






不的不说Transformer文章太多了 干脆一起说吧 先论基础
先说模型的初始化、参数化和标准化等内容

藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。

稳定二阶矩
在之前的文章《从几何视角来理解模型参数的初始化策略》(https://kexue.fm/archives/7180) 中笔者从几何角度分析了已有的初始化方法,大致的思想是特定的随机矩阵近似于一个正交矩阵,从而能保证初始阶段模型的稳定性。不过几何视角虽然有着直观的优点,但通常难以一般化拓展,因此接下来我们还是从代数的角度来理解初始化方法
在一般的教程中,推导初始化方法的思想是尽量让输入输出具有同样的均值和方差,通常会假设输入是均值为0、方差为1的随机向量,然后试图让输出的均值为0、方差为1。不过,笔者认为这其实是没有必要的,而且对于某些非负的激活函数来说,根本就做不到均值为0。事实上,只要每层的输入输出的二阶(原点)矩能保持不变,那么在反向传播的时候,模型每层的梯度也都保持在原点的一定范围中,不会爆炸也不会消失,所以这个模型基本上就可以稳定训练

激活函数

记得2017年时有一篇“轰动一时”的论文《Self-Normalizing Neural Networks》(https://arxiv.org/abs/1706.02515)


直接标准化
当然,相比这种简单的“微调”,更直接的处理方法是各种Normalization方法,如Batch Normalization、Instance Normalization、Layer Normalization等,这类方法直接计算当前数据的均值方差来将输出结果标准化,而不用事先估计积分,有时候我们也称其为“归一化”。这三种标准化方法大体上都是类似的,除了Batch Normalization多了一步滑动平均预测用的均值方差外,它们只不过是标准化的维度不一样,比如NLP尤其是Transformer模型用得比较多就是Layer Normalization是:
其他就不再重复描述了。关于这类方法起作用的原理,有兴趣的读者可以参考笔者之前的 《BN究竟起了什么作用?一个闭门造车的分析》(https://kexue.fm/archives/6992)
这里笔者发现了一个有意思的现象:Normalization一般都包含了减均值(center)和除以标准差(scale)两个部分,但近来的一些工作逐渐尝试去掉center这一步,甚至有些工作的结果显示去掉center这一步后性能还略有提升。
比如2019年的论文《Root Mean Square Layer Normalization》(https://arxiv.org/abs/1910.07467) 比较了去掉center后的Layer Normalization,文章称之为RMS Norm,形式如下:
可以看出,RMS Norm也就是L2 Normalization的简单变体而已,但这篇论文总的结果显示:RMS Norm比Layer Normalization更快,效果也基本一致。
除了这篇文章外,RMS Norm还被Google用在了T5中,并且在另外的一篇文章 《Do Transformer Modifications Transfer Across Implementations and Applications?》(https://arxiv.org/abs/2102.11972) 中做了比较充分的对比实验,显示出RMS Norm的优越性。这样看来,未来RMS Norm很可能将会取代Layer Normalization而成为Transformer的标配。
无独有偶,同样是2019年的论文 《Analyzing and Improving the Image Quality of StyleGAN》(https://arxiv.org/abs/1912.04958)提出了StyleGAN的改进版StyleGAN2,里边发现所用的Instance Normalization会导致部分生成图片出现“水珠”,他们最终去掉了Instance Normalization并换用了一个叫“Weight demodulation”的东西,但他们同时发现如果去掉Instance Normalization的center操作能改善这个现象。这也为Normalization中的center操作可能会带来负面效果提供了佐证。
一个直观的猜测是,center操作,类似于全连接层的bias项,储存到的是关于数据的一种先验分布信息,而把这种先验分布信息直接储存在模型中,反而可能会导致模型的迁移能力下降。所以T5不仅去掉了Layer Normalization的center操作,它把每一层的bias项也都去掉了。
NTK参数化
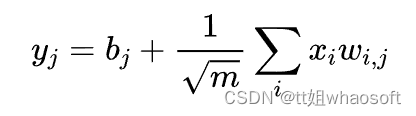
这在高斯过程中被称为“NTK参数化”,可以参考的论文有 《Neural Tangent Kernel: Convergence and Generalization in Neural Networks》、《On the infinite width limit of neural networks with a standard parameterization》 等。不过对于笔者来说,第一次看到这种操作是在PGGAN的论文 《Progressive Growing of GANs for Improved Quality, Stability, and Variation》 中。
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
https://arxiv.org/abs/1806.07572
On the infinite width limit of neural networks with a standard parameterization
https://arxiv.org/abs/2001.07301
Progressive Growing of GANs for Improved Quality, Stability, and Variation
https://arxiv.org/abs/1710.10196
很显然,利用NTK参数化,我们可以将所有参数都用标准方差初始化,但依然保持二阶矩不变,甚至前面介绍的“微调激活函数”,也可以看成是NTK参数化的一种。一个很自然的问题是:NTK参数化跟直接用Xavier初始化相比,有什么好处吗?

残差连接

递归下去,我们得到
看到问题了没?本来残差的意思是给前面的层搞一条“绿色通道”,让梯度可以更直接地回传,但是在Post Norm中,这条“绿色通道”被严重削弱了,越靠近前面的通道反而权重越小,残差“名存实亡”,因此还是不容易训练。相关的分析还可以参考论文 《On Layer Normalization in the Transformer Architecture》(https://arxiv.org/abs/2002.04745)
一个针对性的改进称为Pre Norm,它的思想是“要用的时候才去标准化”,其形式为
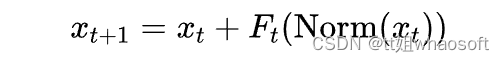
类似地,迭代展开之后我们可以认为初始阶段有

Batch Normalization Biases Residual Blocks Towards the Identity Function in Deep Networks
https://arxiv.org/abs/2002.10444
ReZero is All You Need: Fast Convergence at Large Depth
https://arxiv.org/abs/2003.04887

上面说完了 下面又带来了一个神器
超轻量级的实时增强网络IAT开源,使用全监督训练范式,网络总体的参数量仅需90K+,用来探索实时的暗光增强和曝光矫正,以及一系列不良光照场景下的视觉任务(如暗光场景目标检测/ 语义分割)
Title: You Only Need 90K Parameters to Adapt Light: A Light Weight Transformer for Image Enhancement and Exposure Correction
论文链接: https://arxiv.org/abs/2205.14871
代码链接: https://github.com/cuiziteng/Illumination-Adaptive-Transformer
我们提出Illumination-Adaptive-Transformer (IAT)网络,用来探索实时的暗光增强和曝光矫正,以及一系列不良光照场景下的视觉任务(如暗光场景目标检测/ 语义分割)。IAT网络是全监督训练范式,网络总体的参数量仅需 90k+ ,属于超轻量级的实时增强网络(相比近期CVPR 2022的Transformer工作Restormer[1]和MAXIM[2]等),在这篇论文中,我们借鉴了目标检测中的DETR[3] 结构,来帮助我们实现轻量设计。值得一提的是,IAT网络的训练/测试代码都已经公布,非常容易follow,并且暗光场景下语义分割和目标检测的代码也全部公布,可以说是良心满满。
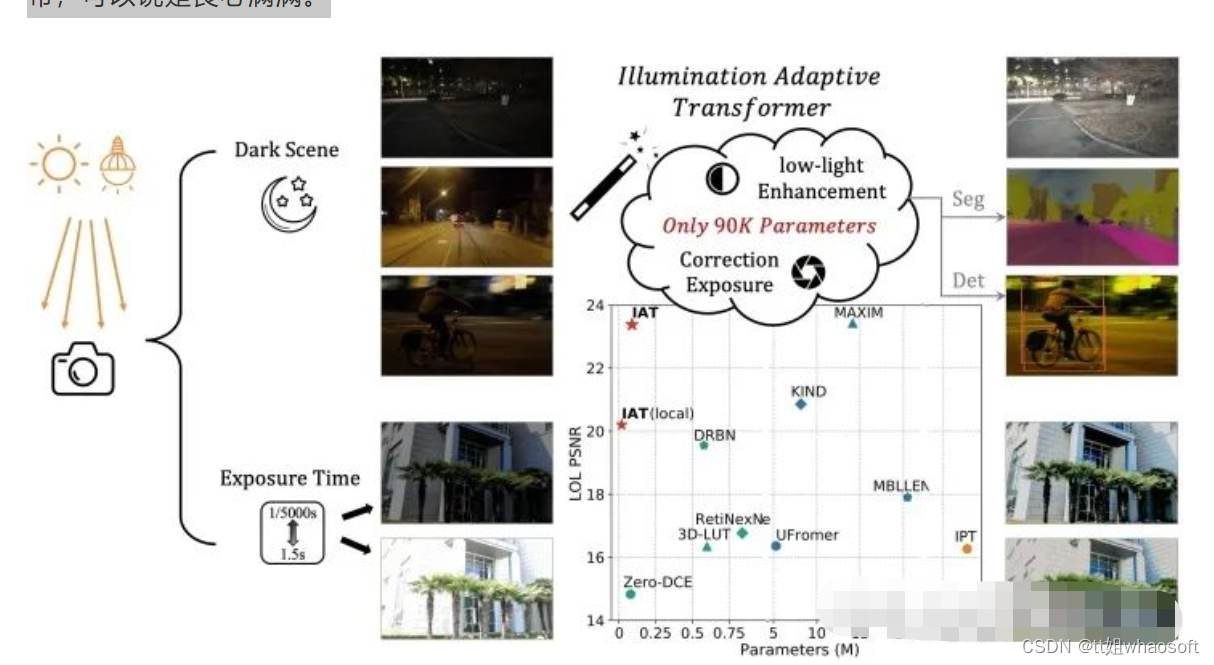
自然场景下存在着各种不良光照场景,如低光照环境和摄影造成的过(欠)曝光环境,相机在不良光照下完成摄影任务时,因为接收到过多/过少的光子数量,和相机内部的处理过程 (如低光照场景需要调高ISO,这会导致噪声也同时放大)。往往得到的图像也会收到影响,无论从视觉感观还是完成一些视觉任务(如检测,分割等)都会受到影响。区别于传统的HE或者RetiNex做法以及此前的CNN做法,我们提出了Illimination-Adaptive-Transformer (IAT), IAT模型借鉴了目标检测网络DETR思路,通过动态query学习的机制来调整计算摄影中的一些相关参数,建立了一个end-to-end的Transformer,来克服这些不良光照所造成的视觉感观/视觉任务影响。
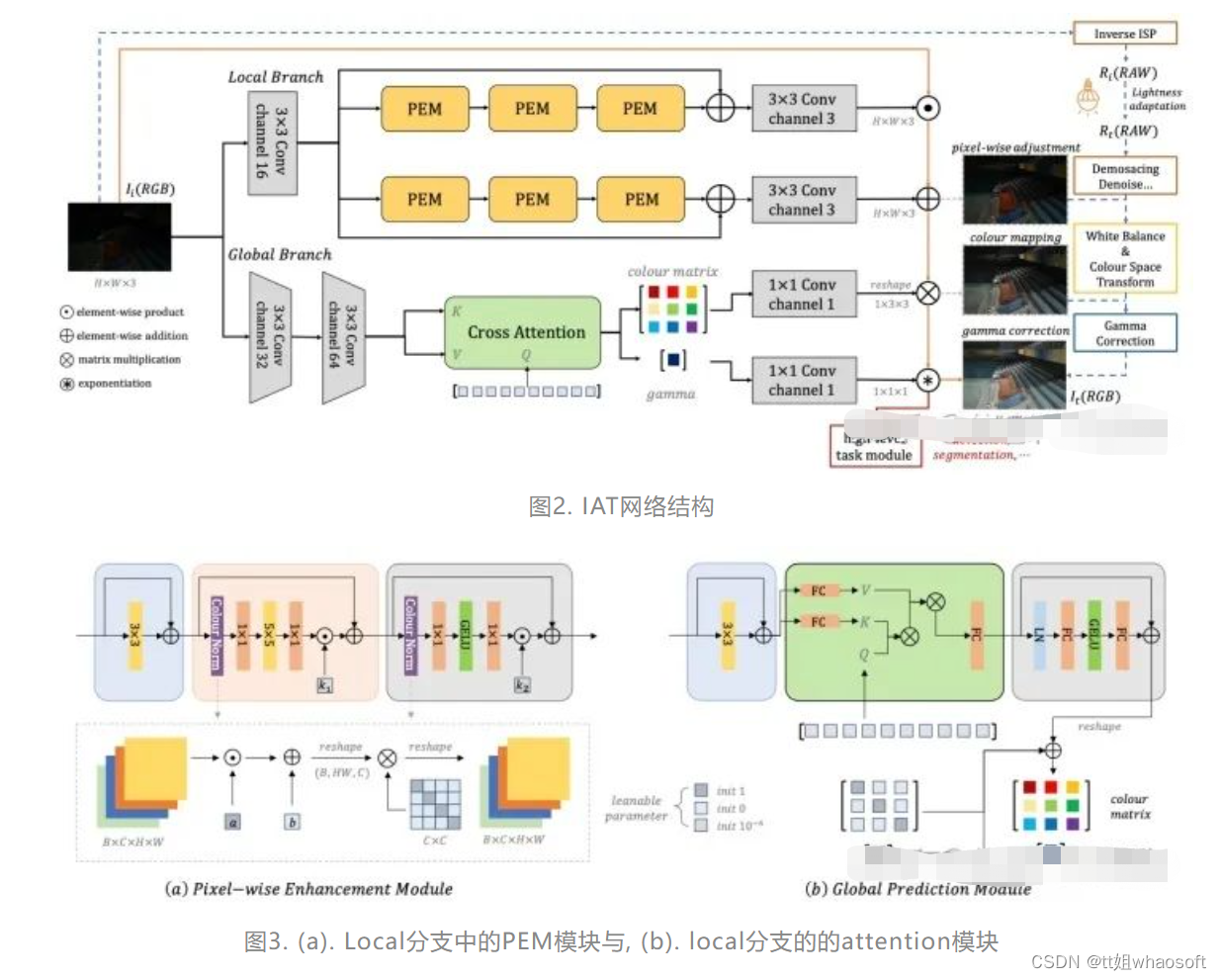
网络结构:

同时在global分支我们采用attention模块来获得全局信息来产生色彩矩阵以及gamma数值,受到了目标检测DETR网络的启发,我们将随机初始化的query输入到模块中,与图像自身生成的key和value共同作用,最终输出十个参数,分别代表3x3的色彩矩阵和1维的gamma数值,通过这样的动态query学习策略,随着epoch的更新,网络可以自适应的调整操控图像全局信息的色彩矩阵以及gamma值,同时可以更好的利用transformer擅长捕捉全局信息的特性。我们设计的色彩矩阵与gamma数值都是针对每张图像进行调整,相当于给每张图像都假定一个专属的特定gamma数值与色彩矩阵来完成增强任务,曝光矫正任务以及后续的高层次视觉任务。
实验结果 (低光照增强/曝光纠正):
在实验部分,我们做了大量的实验,包括低光照增强/ 曝光纠正,以及低光照场景下的目标检测,低光照场景下的语义分割,以及复杂光照场景下的目标检测。
(a). 低光照增强实验结果(LOL-V1数据集低光照增强, 485 image training, 15 image testing和LOL-V2-real数据集低光照增强, 589 image training, 100 image testing).
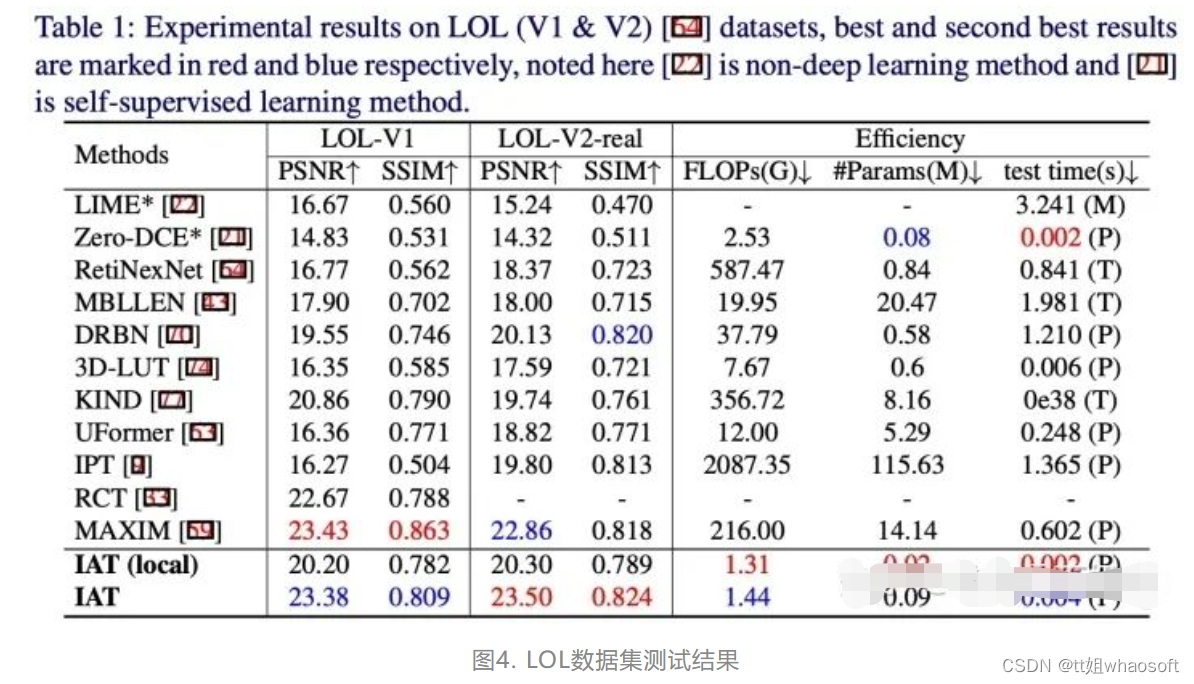
网络训练时采用L1损失函数,可以看出IAT在暗光增强上面的性能达到SOTA,并且参数量,FLOPS和速度相比之前算法都非常少,时效性很好,一些视觉效果如下:

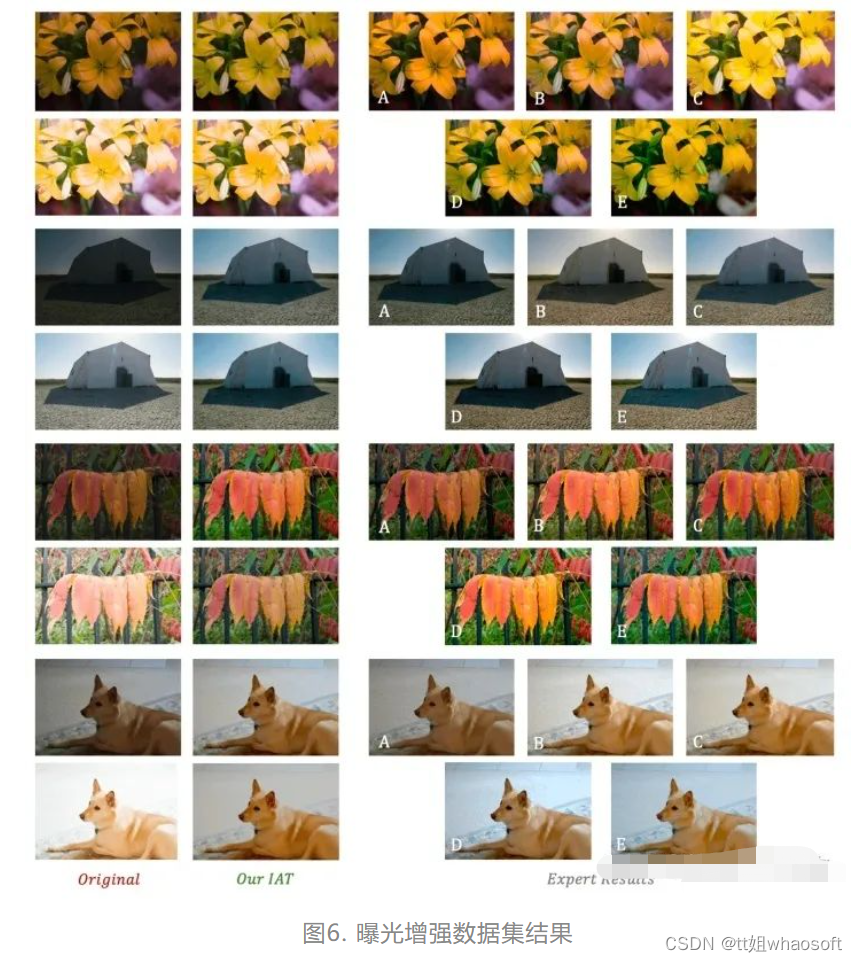
(b). 曝光纠正实验结果 [同时欠曝光/ 过曝光](Exposure数据集曝光纠正):
实验结果 (低光照检测/分割):
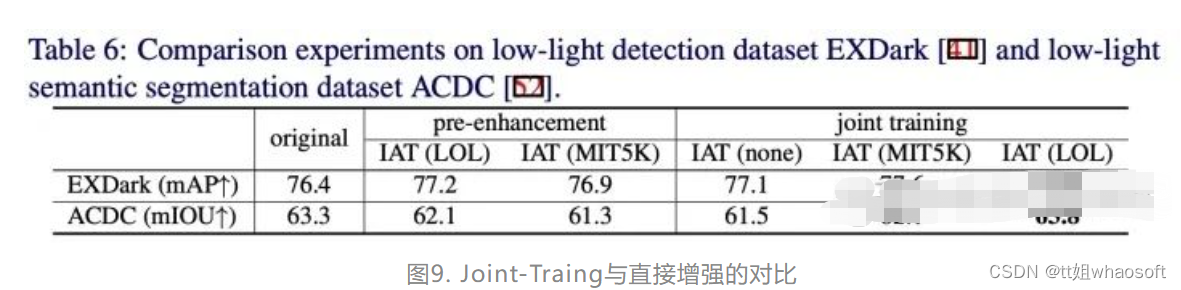
在低光照检测/分割任务上,我们首先探究了将图像增强直接作用到暗光图像上,然后将增强后的图像输入到检测/分割网络结构中,我们分别采用了低光照检测数据集EXDark和低光照分割数据集ACDC以及多光源场景检测数据集TYOL,我们以YOLO-V3检测器为范例,在目标检测时采用COCO预训练模型上面训练不同增强算法增强后的EXDark和TYOL,在语义分割时采用City-scape预训练模型训练不同增强算法增强后的ACDC,结果如下:
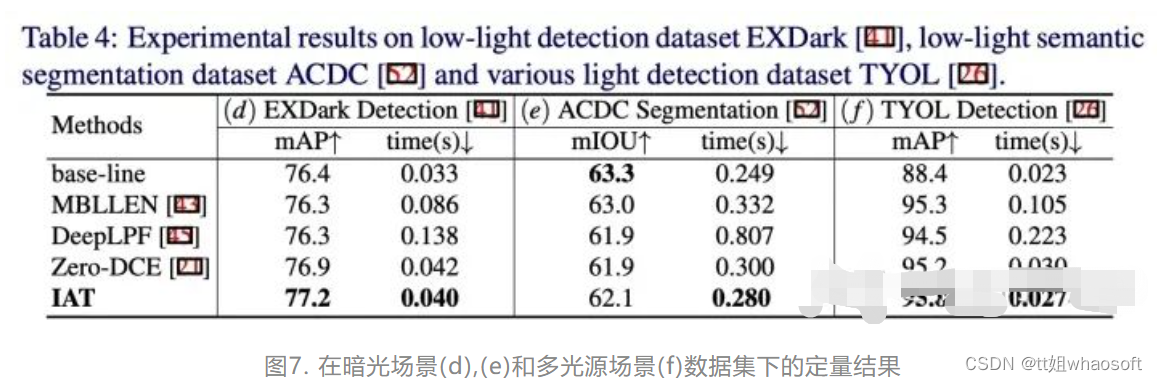
可以看出低光照增强方法对于目标检测任务有些许提升,但是在后续的语义分割任务(e)上,增强算法反而无法提升目标的分割性能,这是由于图像增强算法与高层视觉算法的目的与评价指标不一致所导致的,图像增强是为了更好提升人眼视觉(评价指标PSNR,SSIM),而目标检测和语义分割属于机器视觉(评价指标mIOU, mAP)。
针对于这种情况,我们采用了joint-training范式来训练网络,即将图像增强网络和后续检测分割网络联合,一起更新参数,其中图像增强网络还可以加载不同的预训练模型(如LOL数据集预训练和MIT-5K数据集预训练),图示如下:
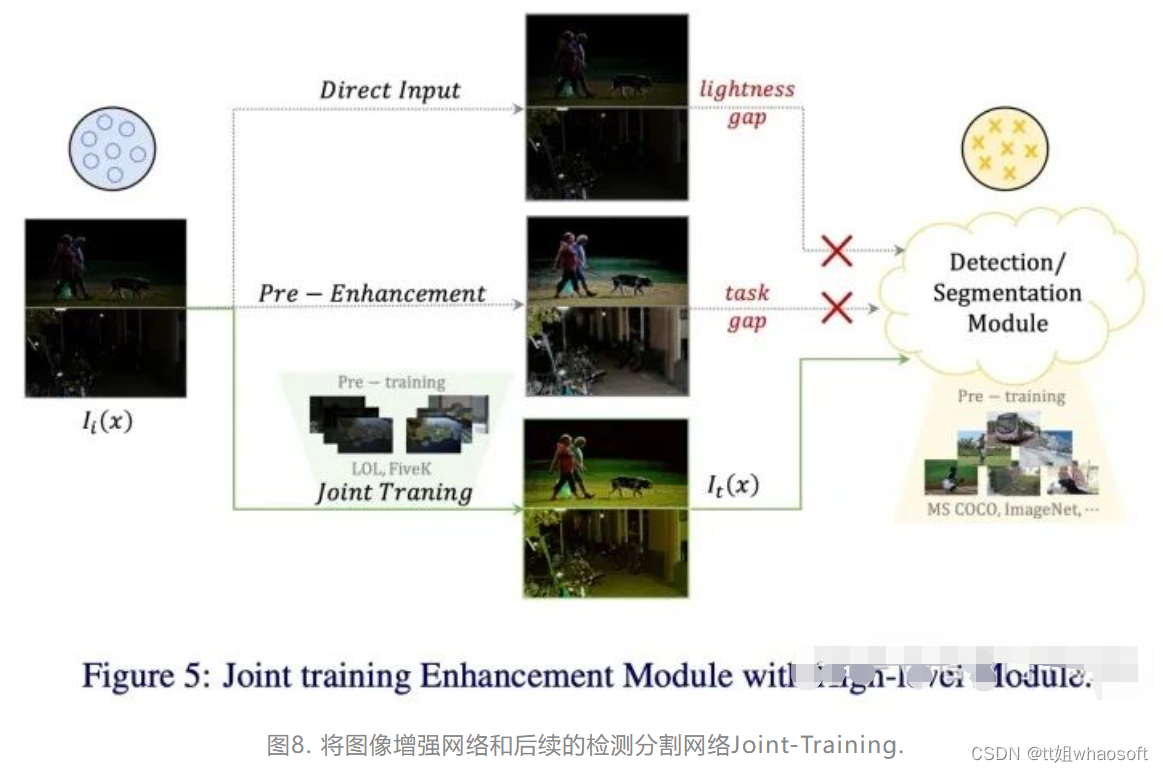
通过实验结果发现,Joint-training范式可以有效提升低光照场景下的检测/分割结果,引入了Joint-training和直接增强的方法对比如下,可以看到Joint-training更能有效提升性能:















 40万+
40万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









