略。
2.项目目标
现代商品种类繁多,顾客往往会因此而变得疲于选择,且顾客并不会因为商品选择丰富而购买更多的商品。繁杂的选购过程往往会给顾客带来疲惫的购物体验。对于某些商品,顾客会选择同时购买,如面包与牛奶、薯片与可乐等,但是如果当面包与牛奶或者薯片与可乐分布在商场的两侧,且距离十分遥远时,顾客的购买欲望就会减弱,在时间紧迫的情况下,顾客甚至会放弃购买某些计划购买的商品。相反,如果把牛奶与面包摆放在相邻的位置,既能给顾客提供便利,提升购物体验,又能提高顾客购买的概率,达到促销的目的。许多商场以打折方式作为主要促销手段,以较少的利润为代价获得更高的销量。打折往往会使顾客增加原计划购买商品的数量,而对于原计划不打算购买且不必要的商品,打折的吸引力远远不足。而正确的商品摆放却能提醒顾客购买某些必需品,甚至吸引他们购买感兴趣的商品。
因此,为了获得最大的销售利润,清楚知晓销售什么样的商品、采用什么样的促销策略、商品在货架上如何摆放以及了解顾客的购买习惯和偏好等对销售商品尤其重要。通过对商场销售数据进行分析,得到顾客的购买行为特征,并根据发现的规律而采取有效的行动,制定商品摆放、商品定价、新商品采购计划,对增加销量并获取最大利润有重要意义。
请根据提供的数据实现以下目标:
1)构建零售商品的Apriori关联规则模型,分析商品之间的关联性。
2)根据模型结果给出销售策略。
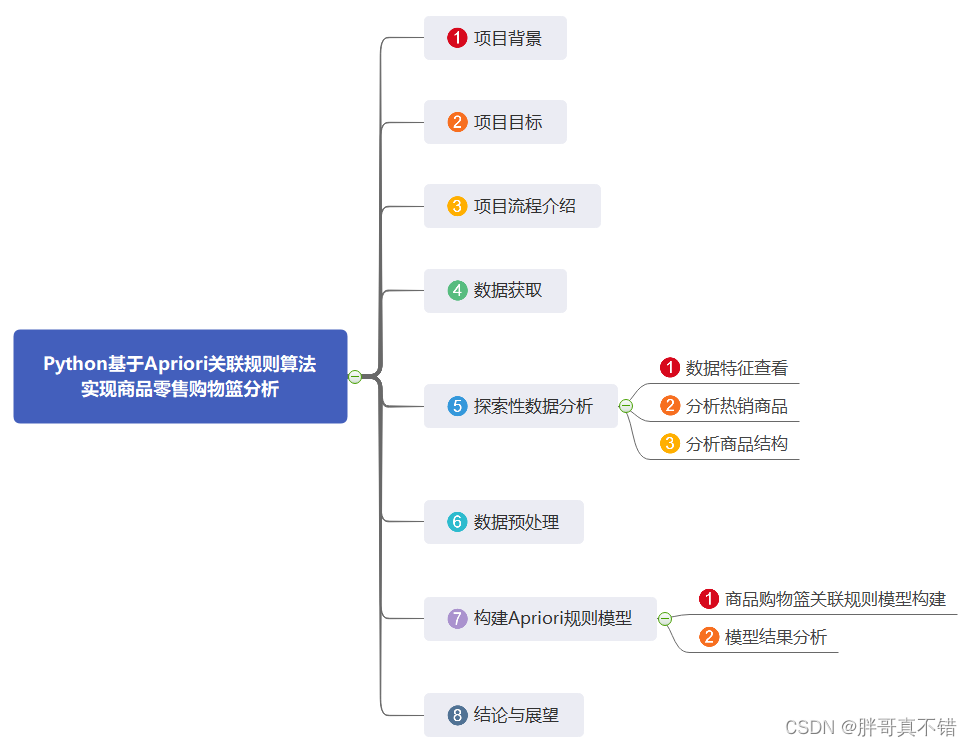
3.项目流程介绍
本次数据挖掘建模的总体流程如图所示
购物篮关联规则挖掘的主要步骤如下:
1)对原始数据进行数据探索性分析,分析商品的热销情况与商品结构。
2)对原始数据进行数据预处理,转换数据形式,使之符合Apriori关联规则算法要求。
3)在步骤2得到的建模数据基础上,采用Apriori关联规则算法调整模型输入参数,完成商品关联性分析。
4)结合实际业务,对模型结果进行分析,根据分析结果给出销售建议,最后输出关联规则结果。
4.数据获取
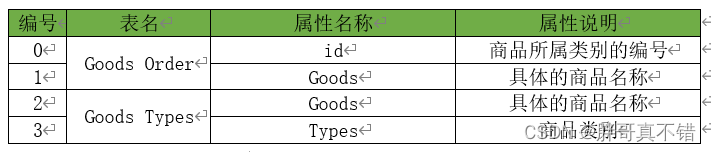
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
某商品零售企业共收集了9835个购物篮数据,它主要包括3个属性:id、Goods和Types。属性的具体说明如表所示:
数据详情如下(部分展示):
5.探索性数据分析
本项目的探索分析是查看数据特征以及对商品热销情况和商品结构进行分析。
探索数据特征是了解数据的第一步。分析商品热销情况和商品结构,是为了更好地实现企业的经营目标。商品管理应坚持商品齐全和商品优选的原则,产品销售应基本满足“二八定律”,即80%的销售额是由20%的商品创造的,这些商品是企业的主要盈利商品,要作为商品管理的重中之重。商品热销情况分析和商品结构分析也是商品管理中不可或缺的一部分,其中商品结构分析能够保证商品的齐全性,热销情况分析可以助力商品优选。
5.1数据特征查看
探索数据的特征,查看每列属性、最大值、最小值是了解数据的第一步。查看数据特征,关键代码如下:
结果截图如下:
从上图可得,每列属性共有43367个观测值,并不存在缺失值。查看“id”属性的最大值和最小值,可知某商品零售企业共收集了9835个购物篮数据,其中包含169个不同的商品类别,售出商品总数为43367件。
5.2分析热销商品
商品热销情况分析是商品管理中不可或缺的一部分,热销情况分析可以助力商品优选。计算销量排行前10的商品销量及占比,并绘制条形图显示销量前10的商品销量情况,关键代码如下:
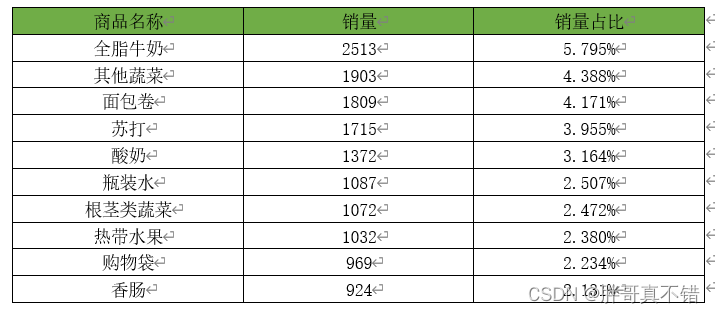
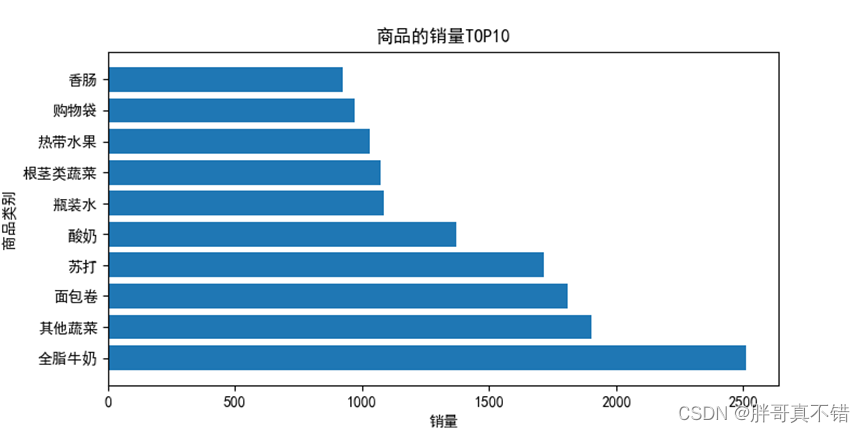
根据代码可得销量排行前10的商品销量及其占比情况,如下图所示:
销量排行前10的商品销量及其占比
销量排行前10的商品销量情况
通过分析热销商品的结果可知,全脂牛奶的销售量最高,为2513件,占比5.795%;其次是其他蔬菜、面包卷和苏打,占比分别为4.388%、4.171%、3.955%。
5.3分析商品结构
对每一类商品的热销程度进行分析,有利于商家制定商品在货架上的摆放策略和位置,若是某类商品较为热销,商场可以把此类商品摆放到商场的中心位置,以方便顾客选购;或者是放在商场深处的位置,使顾客在购买热销商品前经过非热销商品所在位置,增加在非热销商品处的停留时间,以促进非热销商品的销量。
原始数据中的商品本身已经经过归类处理,但是部分商品还是存在一定的重叠,故需要再次对其进行归类处理。分析归类后各类别商品的销量及其占比后,绘制饼图来显示各类商品的销量占比情况,关键代码如下:
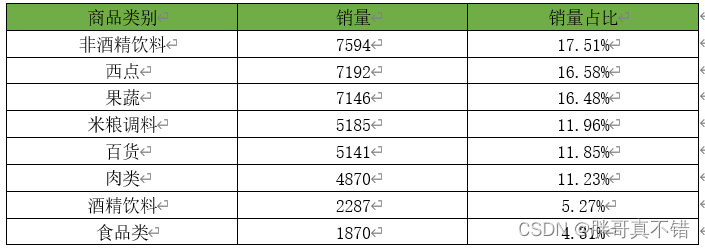
根据代码可得各类别商品的销量及其占比情况,结果如下图标所示:
通过分析各类别商品的销量及其占比情况可知,非酒精饮料、西点、果蔬3类商品的销量差距不大,占总销量的50%左右,同时,根据大类划分发现,和食品类的销量总和接近90%,说明顾客倾向于购买此类商品,而其余商品仅是商场为满足顾客的其他需求而设定的,并非销售的主力军。
各类别商品的销量及其占比
各类别商品的销量占比情况
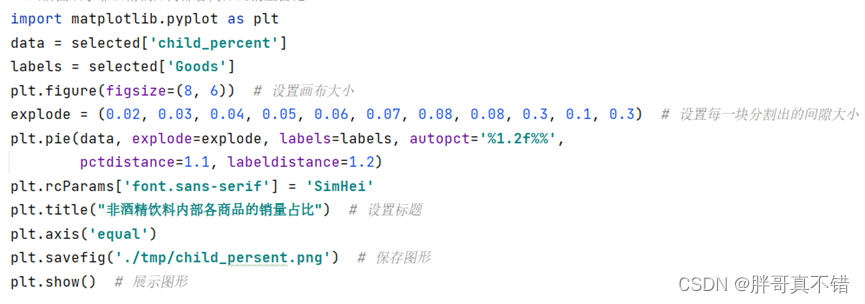
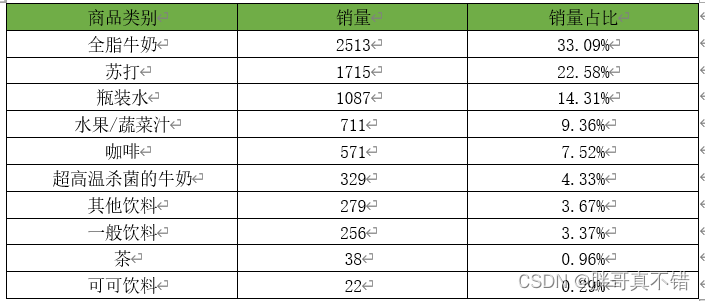
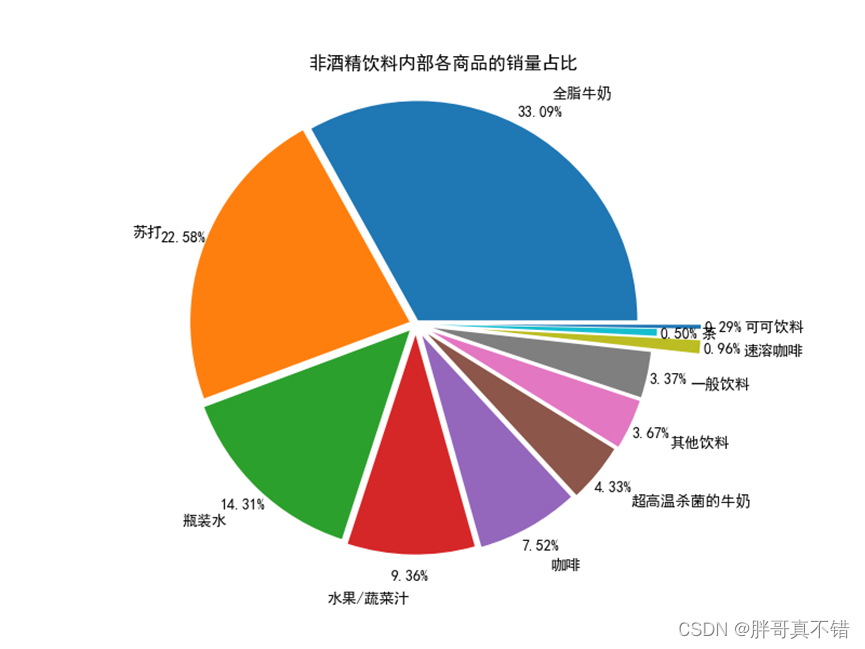
进一步查看销量第一的非酒精饮料类商品的内部商品结构,并绘制饼图显示其销量占比情况,其关键代码如下:
根据代码清单可得非酒精饮料内部商品的销量及其占比情况,如下图表所示:
非酒精饮料内部商品的销量及其占比
非酒精饮料内部商品的销量占比情况
通过分析非酒精饮料内部商品的销量及其占比情况可知,全脂牛奶的销量在非酒精饮料的总销量中占比超过33%,前3种非酒精饮料的销量在非酒精饮料的总销量中的占比接近70%,这就说明大部分顾客到店购买的饮料为这3种,而商场就需要时常注意货物的库存,定期补货。
6.数据预处理
通过对数据探索分析发现数据完整,并不存在缺失值。建模之前需要转变数据的格式,才能使用Apriori函数进行关联分析。对数据进行转换,其关键代码如下:
结果输入如下:
7.构建Apriori规则模型
本项目的目标是探索商品之间的关联关系,因此采用关联规则算法,以挖掘它们之间的关联关系。关联规则算法主要用于寻找数据中项集之间的关联关系,它揭示了数据项间的未知关系。基于样本的统计规律,进行关联规则分析。根据所分析的关联关系,可通过一个属性的信息来推断另一个属性的信息。当置信度达到某一阈值时,就可以认为规则成立。Apriori算法是常用的关联规则算法之一,也是最为经典的分析频繁项集的算法,它是第一次实现在大数据集上可行的关联规则提取的算法。除此之外,还有FP-Tree算法,Eclat算法和灰色关联算法等。本项目主要使用Apriori算法进行分析。
关联规则指标说明:
Support(支持度):表示某个项集出现的频率,也就是包含该项集的交易数与总交易数的比例。例如P(A)表示项集A的比例,
表示项集A和项集B同时出现的比例。
Confidence(置信度):表示当A项出现时B项同时出现的频率,记作{A→B}。换言之,置信度指同时包含A项和B项的交易数与包含A项的交易数之比。公式表达:{A→B}的置信度=
。
Lift(提升度):指A项和B项一同出现的频率,但同时要考虑这两项各自出现的频率。公式表达:{A→B}的提升度={A→B}的置信度/P(B)=
。
提升度反映了关联规则中的A与B的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性。负值,商品之间具有相互排斥的作用。但是一般在大数据实际应用中,提升度大于3才算是正相关。
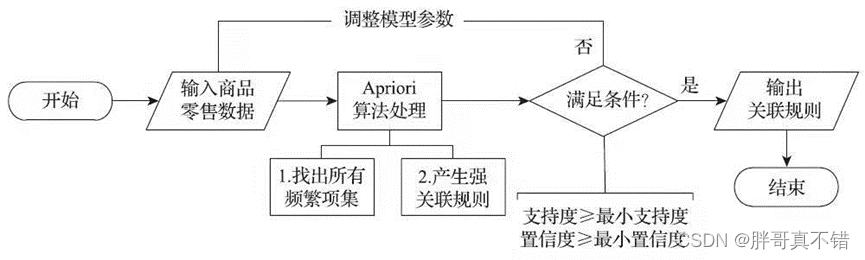
7.1商品购物篮关联规则模型构建
本次商品购物篮关联规则建模的流程如图所示:
商品购物篮关联规则模型建模流程图
由上图可知,模型主要由输入、算法处理、输出3个部分组成。输入部分包括建模样本数据的输入和建模参数的输入。算法处理部分是采用Apriori关联规则算法进行处理。输出部分为采用Apriori关联规则算法进行处理后的结果。
模型具体实现步骤:首先设置建模参数最小支持度、最小置信度,输入建模样本数据;然后采用Apriori关联规则算法对建模的样本数据进行分析,以模型参数设置的最小支持度、最小置信度以及分析目标作为条件,如果所有的规则都不满足条件,则需要重新调整模型参数,否则输出关联规则结果。
目前,如何设置最小支持度与最小置信度并没有统一的标准。大部分都是根据业务经验设置初始值,然后经过多次调整,获取与业务相符的关联规则结果。本项目经过多次调整并结合实际业务分析,选取模型的输入参数为:最小支持度0.02、最小置信度0.35。其关联规则关键代码如下:
输出结果如下:
7.2模型结果分析
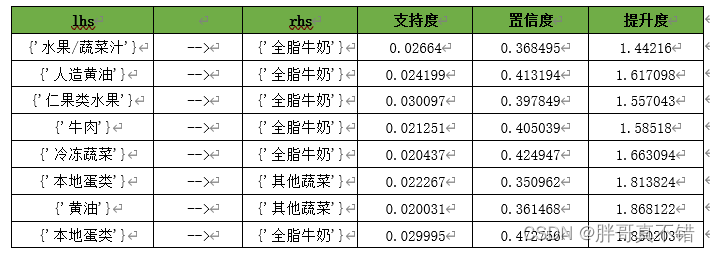
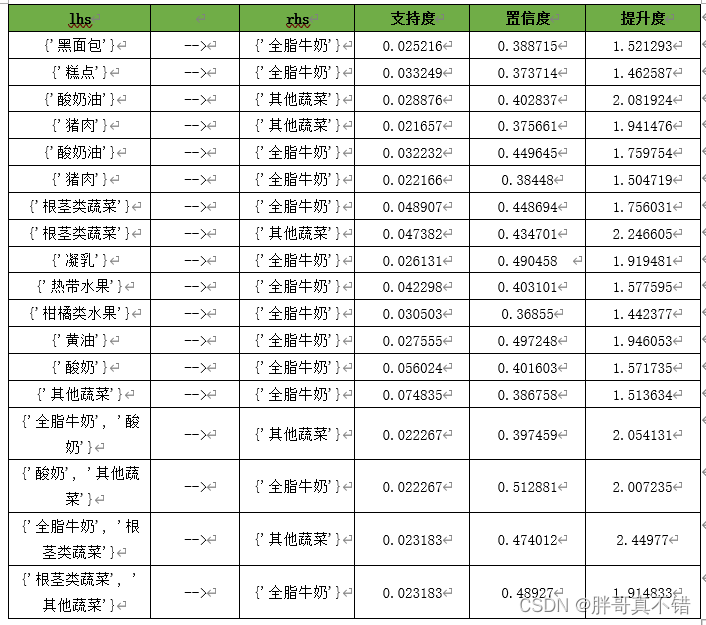
根据代码清单的运行结果,我们得出了26个关联规则。根据规则结果,可整理出购物篮关联规则模型结果,如下表所示:
根据表中的输出结果,对其中4条进行解释分析如下:
1){'其他蔬菜','酸奶'}=>{'全脂牛奶'}支持度约为2.23%,置信度约为51.29%。说明同时购买酸奶、其他蔬菜和全脂牛奶这3种商品的概率达51.29%,而这种情况发生的可能性约为2.23%。
2){'其他蔬菜'}=>{'全脂牛奶'}支持度最大约为7.48%,置信度约为38.68%。说明同时购买其他蔬菜和全脂牛奶这两种商品的概率达38.68%,而这种情况发生的可能性约为7.48%。
3){'根茎类蔬菜'}=>{'全脂牛奶'}支持度约为4.89%,置信度约为44.87%。说明同时购买根茎类蔬菜和全脂牛奶这3种商品的概率达44.87%,而这种情况发生的可能性约为4.89%。
4){'根茎类蔬菜'}=>{'其他蔬菜'}支持度约为4.74%,置信度约为43.47%。说明同时购买根茎类蔬菜和其他蔬菜这两种商品的概率达43.47%,而这种情况发生的可能性约为4.74%。
综合表以及输出结果分析,顾客购买酸奶和其他蔬菜的时候会同时购买全脂牛奶,其置信度最大达到51.29%。因此,顾客同时购买其他蔬菜、根茎类蔬菜和全脂牛奶的概率较高。
对于模型结果,从购物者角度进行分析:现代生活中,大多数购物者为“家庭煮妇”,购买的商品大部分是食品,随着生活质量的提高和健康意识的增加,其他蔬菜、根茎类蔬菜和全脂牛奶均为现代家庭每日饮食的所需品。因此,其他蔬菜、根茎类蔬菜和全脂牛奶同时购买的概率较高,符合人们的现代生活健康意识。
8.结论与展望
以上的模型结果表明:顾客购买其他商品的时候会同时购买全脂牛奶。因此,商场应该根据实际情况将全脂牛奶放在顾客购买商品的必经之路上,或是放在商场显眼的位置,以方便顾客拿取。顾客同时购买其他蔬菜、根茎类蔬菜、酸奶油、猪肉、黄油、本地蛋类和多种水果的概率较高,因此商场可以考虑捆绑销售,或者适当调整商场布置,将这些商品的距离尽量拉近,从而提升顾客的购物体验。



























11-18
 9794
9794
9794
07-01
4208
4208
09-12
4680
4680
08-16
662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











