







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
数据下载
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
一、项目背景
该项目旨在构建一个基于Pandas和TOPSIS(Technique for Order Preference by Similarity to an Ideal Solution)多准则决策分析方法的新能源汽车推荐模型。
通过收集和整理新能源汽车的各项指标数据,如续航里程、充电时间、价格、车内空间、安全性等,利用Pandas对数据进行清洗、标准化处理,并应用TOPSIS方法对各个指标进行综合评分,从而为消费者提供客观、科学的车型推荐。该模型能够帮助用户在多种选车条件下,快速找到最符合其需求的新能源汽车,为消费者的购车决策提供有效支持。
二、数据描述
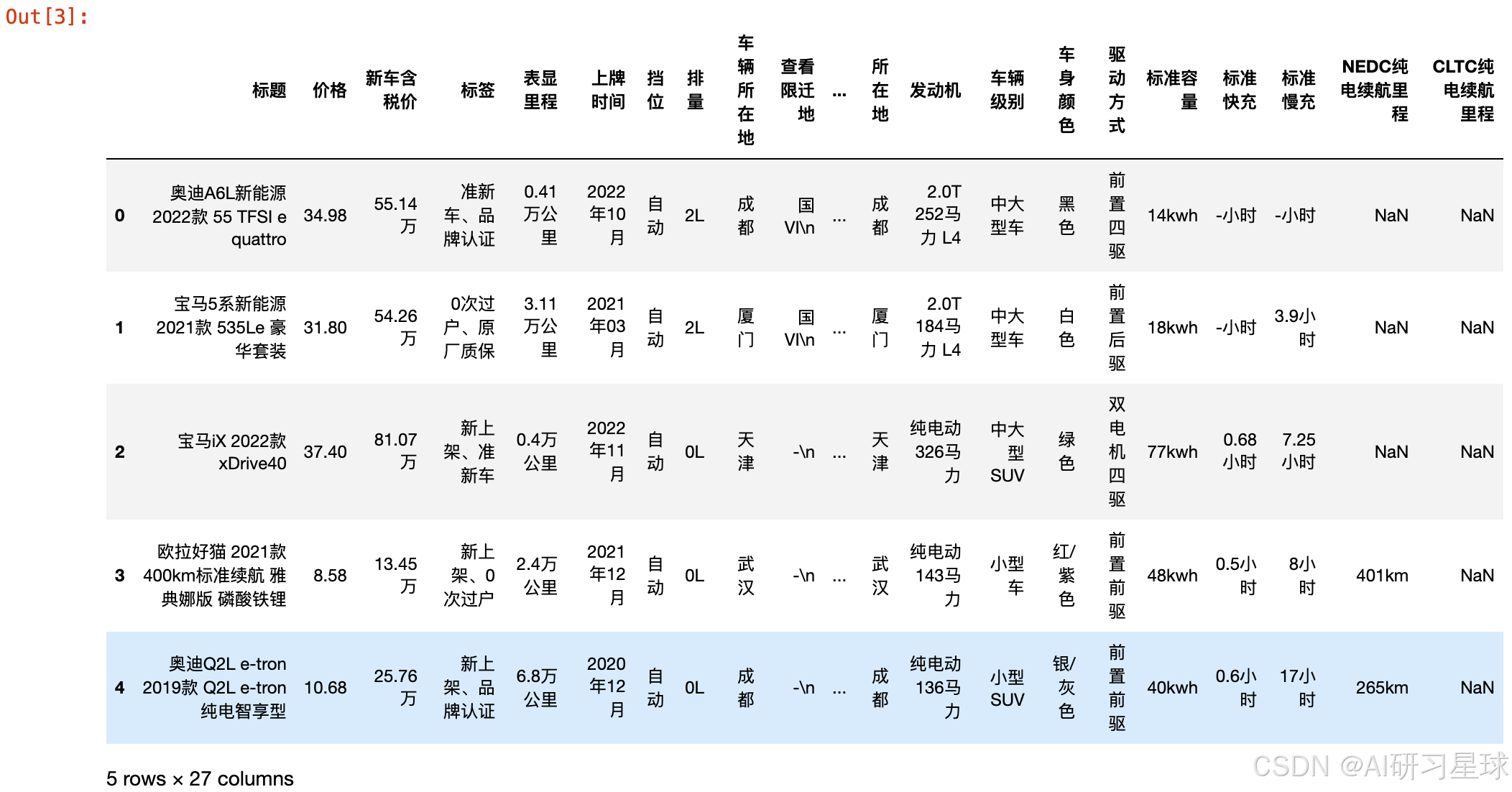
该数据共2万多条,共27个字段。
以下是表的部分数据

三、数据处理
导入数据科学库
import pandas as pd
import numpy as np
1、数据读取与预处理
#读取新能源汽车数据集
df=pd.read_excel('汽车之家数据.xlsx')
#去除重复值
df.drop_duplicates(subset=['标题'],inplace=True)
#数据概览,其包括汽车型号,价格,挡位,排量,颜色,驱动方式等一系列字段
df.head(5)
2、AHP法确定指标权重
a、第一步:定义特征列表
主要选择【价格,排量,NEDC纯电续航里程】等特征来进行建模
#主要选择【价格,排量,NEDC纯电续航里程】等特征来进行建模
features=['价格', '排量', 'NEDC纯电续航里程']
b、第二步:创建判别矩阵
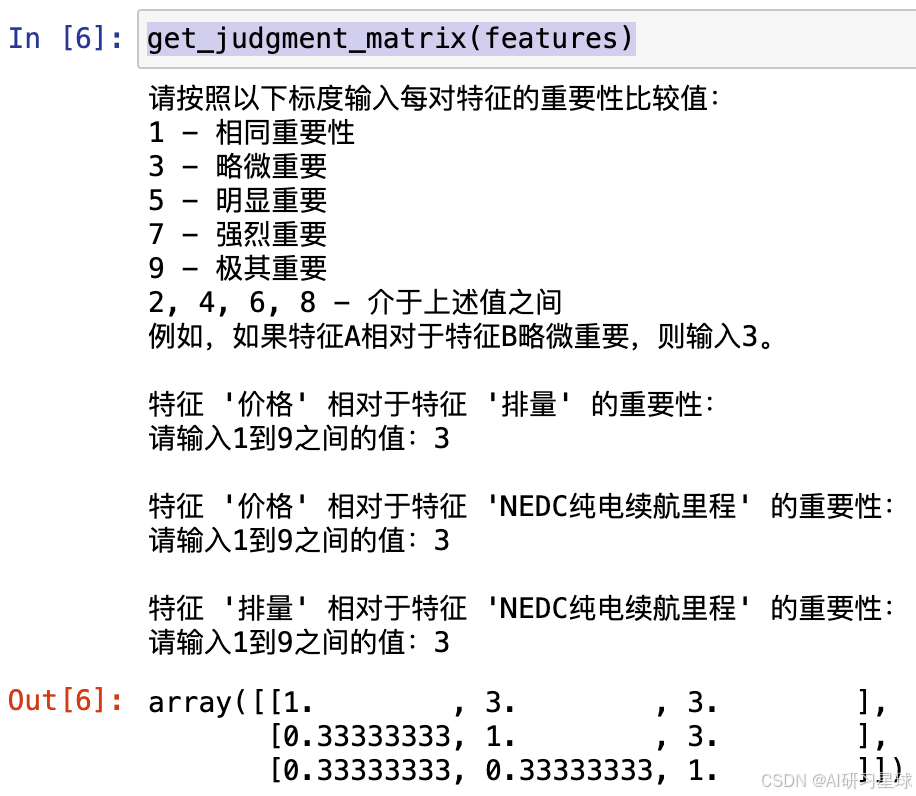
根据特征列表,提示用户逐对比较每两个特征的重要性。用户需要根据以下标度输入每对特征的相对重要性:
1:两个特征同等重要
3:第一个特征略微重要于第二个特征
5:第一个特征明显重要于第二个特征
7:第一个特征强烈重要于第二个特征
9:第一个特征极其重要于第二个特征
2, 4, 6, 8:介于上述值之间
def get_judgment_matrix(features):
"""
获取判断矩阵,通过用户输入的形式逐对比较特征的重要性
:param features: 特征列表
:return: 判断矩阵 (n x n)
"""
n = len(features)
matrix = np.ones((n, n)) # 初始化为单位矩阵
print("请按照以下标度输入每对特征的重要性比较值:")
print("1 - 相同重要性")
print("3 - 略微重要")
print("5 - 明显重要")
print("7 - 强烈重要")
print("9 - 极其重要")
print("2, 4, 6, 8 - 介于上述值之间")
print("例如,如果特征A相对于特征B略微重要,则输入3。")
for i in range(n):
for j in range(i + 1, n):
print(f"\n特征 '{features[i]}' 相对于特征 '{features[j]}' 的重要性:")
value = float(eval(input(f"请输入1到9之间的值:")))
matrix[i, j] = value
matrix[j, i] = 1 / value # 互反关系
return matrix
get_judgment_matrix(features)
c、第三步:计算权重向量
def ahp_weight_calculation(matrix):
"""
计算AHP权重和一致性比率
:param matrix: 判断矩阵 (n x n)
:return: 权重向量, 一致性比率CR
"""
#1。计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(matrix)
# 2.找到最大特征值的索引
max_eigenvalue_index = np.argmax(eigenvalues)
# 3。获取最大特征值
max_eigenvalue = eigenvalues[max_eigenvalue_index]
# 4.获取对应的特征向量
max_eigenvector = eigenvectors[:, max_eigenvalue_index]
#权重归一化
weights = max_eigenvector / np.sum(max_eigenvector)
return weights, max_eigenvalue_index
d、第四步:一致性检验
根据特征数量查找随机一致性指标RI并计算一致性比率CR,CR<0.1即通过一致性检验
def consistency_check(matrix, max_eigenvalue):
# 1. 计算一致性指标CI
n = matrix.shape[0]
CI = (max_eigenvalue - n) / (n - 1)
# 2. 计算一致性比率CR
RI_dict = {1: 0.00, 2: 0.00, 3: 0.58, 4: 0.90, 5: 1.12,
6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45, 10: 1.49}
RI = RI_dict.get(n, 1.49) # 如果n>10,默认为1.49
CR = CI / RI
return CR
新能源汽车特征权重构建(完整流程)
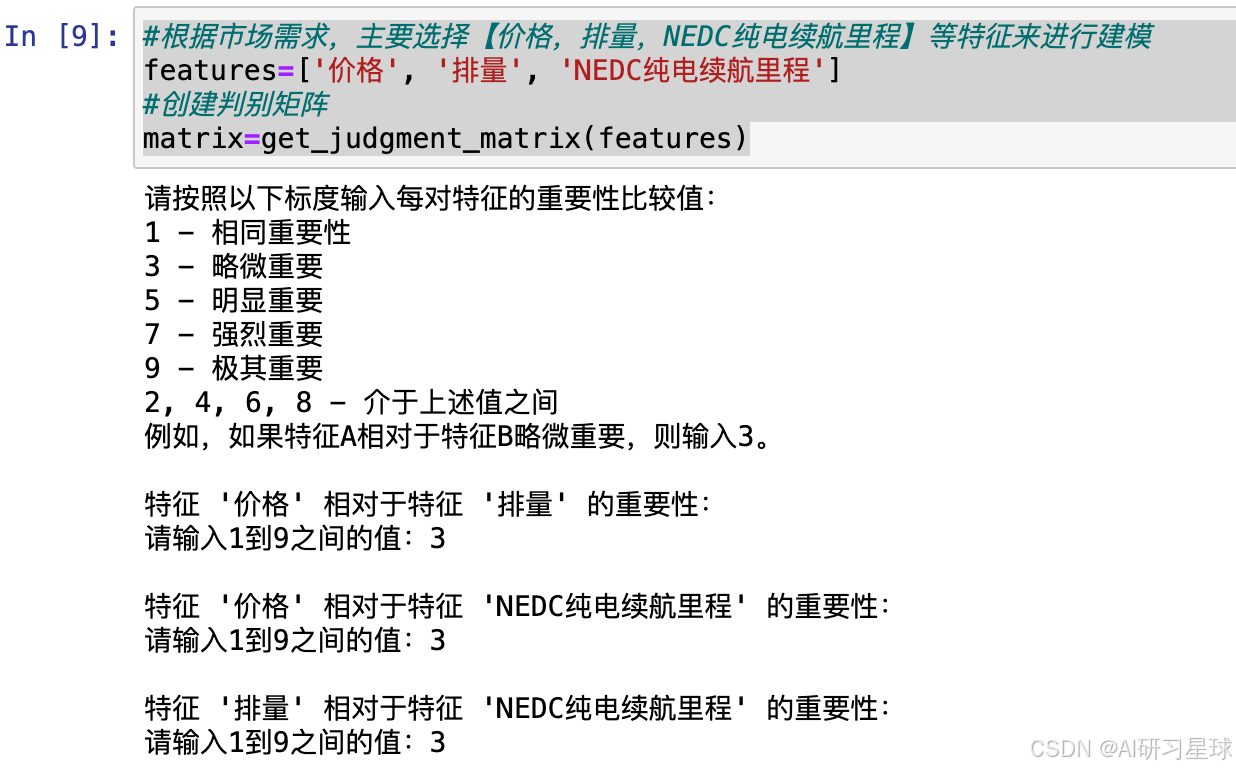
#根据市场需求,主要选择【价格,排量,NEDC纯电续航里程】等特征来进行建模
features=['价格', '排量', 'NEDC纯电续航里程']
#创建判别矩阵
matrix=get_judgment_matrix(features)
#计算特征根和特征向量
weights, max_eigenvalue=ahp_weight_calculation(matrix)
#计算一致性比率
CR=consistency_check(matrix, max_eigenvalue)
if CR<0.1:
print('该判断矩阵通过一致性检验,已存储为comparison_matrix.npy')
#存储通过一致性检验的判别矩阵,以便于后续直接调用
np.save('comparison_matrix.npy', matrix)
else:
print('该判断矩阵一致性检验未通过,请重新调整权重')
该判断矩阵通过一致性检验,已存储为comparison_matrix.npy
3、TOPSIS综合评分
a、数据清洗
#根据市场需求,主要选择【价格,排量,NEDC纯电续航里程】等特征来进行建模
features=['价格', '排量', 'NEDC纯电续航里程']
# 根据评价指标读取对应数据
data=df[features].copy()
#设置索引为车辆名称
data.index=df['标题']
# 定义单位去除函数
def remove_units(value):
return float(''.join(filter(str.isdigit, value)))
# 对字符字段应用函数
data['排量'] = data['排量'].apply(remove_units)
#去除包含缺失值的行
data.replace(0, np.nan,inplace=True)
data.dropna(inplace=True)
data['NEDC纯电续航里程'] = data['NEDC纯电续航里程'].apply(remove_units)
#去除重复值
data.drop_duplicates(inplace=True)
#预处理后的数据不包含缺失值,且字段属性皆为数值
data.head(5)
b、指标一致化
在进行综合评分之前,我们需要对所有的指标进行一致化处理,将其都转换为极大型指标,从而使得综合评分越高,推荐度越高。
#基于性价比和环保的考量,我们假定排量是一个极小型指标,因此将其转换为极大型(一个更好的方式是将其做为区间型处理)
#转换方式为取倒数
data['排量']=1/data['排量']
data['价格']=1/data['价格']
c、指标标准化
为了消除不同指标间量纲导致的不一致,因此还需要对各指标进行标准化处理,统一到0-1区间内
进行无量纲化处理
# 进行无量纲化处理
from sklearn import preprocessing
zscore = preprocessing.StandardScaler()
z_score = zscore.fit_transform(data)
#至此,原始数据已经进行了无量纲化和一致化,得到的结果可用于后续综合评分
z_score

d、计算TOPSIS综合评分
# 获取权重,该权重由AHP生成
#读取权重矩阵
comparison_matrix =np.load('comparison_matrix.npy')
#计算特征根和指标权重矩阵
weights, max_eigenvalue = ahp_weight_calculation(comparison_matrix)
weighted_data =z_score * weights
# 计算正理想解和负理想解
positive_ideal = weighted_data.max()
negative_ideal = weighted_data.min()
# 计算与正理想解和负理想解的距离
D_positive = np.sqrt(((weighted_data - positive_ideal) ** 2).sum(axis=1))
D_negative = np.sqrt(((weighted_data - negative_ideal) ** 2).sum(axis=1))
# 根据计算TOPSIS综合得分
topsis_score = D_negative / (D_positive + D_negative)
# 将TOPSIS得分添加到数据框中
data['TOPSIS Score'] = topsis_score
# 根据得分排序
data.sort_values(by='TOPSIS Score', ascending=False,inplace=True)
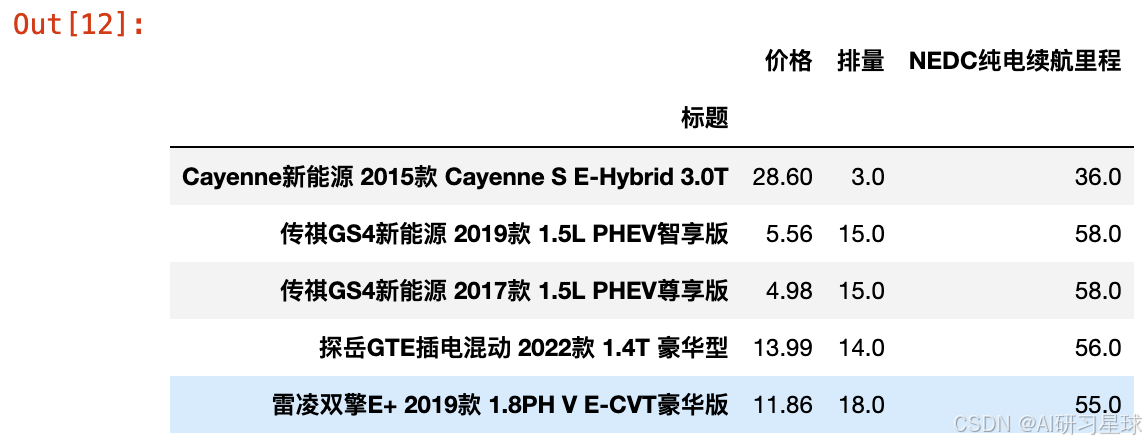
data.head(10)
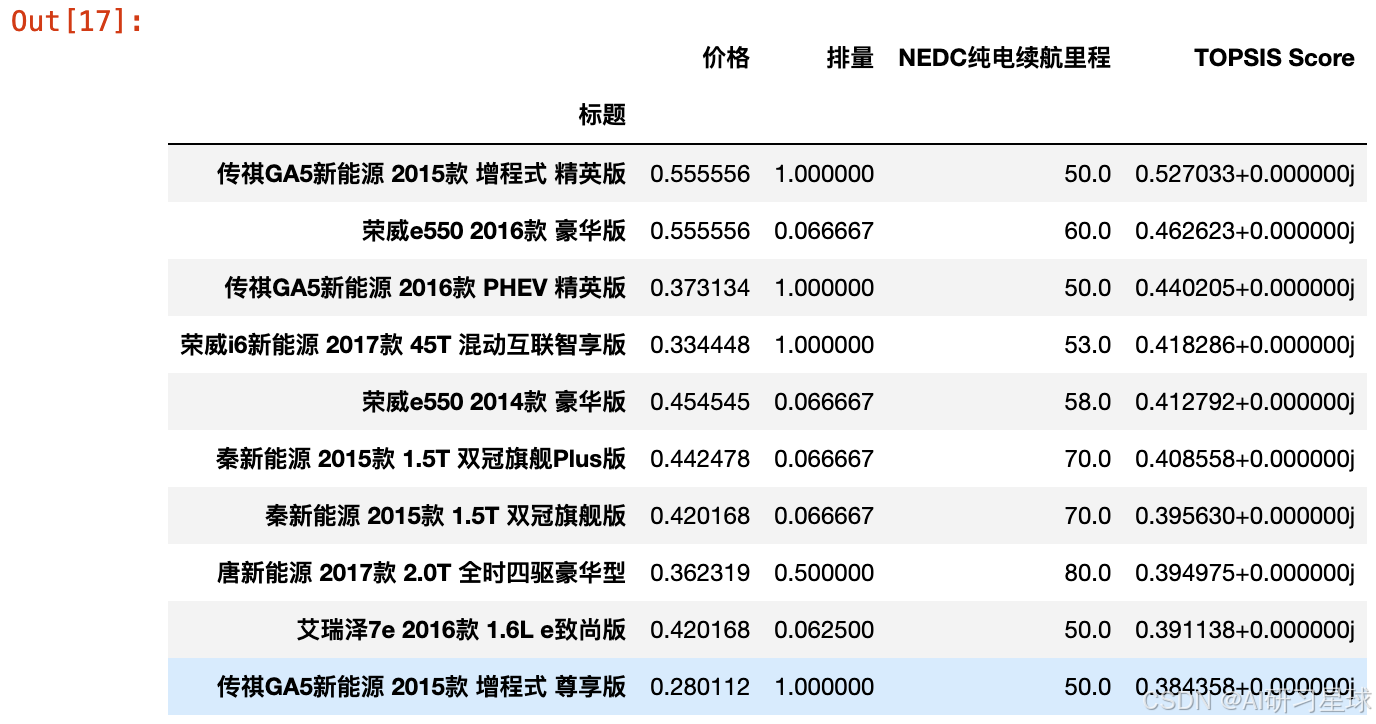
从结果上来看,如果用户对于价格偏好最高,续航里程次之,排量最不关注的话,可选的车型如上所示,以上车型都是属于价格偏低,排量较小,同时续航里程相对较长的性价比之选,一定程度上符合用户预期,也证明了我们所使用的TOPSIS模型结合AHP决策的方法一定程度上能考虑用户的需求偏好
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我



















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











