








Title: Attention is all you need
From: NeurIPS 2017
Link: https://arxiv.org/abs/1706.03762
Code: https://github.com/tensorflow/tensor2tensor.
循环神经网络被普遍作为序列建模和转录问题的最佳模型。但是,循环模型(Recurrent models)存在两个问题:(1)其输入输出的顺序计算性阻碍了训练的并行化,序列长度越长,问题越明显。(2)而且随着序列的变长,存在长程依赖的问题。此外,注意力机制允许对依赖关系进行建模,而不考虑他们在输入或输出序列中的距离。这种机制往往和循环网络一起出现。
因此,作者提出Transformer,力图规避掉循环网络,只用attention来实现对输入输出间的全局依赖关系的建模。
重点记录下Transformer中的几个点。
1. Self-attention & Multi-head attention
Attention的三要素:Q、K、V,这三者有可能是一样的,比如你输入的句子序列x,分别乘以三个变换矩 W Q W^Q WQ, W K W^K WK和 W V W^V WV,来作为attention的输入,这种叫做自注意力。在其他情况下,这三者有可能K和V是一样的,也有可能都不一样。
在transformer的编码器中,用的是自注意力,而解码器中,KV是一样的,来自编码器的输出,query是解码器mask attention层的输出。
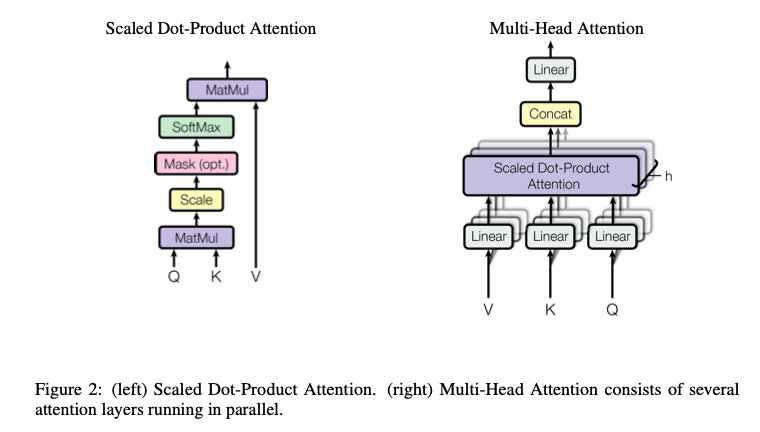
- Scaled dot-product attention
在单头的 Dot-Product Attention中,Q和K做内积来计算相似度,再经过一层softmax,最后的输出就是对 V V V的加权和。
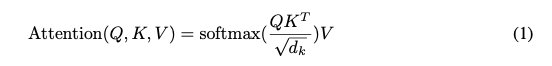
和普通的点积注意力相比,这里多除了一个根号 d k d_k dk,这也是作者为什么将其称为“scaled”。这样做的原因是当 d k d_k dk 比较大的时候,容易把softmax推到梯度较小的地方,缩放后,可以缓解这种情况。
- Mask
再补充一句mask,attention中的mask用于解码的过程。在t时刻,道理上模型应该只能看到0到t-1时刻的output,不然就算是泄漏了。所以在计算后,把t时刻之后的值都变成一个超大的负数,这样经过softmax之后,就趋近于零了,相当于把后面的信息mask掉了。
- Multi-head attention
多头注意力,就类似于卷积里面的多通道,每个通道去识别不同的模式。
对Q、K、V乘以不同的变换矩阵 W i Q W^Q_i WiQ, W i K W^K_i WiK和 W i V W^V_i WiV,将其投影到低维,希望学到不同的投影方法,然后在每个i中,都是原来的scaled dot-product attention,最后将结果拼接起来。(这里的拼接还是加了一个线性层的)。可以认为不同的头,学到的是不同的相似关系/位置关系/。
2. Positional Encoding
Attention是没有时序信息,因为attention的输出是value的加权和,权重是query和key之间的距离,他和序列信息是无关的。也就是说,如果把一句话中所有词的顺序打乱,比如原来的“我爱北京”,换成“北京爱我”,语义肯定是发生了变化的,但是attention对这种变化是感知不到的。所以需要把位置信息加进去,来弥补自注意力机制不能捕捉序列时序信息的缺陷。
RNN是有时序信息的,上一个位置的输出是下一个位置的输入,所以包含了时序信息。
Transformer的思路是通过 sine and cosine 函数把位置信息编码到输入里面。这样编码可以让模型感知到位置的变换。
3. Layer Normalization
batch normalization 是对特征那个维度来做。
layer normalization是对样本那个维度来做。
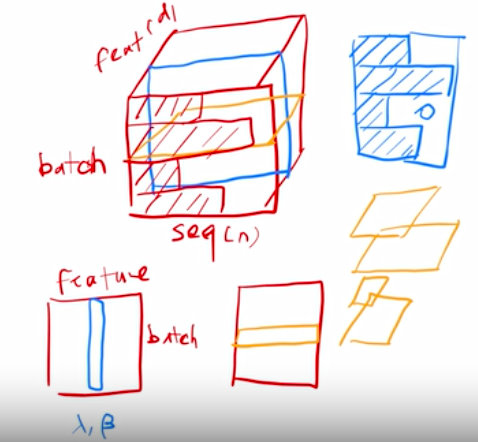 图片源自李沐大佬视频中的截图
图片源自李沐大佬视频中的截图
实验部分,还有一些详细的分析就不写了,今天就到这里吧~
参考:
- https://zhuanlan.zhihu.com/p/420820453
些详细的分析就不写了,今天就到这里吧~
参考:
1.https://zhuanlan.zhihu.com/p/420820453
2.https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0














 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









