







文章目录
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
Summary
-
每个patch位置都用高斯分布描述,异常描述就是测试feature与高斯分布的距离
-
考虑了CNN不同层的语义关联
Method(s)
Embedding extraction
数据采用mvtec格式的数据,共有100张训练图片。
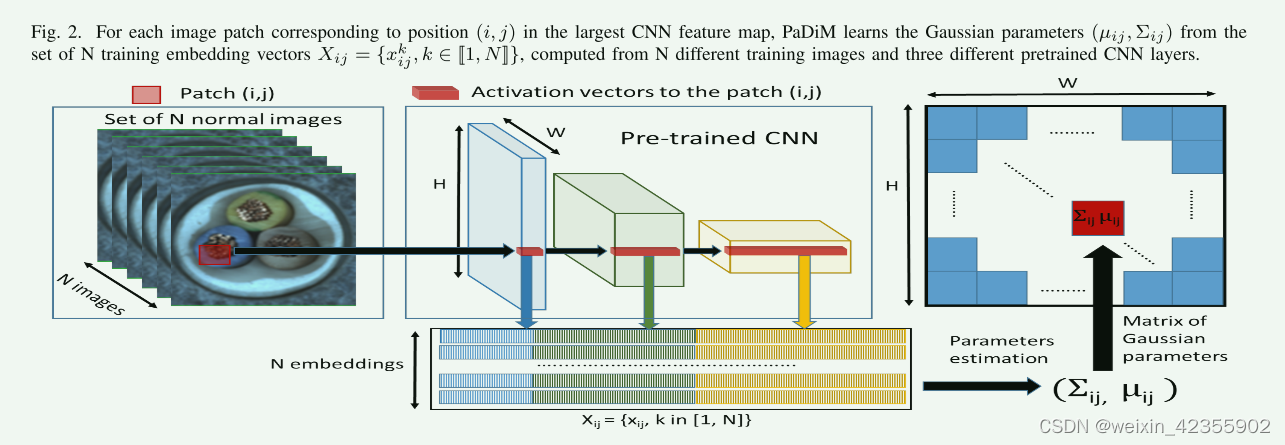
将预训练模型中三个不同层的feature map对应位置进行拼接得到embedding,这里分别取wide_resnet50_2中layer1、layer2、layer3的最后一层,模型输入大小为224x224,取得train_outputs包含(100,256,56,56)、(100,512,28,28)、(100,1024,14,14),这里同一个patch对应不同层的56x56,28x28,14x14,在处理中是将小特征图放大,56x56中2x2patch对应28x28中的1x1patch复制四份cat起来
embedding_vectors = train_outputs['layer1'] # (100,256,56,56)
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, train_outputs[layer_name])
############################################
#解析
def embedding_concat(x, y):
B, C1, H1, W1 = x.size() # (100,256,56,56)
_, C2, H2, W2 = y.size() # (100,512,28,28)
s = int(H1 / H2) # kernel_size,stride:2
x = F.unfold(x, kernel_size=s, dilation=1, stride=s) #膨胀系数,默认为 1;([100, 256x2x2, 28x28]);输出的 x 将是一个二维矩阵,其形状为 [C * kernel_size * kernel_size, num_patches],其中 num_patches 是提取的patch数量:
x = x.view(B, C1, -1, H2, W2) #(100,256,4,28,28)
z = torch.zeros(B, C1 + C2, x.size(2), H2, W2) #(100,768,4,28,28)
for i in range(x.size(2)):
z[:, :, i, :, :] = torch.cat((x[:, :, i, :, :], y), 1) # cat((100,256,28,28),(100,512,28,28))->(100,768,i,28,28)
z = z.view(B, -1, H2 * W2)# (100,3072,784)
z = F.fold(z, kernel_size=s, output_size=(H1, W1), stride=s) # (100,768,56,56)
return z
生成的补丁嵌入向量(100,768,56,56)可能携带冗余信息,文章认为随机选择几个维度比经典的主成分分析(PCA)算法更有效,代码中d=550
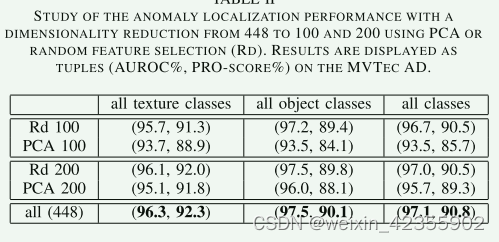
embedding_vectors = torch.index_select(embedding_vectors, 1, idx) # 随机选择embedding,(100,768,56,56)->(100,550,56,56)
Learning of nomality
为了学习位置 (i, j) 处的正常图像特征,我们首先从 N 张正常训练图像中计算出位置 (i, j) 处的embeding为 X i j = { x i j k , k ∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









