







 本文深入探讨了对比学习的概念,它是自监督学习的一种形式,旨在通过对比正负样本在特征空间中的表示来学习通用特征。对比学习的关键在于构建正负样本对,如MoCo和SimCLR等方法所展示的那样。MoCo引入了动态字典和动量更新来增强表示学习,而CLIP则是在文本-图像对上的对比学习,学习跨模态的匹配关系。这些技术在预训练模型和下游任务的性能提升方面表现出色。
本文深入探讨了对比学习的概念,它是自监督学习的一种形式,旨在通过对比正负样本在特征空间中的表示来学习通用特征。对比学习的关键在于构建正负样本对,如MoCo和SimCLR等方法所展示的那样。MoCo引入了动态字典和动量更新来增强表示学习,而CLIP则是在文本-图像对上的对比学习,学习跨模态的匹配关系。这些技术在预训练模型和下游任务的性能提升方面表现出色。
本文介绍了对比学习以及最新的研究成果。
1 介绍
监督学习近些年获得了巨大的成功,但是有如下的缺点:
1.人工标签相对数据来说本身是稀疏的,蕴含的信息不如数据内容丰富;
2.监督学习只能学到特定任务的知识,不是通用知识,一般难以直接迁移到其他任务中。
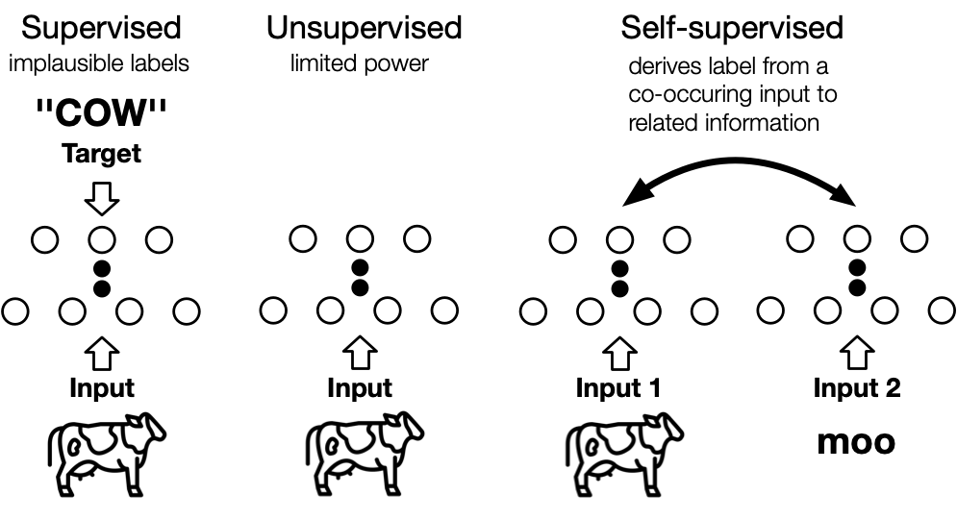
由于这些原因,自监督学习的发展被给予厚望。监督学习,无监督学习和自监督学习的区别
自监督学习(self-supervised learning)不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,学习样本数据的特征表达,应用于下游的任务。自监督学习又可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。对比学习的核心思想是讲正样本和负样本在特征空间对比,学习样本的特征表示,难点在于如何构造正负样本。
最近,诸如BERT和T5之类的自然语言处理模型已经表明,可以通过首先在一个大型的未标记数据集上进行预训练(即进行 pretext task上游任务),使得编码器能够提取数据中的特征,然后在一个较小的标记数据集上进行微调(下游任务,通常要在上游任务得到的编码器后添加几层全连接层组成完整的模型),从而用很少的类标签来获得良好的结果。
用MoCo里的定义就是:
A main purpose of unsupervised learning is to pre-train representations (i.e., features) that can be transferred to downstream tasks by fine-tuning.
也是因此,对比学习通常会和 表征学习(representation learning) 联系起来,表征学习的定义是:learning representations of the data that make it easier to extract useful information when building classifiers or other predictors
同样,对未标记的大型图像数据集进行预训练,有可能提高计算机视觉任务的性能。这点已经在对比表示学习的相关论文,例如Exemplar-CNN, Instance Discrimination, CPC, AMDIM, CMC, MoCo,获得了证实。对比学习训练得到的神经网络模型,可以被用作下游的任务,例如分类、分割、检测等。经过对比学习预训练得到的神经网络,已经具有很强的表达能力,一般只需要再用很少的有标签数据微调,就可以获得非常优秀的性能。总结而言,对比学习训练得到的模型可以当作预训练模型,后续仅需少量有标签的数据就可以训练出一个完整功能的模型。
用一个图来概括什么是自监督学习:
2 对比学习
对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。简单地说,对比表示学习可以被认为是通过比较学习。相对来说,生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。在对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。可以在“相似”输入的正对和“不同”输入的负对之间进行比较。以下图片引用。

对比学习通过同时最大化同一图像的不同变换视图(例如剪裁,翻转,颜色变换等)之间的一致性,以及最小化不同图像的变换视图之间的一致性来学习的。 简单来说,就是对比学习要做到相同的图像经过各类变换之后,依然能识别出是同一张图像,所以要最大化各类变换后图像的相似度(因为都是同一个图像得到的)。相反,如果是不同的图像(即使经过各种变换可能看起来会很类似),就要最小化它们之间的相似度。通过这样的对比训练,编码器(encoder)能学习到图像的更高层次的通用特征 (image-level representations),而不是像素级别的生成模型(pixel-level generation)。
2.1 对比学习一般思路
对比学习通过使用三个关键的元素(正样本、anchor、负样本的表征)来实现上述思想。为了创建一个正样本对,我们需要两个相似的样本,而当我们创建一个负样本对时,我们将使用第三个与两个正样本不相似的样本。
 然而,在自监督学习任务中,我们并不知道每个样本的标签。因此,我们也无从知晓两张图像是否相似。
然而,在自监督学习任务中,我们并不知道每个样本的标签。因此,我们也无从知晓两张图像是否相似。
尽管如此,如果我们假设每张图片都从属于它自身的一个独有的类别,那么我们就可以提出各种构造这类三元组的方法(正负样本对)。这意味着,在一个包含 N 个样本的数据集中,我们现在拥有了 N 个标签!
接下来:为每一个样本赋予一个独特的类别
当我们知道了每一张图像的标签(类别)后,就可以使用数据增强技术(旋转 裁剪 加噪等)来生成这些三元组:

生成完正负样本对以后,就可以设计一个 encoder,作为特征提取器,来进行优化、训练。
3 主要论文
小介绍
对比学习广泛应用于图像领域的无监督表示学习,以MoCo(ICML2020)和SimCLR(2020)为代表,在ImageNet数据集上取得了显著的提升。「对比学习的核心在于如何构建正负样本集合」,图像领域一般通过旋转、裁剪等图片操作,而文本领域往往通过回译、字符插入删除等方法,这些方法依赖于领域经验,缺乏多样性和灵活性
3.1 MoCo
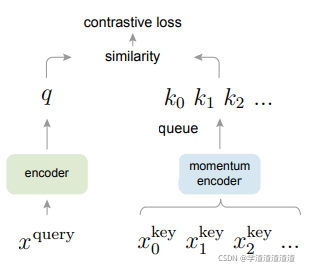
提出了 Momentum Contrast (MoCo) 机制,该机制通过匹配查询样本 x q u e r y x^{query} xquery的编码值q和key样本编码值字典 { k 0 , k 1 , k 2 , . . . } \{k_0,k_1,k_2,...\} {k0,k1,k2,...},并计算他们的对比损失(contrastive loss),来优化、训练一个 visual representation encoder 。字典以queue的形式建立,当前的 mini-batch 进入队列、最老的 mini-batch 出列,以 mini-batch 为最小单位。在训练时,keys样本被一个 encoder 编码,encoder又以 momentum update 的方式进行更新。这样的更新机制可以在学习视觉表征时实现一个足够大的、一致性(因为momentum的滑动平均机制)的字典。我认为当出现收敛问题时,我们可以采取这样的momentum 策略,把前几次的数据也加入计算,这样可以使得更新的方向具有一致性。
MoCo的两个创新点:队列形式的字典;momentum update。
3.1.1 队列形式的字典
MoCo的神奇之处在于设计了一个动态的字典,我们先来了解一下对比学习中的 Dictionary Look-up 机制:

值得注意的是:The networks
f
q
f_q
fq and
f
k
f_k
fk can be identical [29, 59, 63], partially shared [46, 36, 2], or different [56].
本文的假设是当 dictionary 足够大并且包含有足够的负样本时, encoder 可以提取到更佳的特征,并且在 encoder 进化的过程中,dictionary中的值应该尽量保持一致性(consistent)。
为什么要采用队列形式的dictionary?:Removing the oldest mini-batch can be beneficial, because its encoded keys are the most outdated and thus the least consistent with the newest ones.
3.1.2 momentum update
一个最简单的idea就是设置
f
k
f_k
fk 和
f
q
f_q
fq 的参数一样,也就是使用同一个编码器,但是在这样操作的过程中,发现效果很差,本文猜测是因为 encoder过快的变化造成了key表征的一致性 导致的。所以本文提出了如下的参数更新策略:
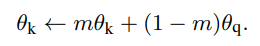
根据上式,
θ
k
\theta_k
θk 更新地会更加缓和,有效地解决了原本的收敛问题。
MoCo算法torch版本的伪代码
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels) # 这里的交叉熵是指原文中定义的 L_q,而不是我们所熟悉的交叉熵
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
# 注:bmm: batch matrix multiplication; mm: matrix multiplication; cat: concatenation.
clip
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
具体介绍可以看这个:
https://zhuanlan.zhihu.com/p/493489688
ipynb教程:
https://drive.google.com/file/d/1DiZRMMlt0owNOYSMKbCFNVvQ6d8MppPV/view?usp=sharing
参考:
https://blog.csdn.net/xxxxxxxxxx13/article/details/110820373
https://www.jianshu.com/p/f297528191c8
对比学习,写的很详细基础:
https://baijiahao.baidu.com/s?id=1679009620846462836&wfr=spider&for=pc


















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











