








CVPR 2025 decisions are now available on OpenReview!22.1% = 2878 / 13008
会议官网:https://cvpr.thecvf.com/Conferences/2025
目前计划整理六个合集,部分合集未发布
【合集一】AIGC
【合集二】Mamba、MLLM
【合集三】底层视觉
【合集四】检测与分割
【合集五】三维视觉
【合集六】视频理解
欢迎转载,转载注明出处哦——————————————————————————————————————————————————————————————
Mamba
1.《MambaVision: A Hybrid Mamba-Transformer Vision Backbone》
paper: https://arxiv.org/abs/2407.08083
code: https://github.com/NVlabs/MambaVision
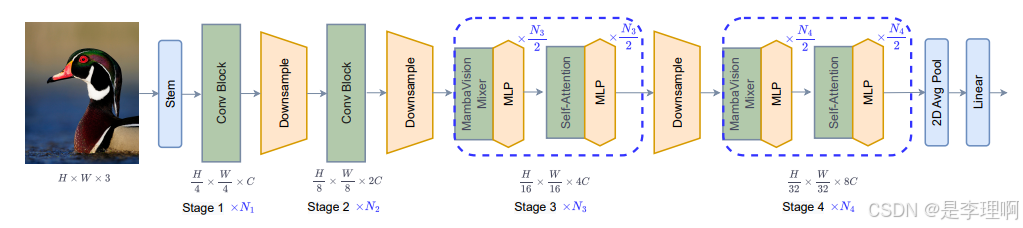
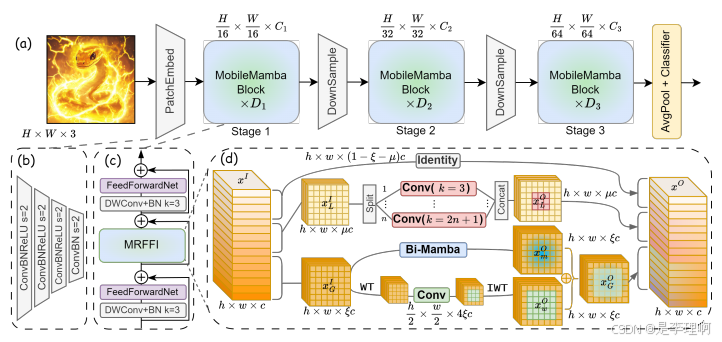
2.《MobileMamba: Lightweight Multi-Receptive Visual Mamba Network》
paper: https://arxiv.org/abs/2411.15941
code: https://github.com/lewandofskee/MobileMamba
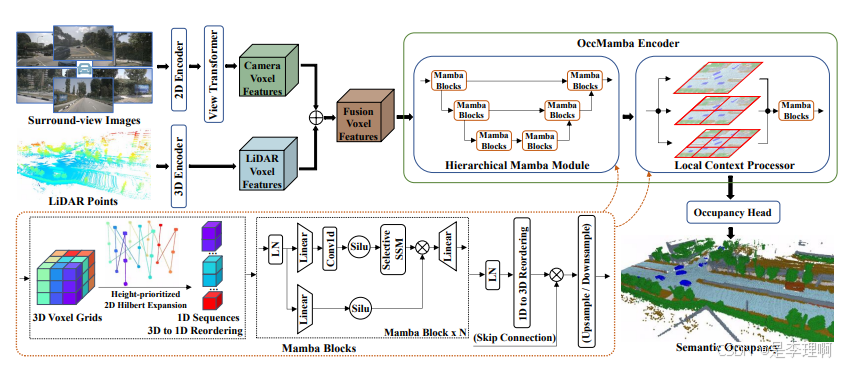
3.《OccMamba: Semantic Occupancy Prediction with State Space Models》
paper: https://arxiv.org/pdf/2408.09859
code: https://github.com/USTCLH/OccMamba
MLLM
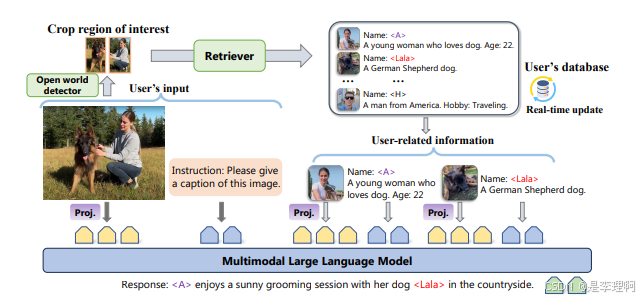
1.《RAP-MLLM: Retrieval-Augmented Personalization for Multimodal Large Language Model》
Paper: https://arxiv.org/abs/2410.13360
Code: https://github.com/Hoar012/RAP-MLLM
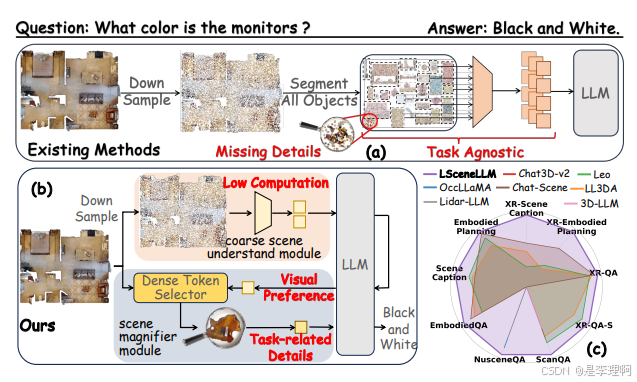
2.《LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences》
Paper: https://arxiv.org/abs/2412.01292
Code: https://github.com/Hoyyyaard/LSceneLLM
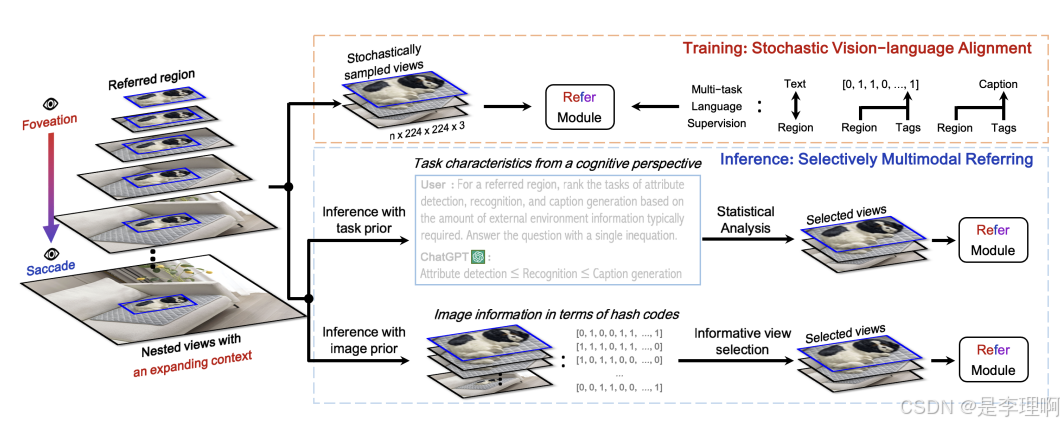
3.《DynRefer: Delving into Region-level Multimodal Tasks via Dynamic Resolution》
DynRefer: Delving into Region-level Multimodal Tasks via Dynamic Resolution
Paper: https://arxiv.org/abs/2405.16071
Code: https://github.com/callsys/DynRefer
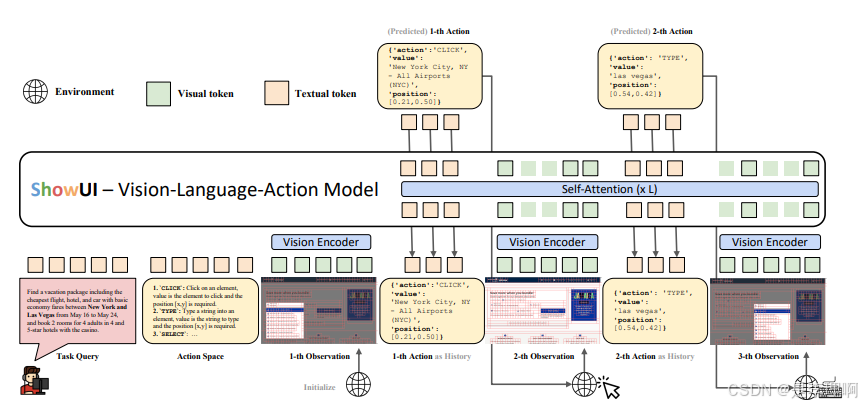
4.《ShowUI: One Vision-Language-Action Model for GUI Visual Agent》
Paper: https://arxiv.org/abs/2411.17465
Code: https://github.com/showlab/ShowUI

















 8604
8604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









