







本文主要包含以下内容:
一、什么是正则化
二、参数范数模型
2.1 L1正则和L2正则
2.2 为什么通过L1正则、L2正则能够防止过拟合
2.3 L2正则的表现
2.4 L1正则化为什么会产生稀疏解
2.5 L2正则为什么求解比较稳定
三、Dropout和集成方法
3.1 Dropout
3.2 集成方法bagging及boosting
一、什么是正则化
正则化即为对学习算法的修改,旨在减少泛化误差而不是训练误差。正则化的策略包括:
(1)约束和惩罚被设计为编码特定类型的先验知识
(2)偏好简单模型
(3)其他形式的正则化,如:集成的方法,即结合多个假说解释训练数据
在实践中,过于复杂的模型不一定包含数据的真实的生成过程,甚至也不包括近似过程,这意味着控制模型的复杂程度不是一个很好的方法,或者说不能很好的找到合适的模型的方法。实践中发现的最好的拟合模型通常是一个适当正则化的大型模型。
二、参数范数模型
对于线性模型,譬如线性回归、逻辑回归,可以使用简单有效的参数范数模型进行正则化。许多正则化方法通过对目标函数J添加惩罚项,其中α也被称为惩罚系数,限制模型的学习能力:
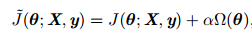
对于神经网络中,参数通常是包括权值w和偏置b,而我们通常对w做惩罚而不对偏置b做处理,这是因为不对b进行处理也不会有太大的影响。
2.1 L1正则和L2正则
L1正则项表示:

L2正则项表示:
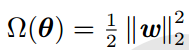
2.2 为什么通过L1正则、L2正则能够防止过拟合
解释:
过拟合产生的原因通常是因为参数比较大导致的,通过添加正则项,假设某个参数比较大,目标函数加上正则项后,也就会变大,因此该参数就不是最优解了。
问:为什么过拟合产生的原因是参数比较大导致的?
答:过拟合,就是拟合函数需要顾忌每一个点,当存在噪声的时候,原本平滑的拟合曲线会变得波动很大。在某些很小的区间里,函数值的变化很剧烈,这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
2.3 L2正则的表现
对于L2正则,其目标函数为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1303
1303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









