







前言
上一篇文章我们实践了通过调用在线open-api的方式接入大模型,但是处于数据安全或者高并发时的费用成本考虑,我们可能有本地部署大模型的需求。
LangChain4j实现了统一的 Java API 屏蔽底层差异,一键切换本地 Ollama 与云端模型,所以本文来实践一下从本地部署到应用接入的全过程。
一、本地部署优点
① 数据安全与隐私
在金融、医疗等对数据安全要求极高的行业,所有请求与文本处理均在本地机器或内部私有云完成,敏感信息不出内网,能有效防止数据泄露及合规风险。相较在线 API,企业无需与第三方共享原始文本,也不必担心跨境传输带来的合规挑战(例如 GDPR、CCPA 等)。
② 低时延与高可靠
在线调用往返网络请求,容易受到带宽抖动、网络拥堵等影响,尤其对实时性要求高的应用(如客服机器人、工业控制)不利。本地部署后,推理请求是在本地完成,响应时延由数百毫秒降至几十毫秒,甚至更低。同时在无网络环境或云服务中断情况下,应用依旧可用,保障了业务连续性。
③ 成本优化
云端大多数按调用次数或消耗的 token 数量计费,流量和调用量激增时成本攀升迅速。相比之下,本地部署一次性采购或使用开源模型,无需按调用额外付费;只需考虑硬件折旧、电力与运维成本,更易进行成本预测与控制。
④ 深度定制与可控性
Ollama 支持从社区或自研训练的多种开源模型(Llama 2、Mistral、Gemma 等)中自由选择,并可对模型进行细粒度微调、参数调整及插件扩展,充分契合业务场景需求。在线 API 则多受限于服务商的模型版本与功能,对模型内部参数和训练细节无权访问。
⑤ 离线可用性
在监管严格或网络隔离的环境(如政府、军工、制造业)中,禁联网环境要求本地化部署。Ollama 本地化部署提供“脱机推理”能力,即使在完全断网状态下也可运行大模型推理与微调,满足“内网内办”需求。
⑥ 对计算资源的完全掌控
本地化部署可根据实际硬件资源(GPU/CPU/内存)进行配置,灵活调整批量大小、并行度、显存分配等,最大化利用现有算力;同时可结合 Kubernetes、Slurm 等集群管理工具做弹性伸缩,避免云端“黑盒”资源调度带来的波动性。
⑦ 与 LangChain4j 集成的协同优势
LangChain4j 提供与 OpenAI、Anthropic、Ollama 等多种模型的一致调用接口,轻松切换,代码改动极少;在同一个流程中,可根据需要将本地 Ollama 与云端模型结合使用,实现“成本-性能-功能”最优平衡;结合本地 Ollama 与 LangChain 的检索增强(RAG)组件,实现对私有文档的高效检索和生成,进一步提升对行业特定语料的适应能力。
二、Windows安装ollama
① ollama官网地址
② 进入下载界面
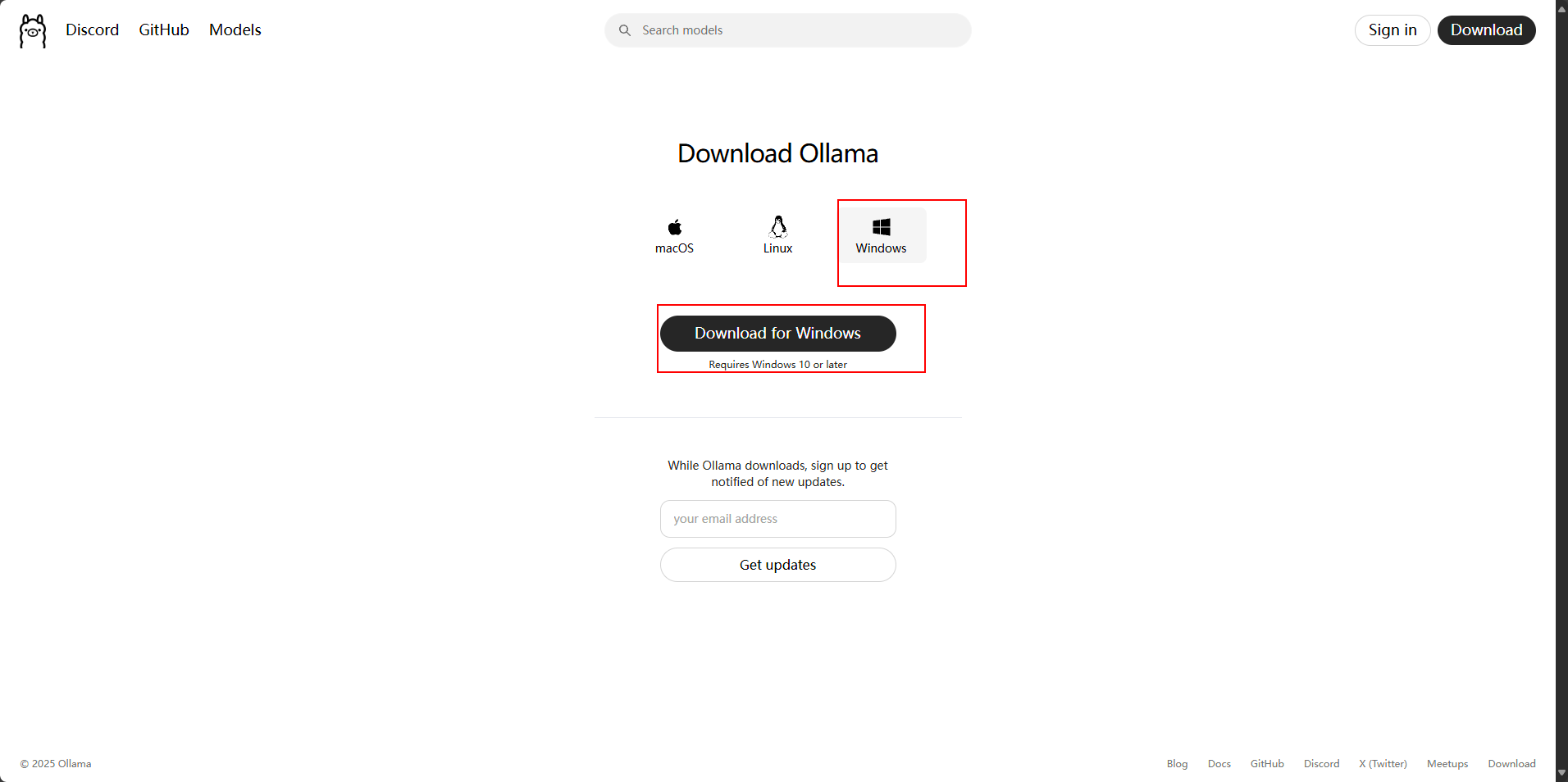
③ 选择Windows版本下载
请注意,根据官方说明Windows的版本需要在10以上,本文使用的是Windows 11-24H2
④ 安装ollama
双击下载的安装文件,然后一步一步根据指令安装即可。
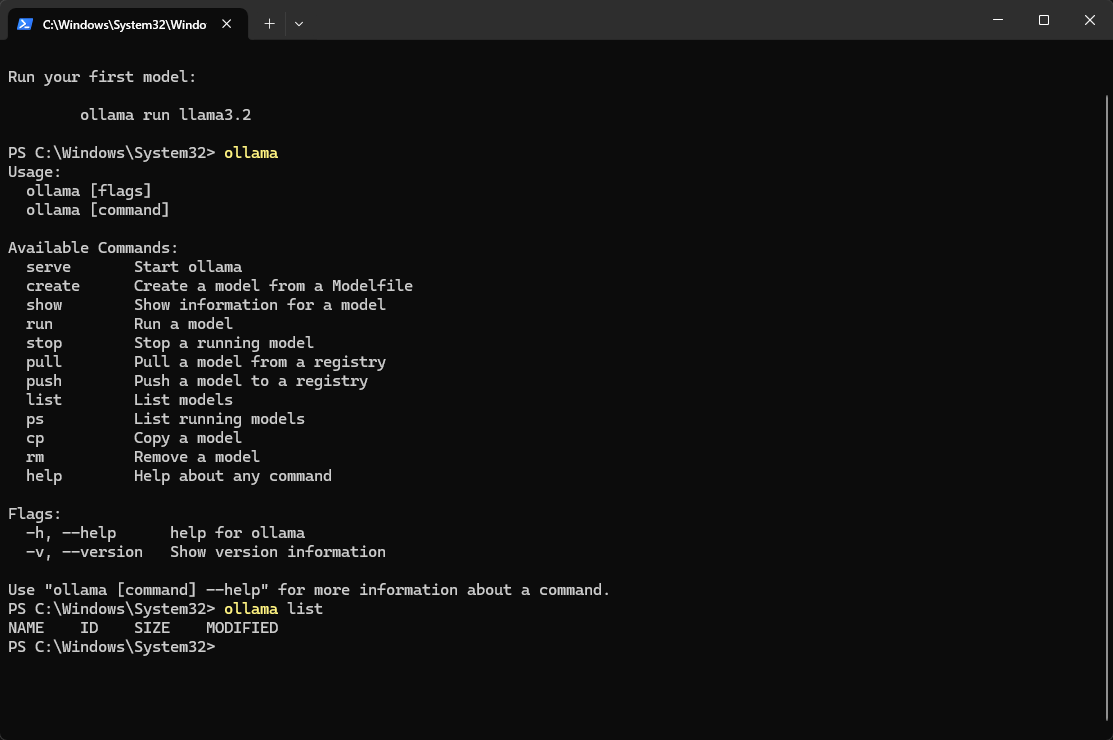
安装成功后
三、ollama部署deepseek
① 选择模型
进入ollama的官方推荐模型区选择需要的大模型。
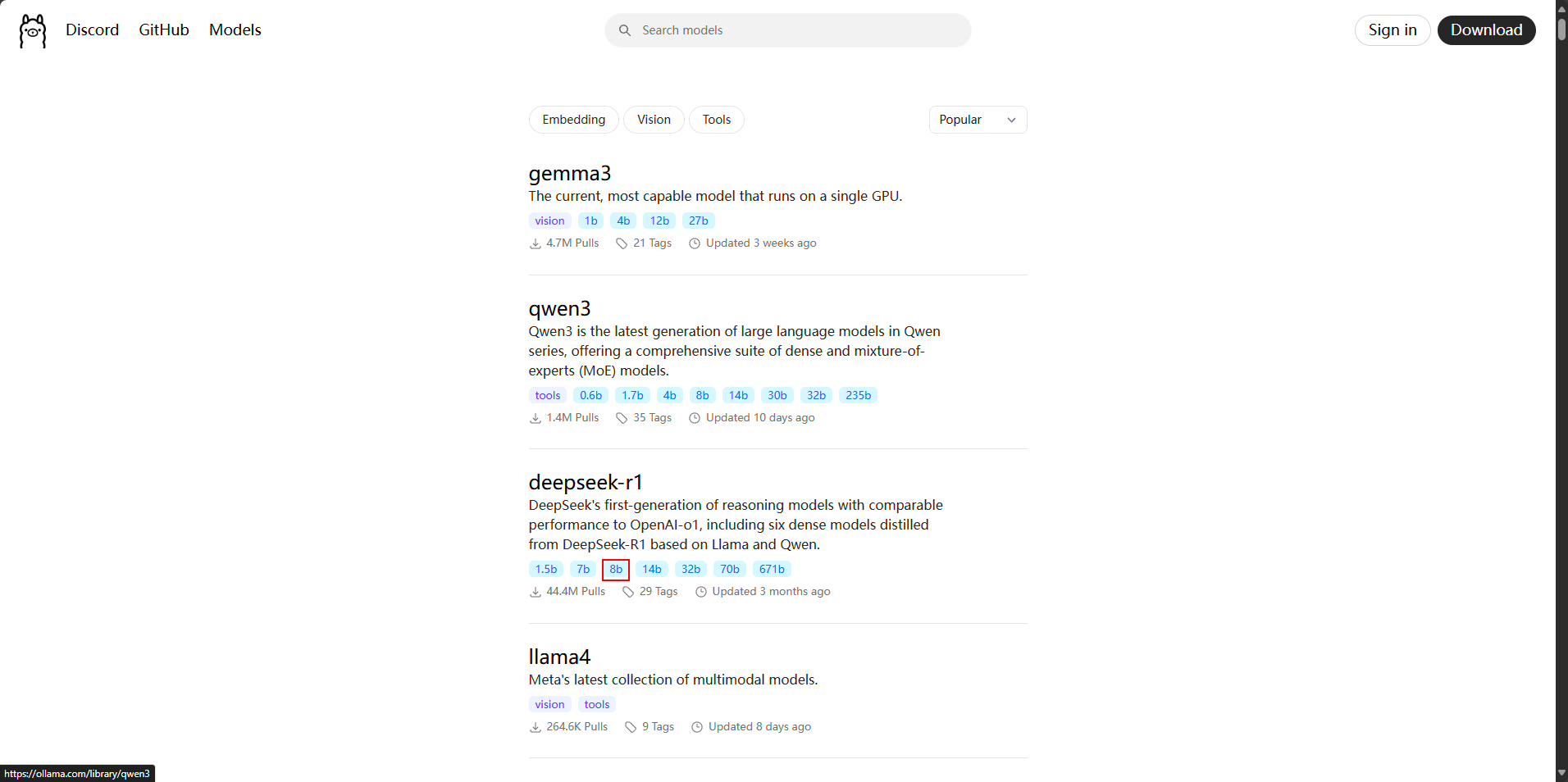
我的电脑显卡是4060 8G显存版本,选择deepseek-r1的8b蒸馏版本比较适合,各位可以根据自己的显卡配置选择对应的蒸馏版本。复制官方命令执行即可,ollama会自动拉取大模型。
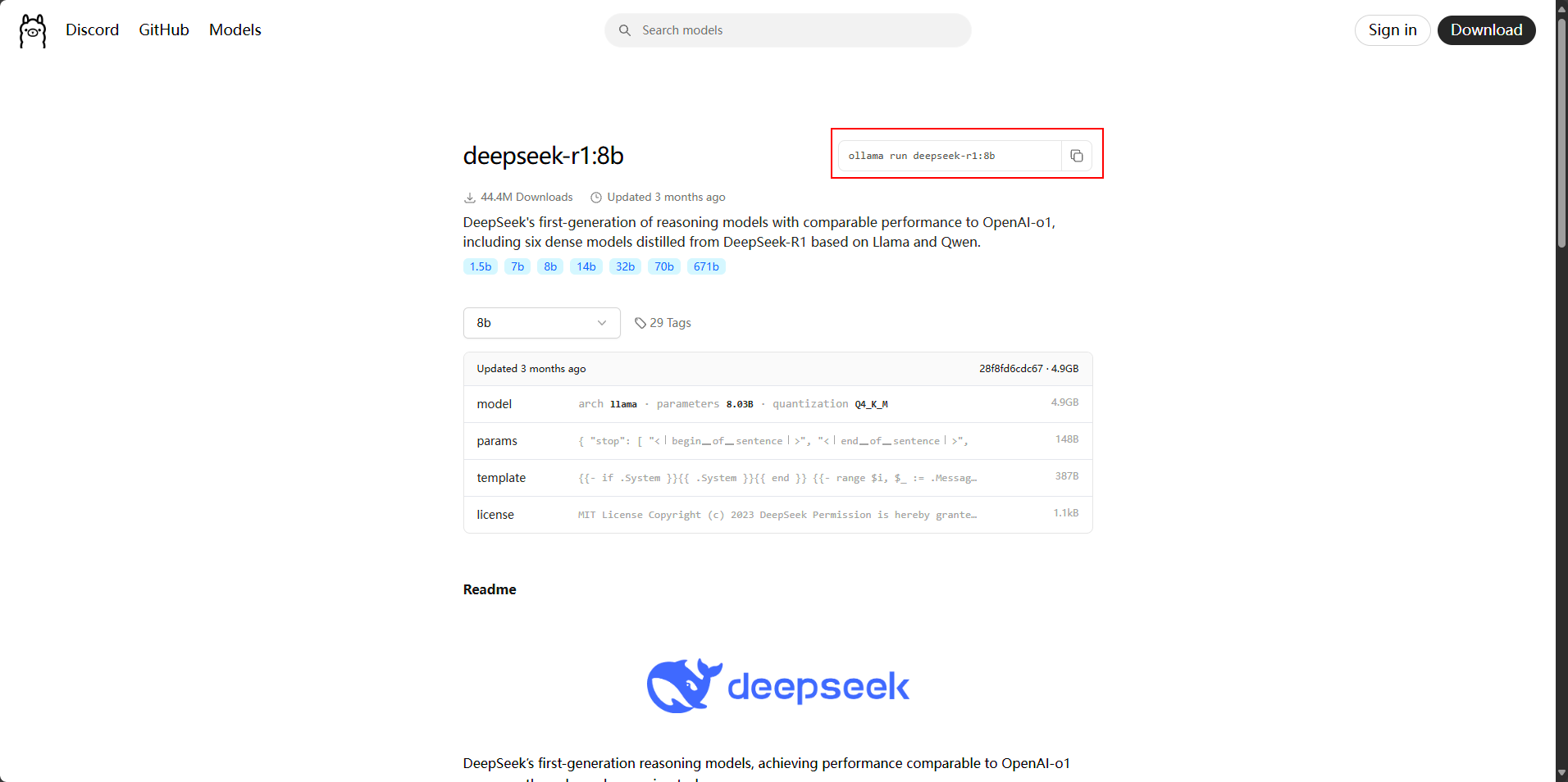
② 部署模型
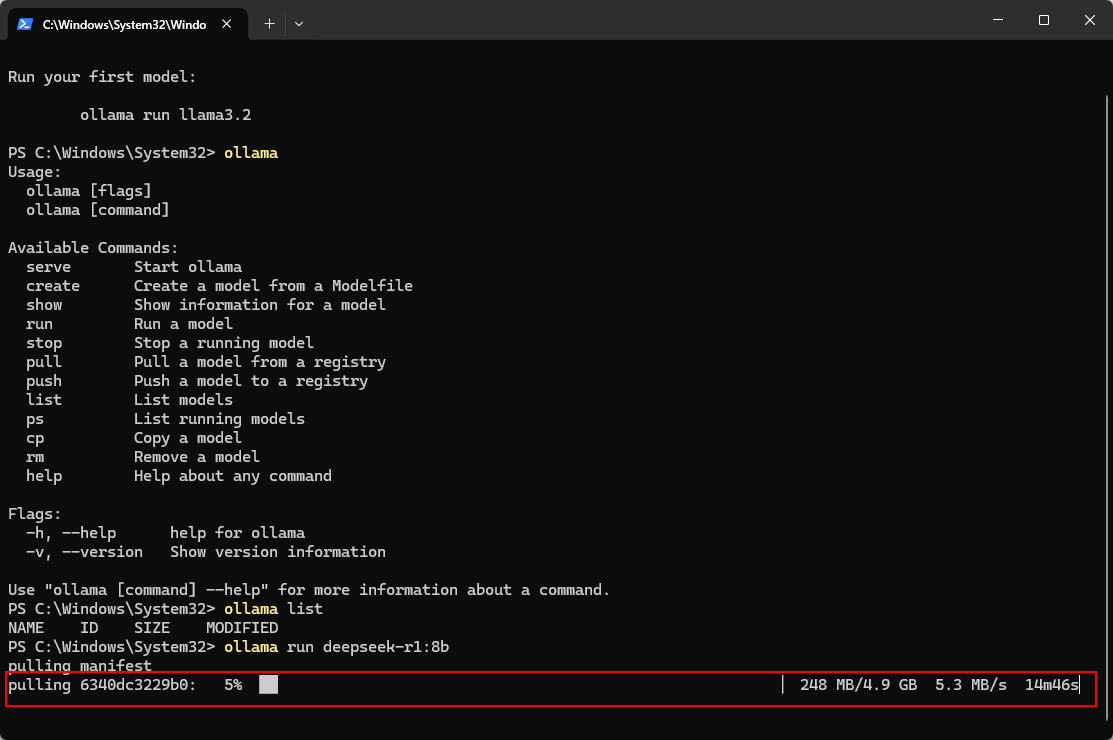
等待下载ing
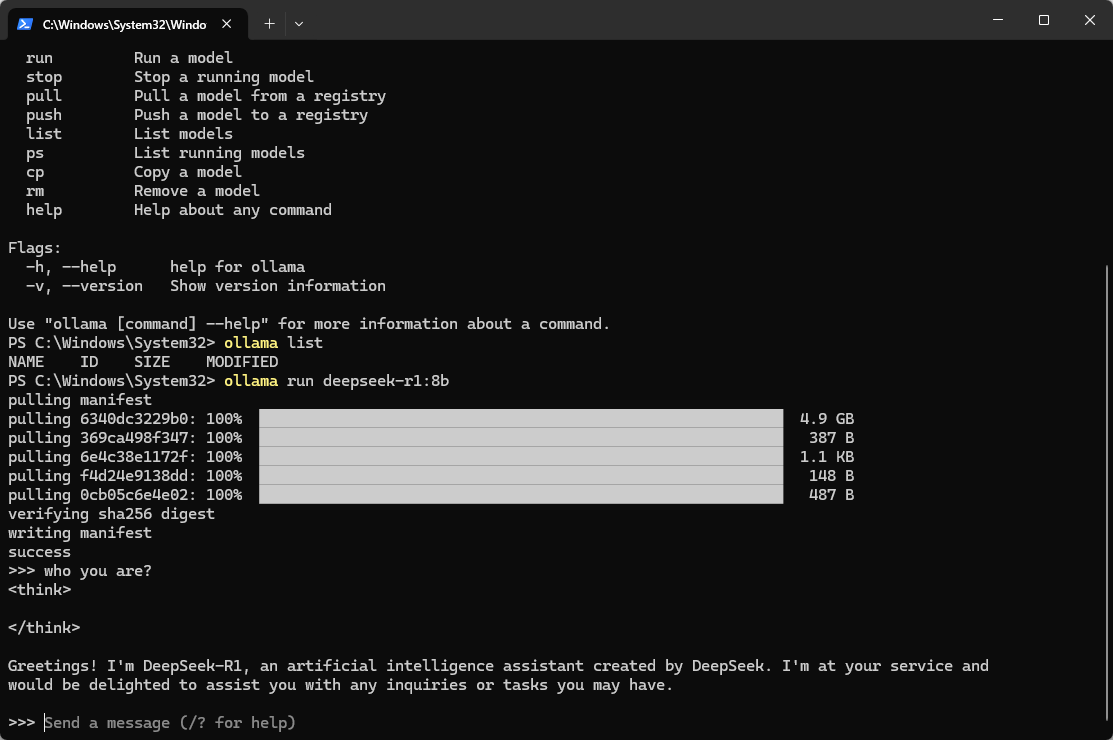
下载完成,验证功能
四、SpringBoot应用接入
① 引入依赖
查看官方文档的引入方式
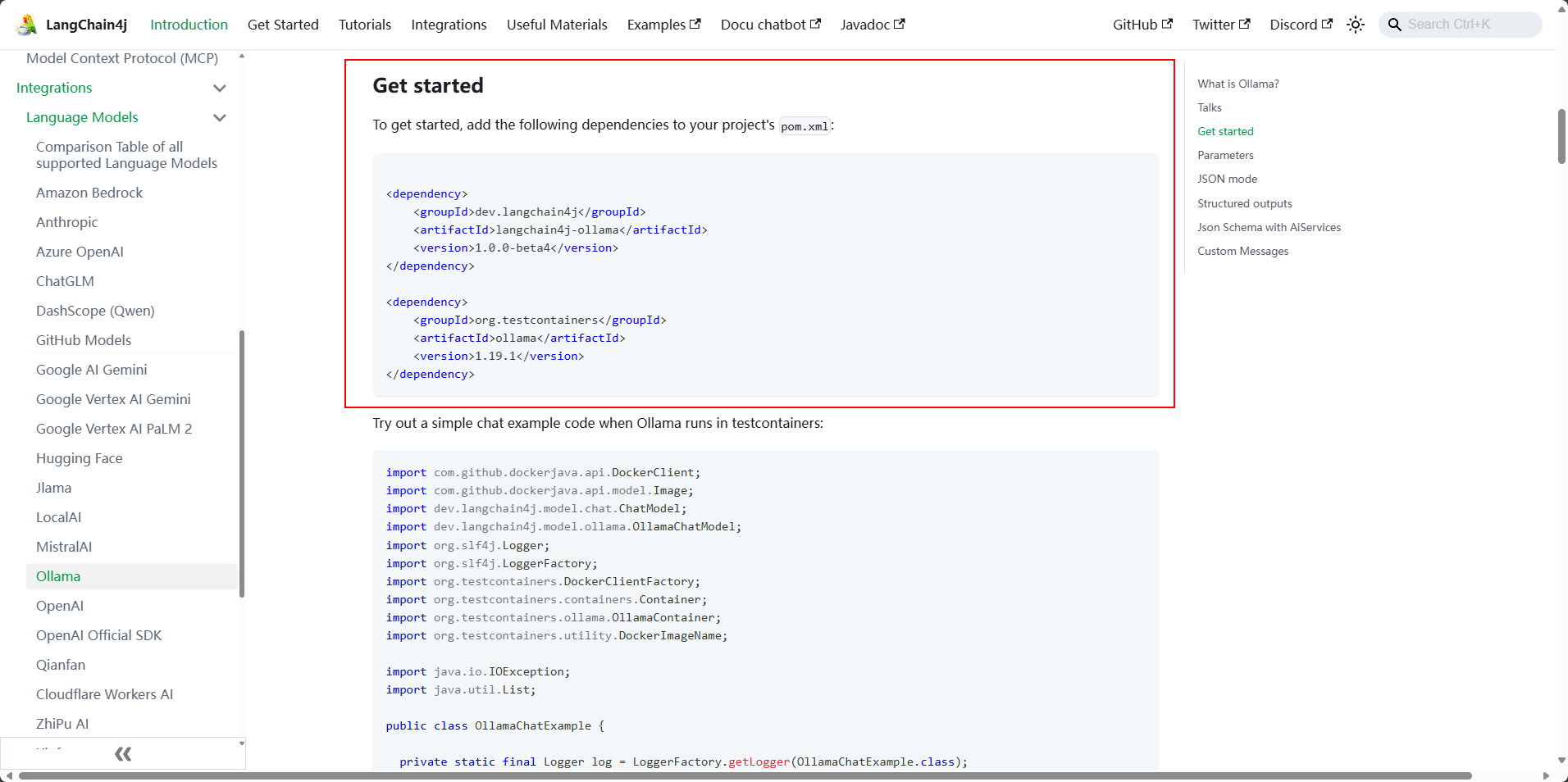
我们直接使用starter方式引入,直接可以使用配置文件初始化,不需要手动配置了
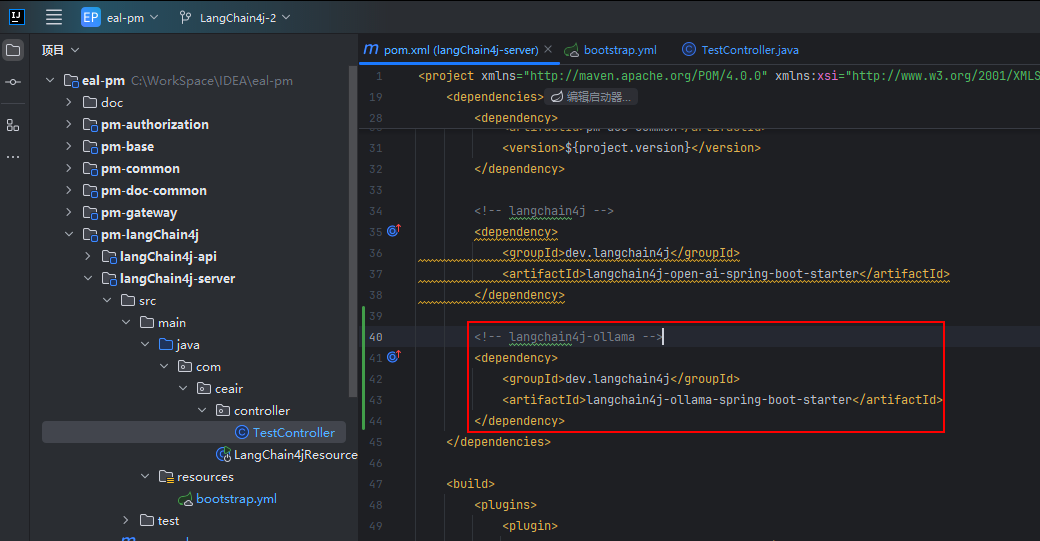
<!-- langchain4j-ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>② 添加配置
还是查看官网的配置方式
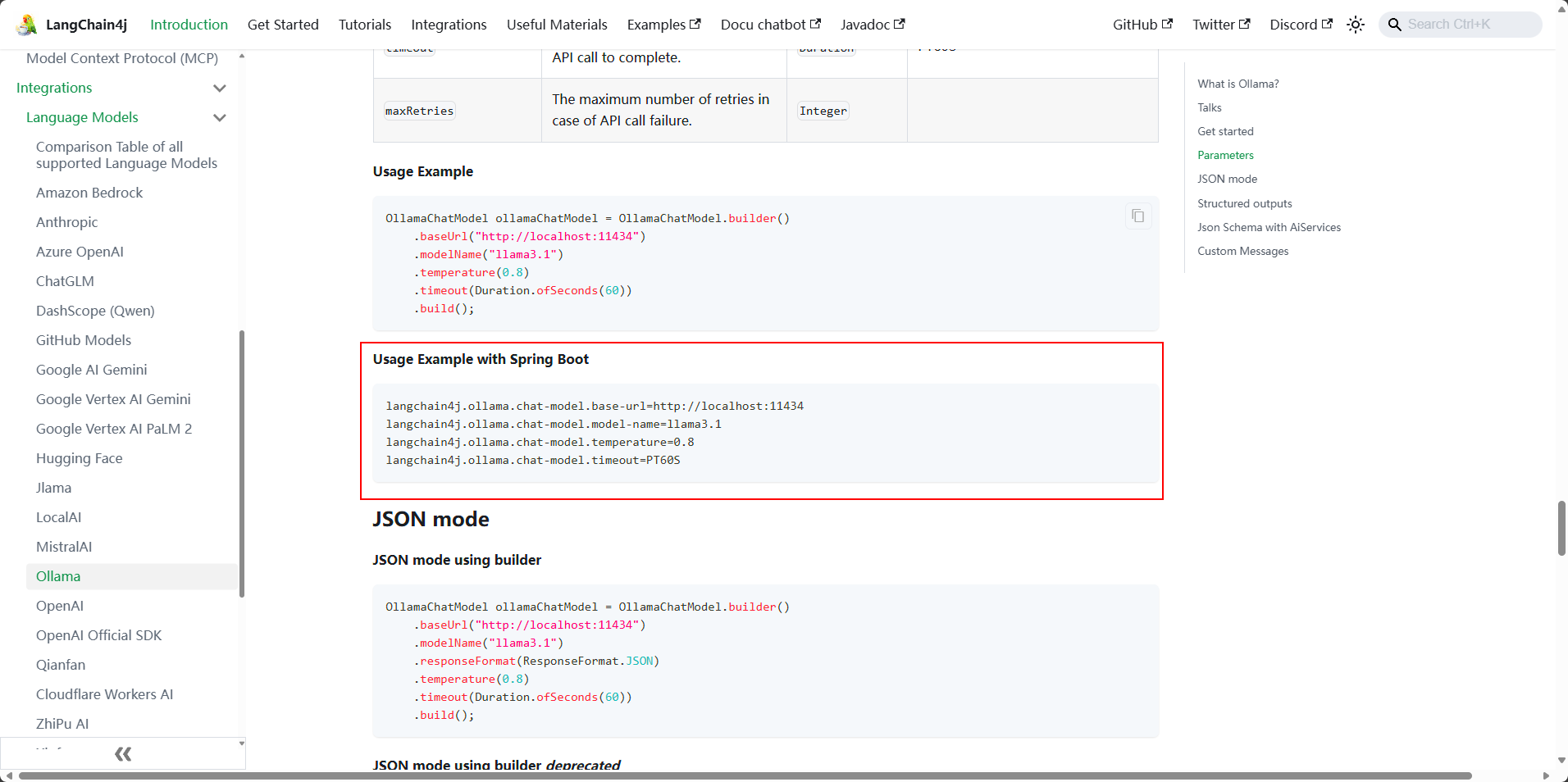
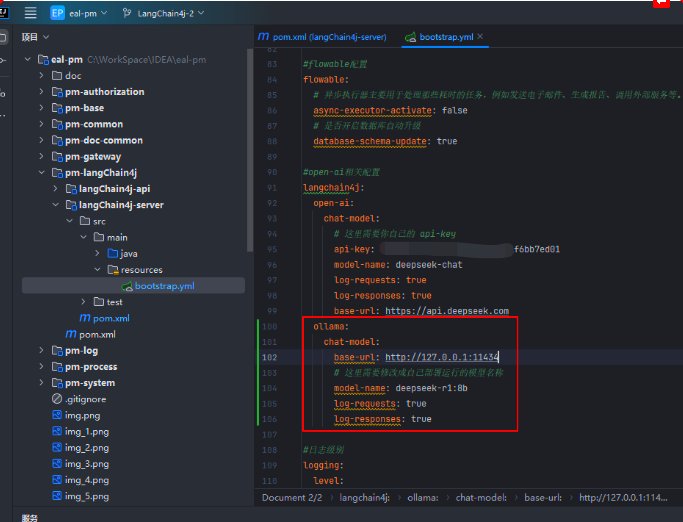
#open-ai相关配置
langchain4j:
open-ai:
chat-model:
# 这里需要你自己的 api-key
api-key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
model-name: deepseek-chat
log-requests: true
log-responses: true
base-url: https://api.deepseek.com
ollama:
chat-model:
base-url: http://127.0.0.1:11434
# 这里需要修改成自己部署运行的模型名称
model-name: deepseek-r1:8b
log-requests: true
log-responses: true③ 创建测试接口
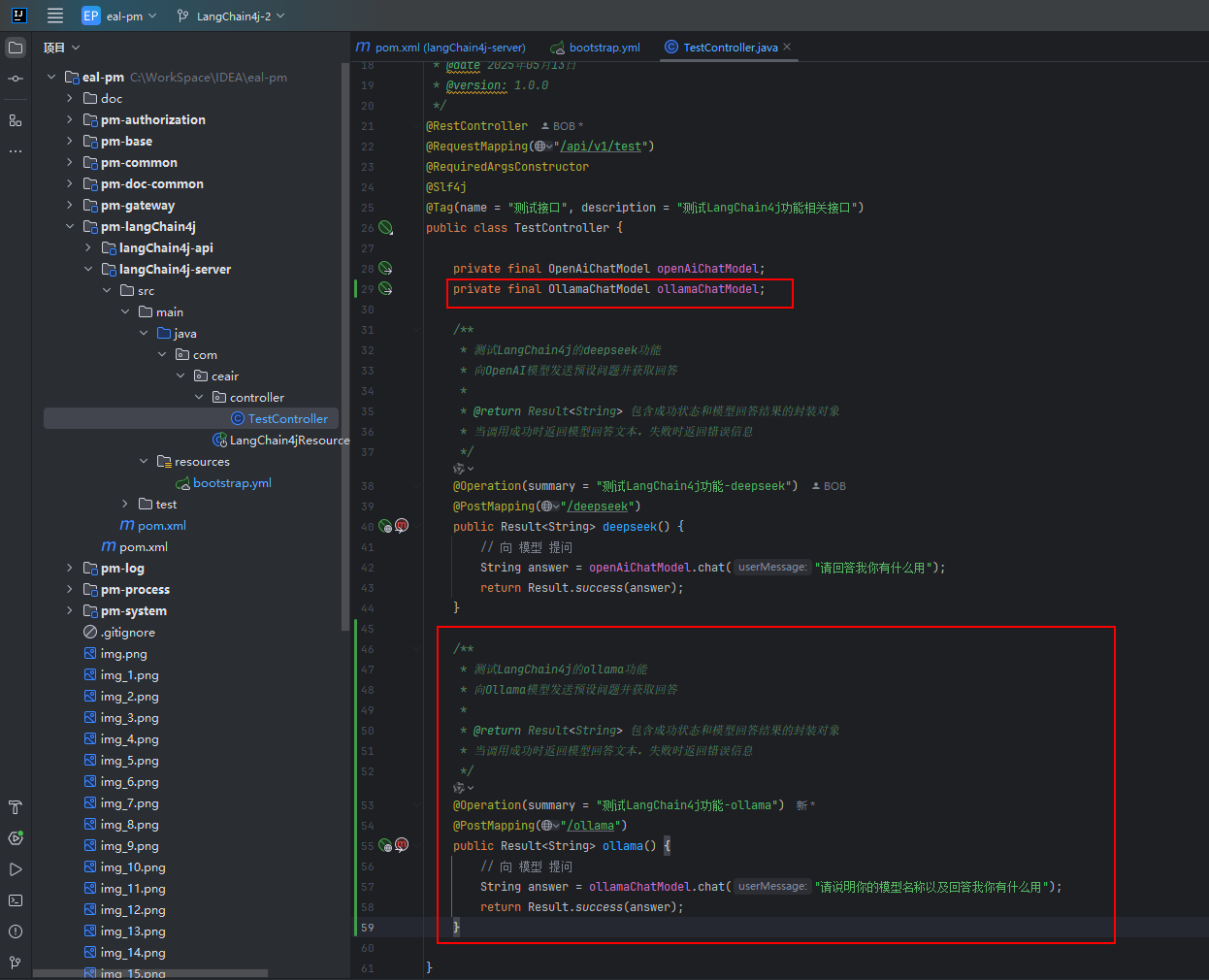
private final OllamaChatModel ollamaChatModel;
/**
* 测试LangChain4j的ollama功能
* 向Ollama模型发送预设问题并获取回答
*
* @return Result<String> 包含成功状态和模型回答结果的封装对象
* 当调用成功时返回模型回答文本,失败时返回错误信息
*/
@Operation(summary = "测试LangChain4j功能-ollama")
@PostMapping("/ollama")
public Result<String> ollama() {
// 向 模型 提问
String answer = ollamaChatModel.chat("请说明你的模型名称以及回答我你有什么用");
return Result.success(answer);
}五、测试接口
本环节直接展示接口调用结果,测试具体步骤请查看专栏第一篇文章的测试章节。
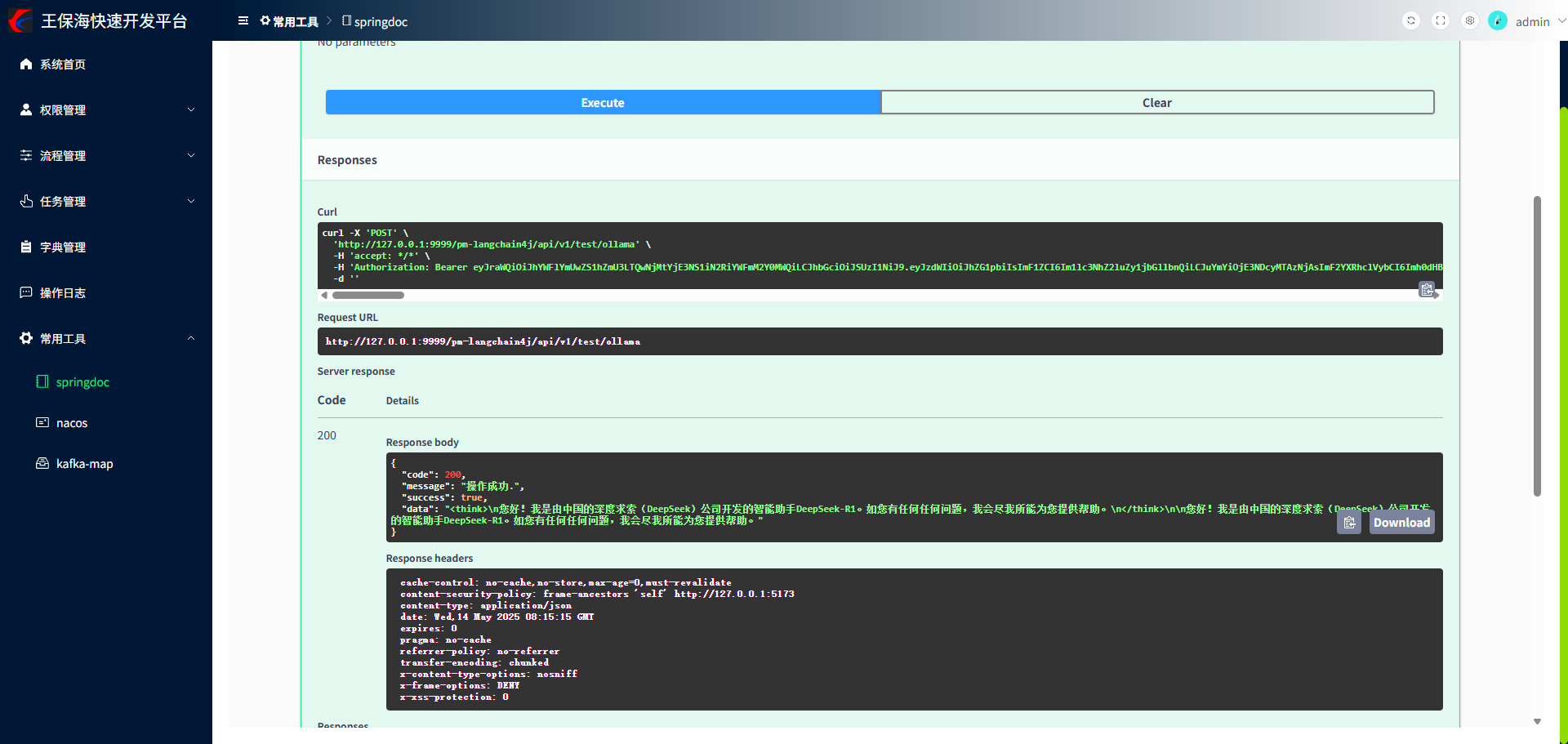
后记
本文完成了ollama安装,部署deepseek-R1 8b蒸馏版本,LangChain4j接口ollama。下一篇文章我们尝试接口阿里百炼的一些其他大模型。
按照一篇文章一个代码分支,本文的后端工程的分支都是 LangChain4j-2,前端工程的分支是 LangChain4j-1。
后端工程仓库:后端工程
前端工程仓库:前端工程

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









