







经典神经网络 | ResNet论文解读及代码实现
前言
ResNet是2015年ImageNet比赛的冠军,将识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
通过观察学习vggnet等经典神经网络模型,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?
从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。这是因为梯度消失或是梯度爆炸导致的。

简介
Kaiming He等人提出了残差网络ResNet来解决上述所说的退化问题,其基本思想如图6所示。
图6(a):表示增加网络的时候,将x映射成y=F(x)输出。
图6(b):对图6(a)作了改进,输出y=F(x)+x。这时不是直接学习输出特征y的表示,而是学习y-x。
如果想学习出原模型的表示,只需将F(x)的参数 全部设置为0,则是恒等映射。
F(x)=y-x也叫做残差项,如果x→y的映射接近恒等映射,图6(b)中通过学习残差项也比图6(a)学习完整映射形式更加容易。

图6(b)的结构是残差网络的基础,这种结构也叫做残差块(residual block)。输入x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。残差块的具体设计方案如 图7 所示,这种设计方案也成称作瓶颈结构(BottleNeck)。

深层残差学习
残差恒等映射

F(x,{Wi})表示待学习的恒等映射。x和F维数必须相等,如果不相等,可以通过快捷连接执行线性投影Ws来匹配维度或是额外填充0输入以增加维数,stride=2.
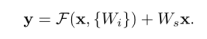
下图为VGG-19,Plain-34(没有使用residual结构)和ResNet-34网络结构对比:

对上图进行如下说明:
.相比于VGG-19,ResNet没有使用全连接层,而使用了全局平均池化层,可以减少大量参数。VGG-19大量参数集中在全连接层;
.ResNet-34中跳跃连接“实线”为identity mapping和residual mapping通道数相同,“虚线”部分指的是两者通道数不同,需要使用1x1卷积调整通道维度,使其可以相加。
论文一共提出5种ResNet网络,网络参数统计表如下:
实现
基本设置遵循以前的经典网络,可以看原文的参考文献。在每次卷积之后和激活之前,我们采用批量归一化(BN) ,紧接着,我们初始化权重,并从头开始训练所有普通/残差网。我们使用最小批量为256的SGD。当误差平稳时,学习率从0.1开始除以10,模型被训练达到600000次迭代。我们使用0.0001的重量衰减和0.9的动量。
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。
使用pytorch实现残差神经网络
#coding:utf8
from __future__ import print_function # 这个是python当中让print都以python3的形式进行print,即把print视为函数
import argparse # 使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
import torch # 以下这几行导入相关的pytorch包,有疑问的参考我写的 Pytorch打怪路(一)系列博文
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchnet import meter
import torchvision
# Training settings 就是在设置一些参数,每个都有默认值,输入python main.py -h可以获得相关帮助
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
# batch_size参数,如果想改,如改成128可这么写:python main.py -batch_size=128
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=10, metavar='N', # test_batch_size参数,
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False, # GPU参数,默认为False
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N', # 跑多少次batch进行一次日志记录
help='how many batches to wait before logging training status')
args = parser.parse_args() # 这个是使用argparse模块时的必备行,将参数进行关联,详情用法请百度 argparse 即可
args.cuda = not args.no_cuda and torch.cuda.is_available() # 这个是在确认是否使用gpu的参数,比如
torch.manual_seed(args.seed) # 设置一个随机数种子,相关理论请自行百度或google,并不是pytorch特有的什么设置
if args.cuda:
torch.cuda.manual_seed(args.seed) # 这个是为GPU设置一个随机数种子
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
train_loader = torch.utils.data.DataLoader( # 加载训练数据,详细用法参考我的Pytorch打怪路(一)系列-(1)
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.Resize(224), #resnet默认图片输入大小224*224
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader( # 加载训练数据,详细用法参考我的Pytorch打怪路(一)系列-(1)
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Conv2d(1, 3, kernel_size=1)
self.resnet = torchvision.models.resnet50(pretrained=False)
def forward(self, x):
x= self.conv(x)
x= self.resnet(x)
return x
model = Net().cuda()
criterion=nn.CrossEntropyLoss()
if args.cuda:
model.cuda() # 判断是否调用GPU模式
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum) # 初始化优化器 model.train()
optimizer=optim.SGD(model.parameters(),lr=0.05,momentum=0.9)
def train(epoch): # 定义每个epoch的训练细节
model.train() # 设置为trainning模式
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda: # 如果要调用GPU模式,就把数据转存到GPU
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target) # 把数据转换成Variable
optimizer.zero_grad() # 优化器梯度初始化为零
output = model(data) # 把数据输入网络并得到输出,即进行前向传播
ff = nn.CrossEntropyLoss()
loss = criterion(output, target) # 计算损失函数
loss.backward() # 反向传播梯度
optimizer.step() # 结束一次前传+反传之后,更新优化器参数
if batch_idx % args.log_interval == 0: # 准备打印相关信息,args.log_interval是最开头设置的好了的参数
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test():
model.eval() # 设置为test模式
test_loss = 0 # 初始化测试损失值为0
correct = 0 # 初始化预测正确的数据个数为0
confusion_matrix = meter.ConfusionMeter(10)
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss 把所有loss值进行累加
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum() # 对预测正确的数据个数进行累加
confusion_matrix.add(output.data, target.data)
cm_value = confusion_matrix.value()
accuracy = 100. * (cm_value[0][0] + cm_value[1][1]
+ cm_value[2][2] + cm_value[3][3]
+ cm_value[4][4] + cm_value[5][5]+cm_value[6][6]+cm_value[7][7]++cm_value[8][8]+cm_value[9][9]) / (cm_value.sum())
test_loss /= len(test_loader.dataset) # 因为把所有loss值进行过累加,所以最后要除以总得数据长度才得平均loss
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
print("confusion_matrix",accuracy,"sum:",cm_value.sum())
for epoch in range(1, args.epochs + 1): # 以epoch为单位进行循环
train(epoch)
test()
pytorch官方源码请移步:
https://www.cnblogs.com/wzyuan/p/9880342.html















 3392
3392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









