







参考:https://www.jianshu.com/p/fc52d6468304
https://www.jb51.net/article/222344.htm

apply、transform区别:
groupby() 之后,如果是使用 apply() 或者直接使用某个统计函数,得到的新列的长度与分组得到的组数是一样的;而如果使用 transform() ,得到的新列与 DataFrame 中列的长度是一样的。
import pandas as pd
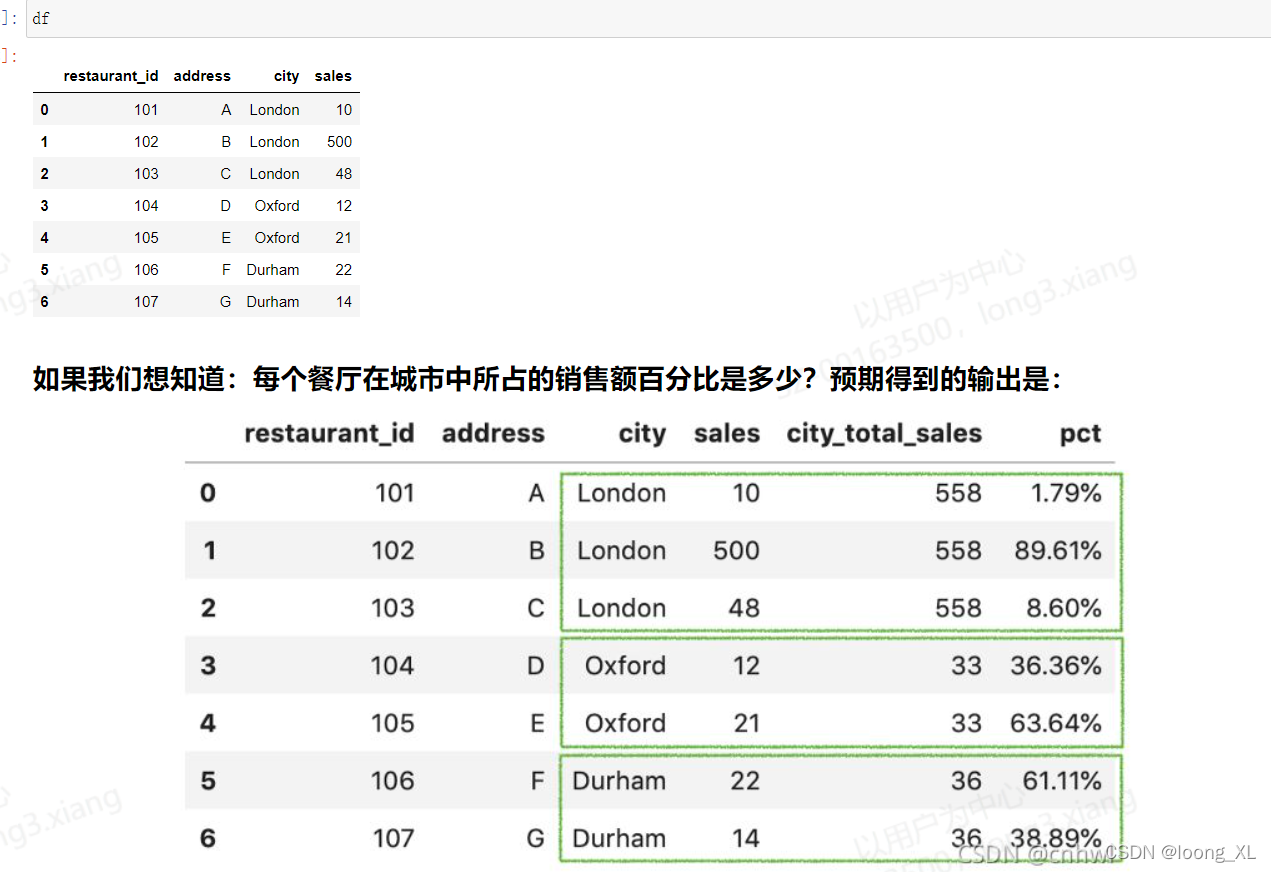
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})
1、apply
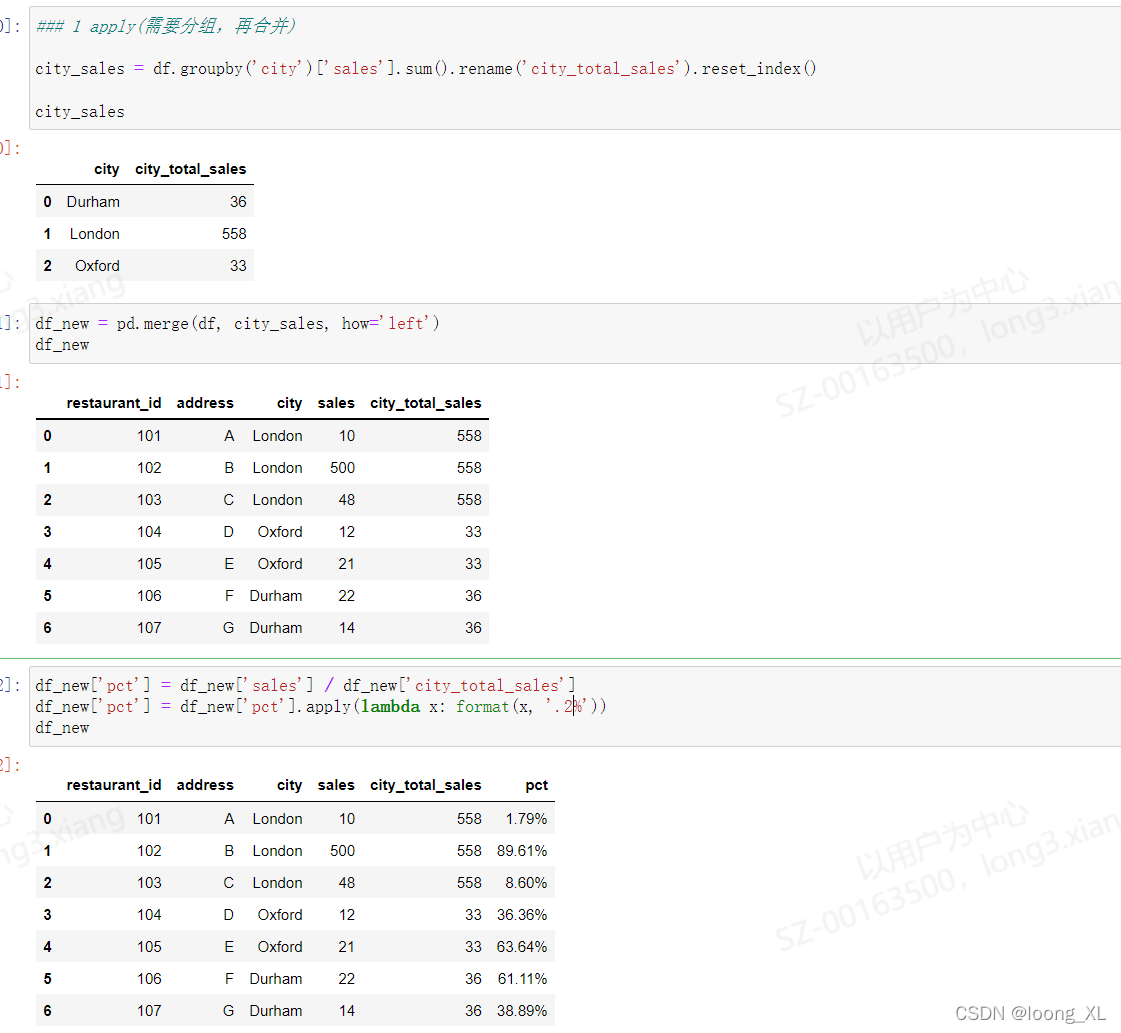
### 1 apply(需要分组,再合并)
city_sales = df.groupby('city')['sales'].sum().rename('city_total_sales').reset_index()
#保留原数组需要与原数组结合合并
df_new = pd.merge(df, city_sales, how='left')
df_new['pct'] = df_new['sales'] / df_new['city_total_sales']
df_new['pct'] = df_new['pct'].apply(lambda x: format(x, '.2%'))
df_new
2、transform
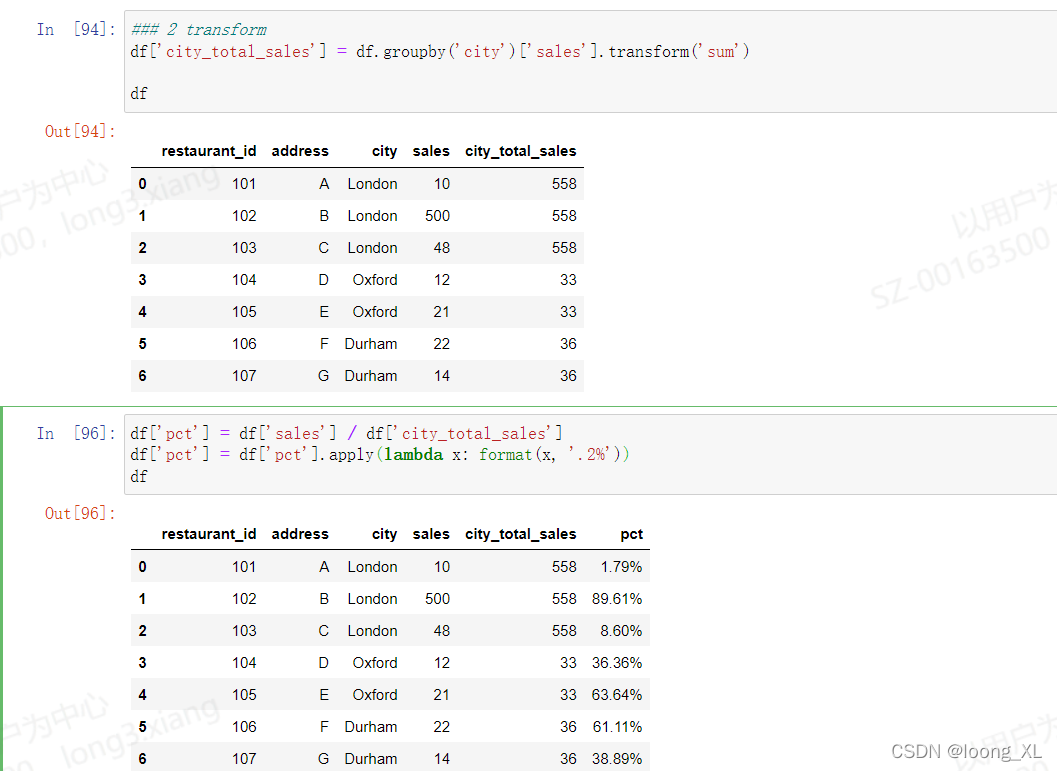
### 2 transform
df['city_total_sales'] = df.groupby('city')['sales'].transform('sum')
df['pct'] = df['sales'] / df['city_total_sales']
df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
df


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











