







Rasa分词之JiebaTokenizer
rasa/nlu/tokenizers/tokenizer.py
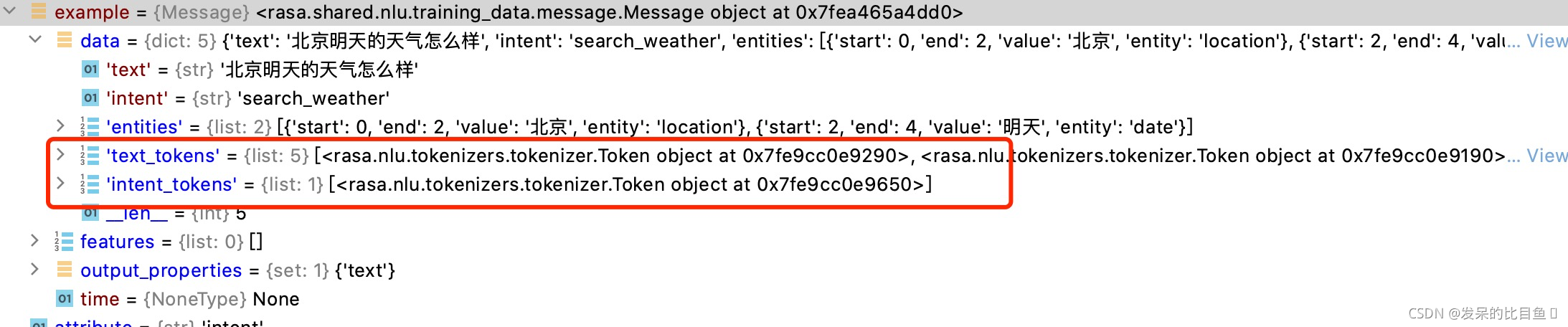
Token 分词结果返回的对象

Tokenizer分词的父类,其中train函数是训练,process是预测。
这里的token分为两种attribute和text,
分好的token对象保存在training_examples的message中
class Token:
def __init__(
self,
text: Text,
start: int,
end: Optional[int] = None,
data: Optional[Dict[Text, Any]] = None,
lemma: Optional[Text] = None,
) -> None:
self.text = text
self.start = start
self.end = end if end else start + len(text)
self.data = data if data else {}
self.lemma = lemma or text
def set(self, prop: Text, info: Any) -> None:
self.data[prop] = info
def get(self, prop: Text, default: Optional[Any] = None) -> Any:
return self.data.get(prop, default)
def __eq__(self, other):
if not isinstance(other, Token):
return NotImplemented
return (self.start, self.end, self.text, self.lemma) == (
other.start,
other.end,
other.text,
other.lemma,
)
def __lt__(self, other):
if not isinstance(other, Token):
return NotImplemented
return (self.start, self.end, self.text, self.lemma) < (
other.start,
other.end,
other.text,
other.lemma,
)
class Tokenizer(Component):
def __init__(self, component_config: Dict[Text, Any] = None) -> None:
"""Construct a new tokenizer using the WhitespaceTokenizer framework."""
super().__init__(component_config)
# flag to check whether to split intents
self.intent_tokenization_flag = self.component_config.get(
"intent_tokenization_flag", False
)
# split symbol for intents
self.intent_split_symbol = self.component_config.get("intent_split_symbol", "_")
# token pattern to further split tokens
token_pattern = self.component_config.get("token_pattern", None)
self.token_pattern_regex = None
if token_pattern:
self.token_pattern_regex = re.compile(token_pattern)
def tokenize(self, message: Message, attribute: Text) -> List[Token]:
"""Tokenizes the text of the provided attribute of the incoming message."""
raise NotImplementedError
def train(
self,
training_data: TrainingData,
config: Optional[RasaNLUModelConfig] = None,
**kwargs: Any,
) -> None:
"""Tokenize all training data."""
for example in training_data.training_examples:
for attribute in MESSAGE_ATTRIBUTES:
if (
example.get(attribute) is not None
and not example.get(attribute) == ""
):
if attribute in [INTENT, ACTION_NAME, INTENT_RESPONSE_KEY]: # 将intent action_name intent_response_key作为token
tokens = self._split_name(example, attribute)
else:
tokens = self.tokenize(example, attribute)
example.set(TOKENS_NAMES[attribute], tokens) ## example 是一个Message对象 TOKENS_NAMES --> {'text': 'text_tokens', 'intent': 'intent_tokens', 'response': 'response_tokens', 'action_name': 'action_name_tokens', 'action_text': 'action_text_tokens', 'intent_response_key': 'intent_response_key_tokens'}
def process(self, message: Message, **kwargs: Any) -> None:
"""Tokenize the incoming message."""
for attribute in MESSAGE_ATTRIBUTES:
if isinstance(message.get(attribute), str):
if attribute in [INTENT, ACTION_NAME, RESPONSE_IDENTIFIER_DELIMITER]:
tokens = self._split_name(message, attribute)
else:
tokens = self.tokenize(message, attribute)
message.set(TOKENS_NAMES[attribute], tokens)
def _tokenize_on_split_symbol(self, text: Text) -> List[Text]:
words = (
text.split(self.intent_split_symbol)
if self.intent_tokenization_flag
else [text]
)
return words
def _split_name(self, message: Message, attribute: Text = INTENT) -> List[Token]:
text = message.get(attribute)
# for INTENT_RESPONSE_KEY attribute,
# first split by RESPONSE_IDENTIFIER_DELIMITER
if attribute == INTENT_RESPONSE_KEY:
intent, response_key = text.split(RESPONSE_IDENTIFIER_DELIMITER)
words = self._tokenize_on_split_symbol(
intent
) + self._tokenize_on_split_symbol(response_key)
else:
words = self._tokenize_on_split_symbol(text)
return self._convert_words_to_tokens(words, text) ## 返回一个list [Token对象, Token对象]
def _apply_token_pattern(self, tokens: List[Token]) -> List[Token]:
"""Apply the token pattern to the given tokens.
Args:
tokens: list of tokens to split
Returns:
List of tokens.
"""
if not self.token_pattern_regex:
return tokens
final_tokens = []
for token in tokens:
new_tokens = self.token_pattern_regex.findall(token.text)
new_tokens = [t for t in new_tokens if t]
if not new_tokens:
final_tokens.append(token)
running_offset = 0
for new_token in new_tokens:
word_offset = token.text.index(new_token, running_offset)
word_len = len(new_token)
running_offset = word_offset + word_len
final_tokens.append(
Token(
new_token,
token.start + word_offset,
data=token.data,
lemma=token.lemma,
)
)
return final_tokens
@staticmethod
def _convert_words_to_tokens(words: List[Text], text: Text) -> List[Token]:
running_offset = 0
tokens = []
for word in words:
word_offset = text.index(word, running_offset)
word_len = len(word)
running_offset = word_offset + word_len
tokens.append(Token(word, word_offset))
return tokens
rasa/nlu/tokenizers/jieba_tokenizer.py,继承Tokenizer父类
class JiebaTokenizer(Tokenizer):
"""This tokenizer is a wrapper for Jieba (https://github.com/fxsjy/jieba)."""
supported_language_list = ["zh"]
defaults = {
"dictionary_path": None, # 自定义字典路径
# Flag to check whether to split intents
"intent_tokenization_flag": False,# 意图是否需要分词
# Symbol on which intent should be split
"intent_split_symbol": "_",#意图split符号
# Regular expression to detect tokens
"token_pattern": None,# 分词正则
} # default don't load custom dictionary
def __init__(self, component_config: Dict[Text, Any] = None) -> None:
"""Construct a new intent classifier using the MITIE framework."""
super().__init__(component_config)
# path to dictionary file or None
self.dictionary_path = self.component_config.get("dictionary_path")
# load dictionary
if self.dictionary_path is not None:
self.load_custom_dictionary(self.dictionary_path)
@classmethod
def required_packages(cls) -> List[Text]:
return ["jieba"]
@staticmethod
def load_custom_dictionary(path: Text) -> None:# 加载自定义字典路径
import jieba
jieba_userdicts = glob.glob(f"{path}/*")
for jieba_userdict in jieba_userdicts:
logger.info(f"Loading Jieba User Dictionary at {jieba_userdict}")
jieba.load_userdict(jieba_userdict)
def tokenize(self, message: Message, attribute: Text) -> List[Token]:
import jieba
text = message.get(attribute)
tokenized = jieba.tokenize(text) ## 使用jieba进行分词
tokens = [Token(word, start) for (word, start, end) in tokenized]
return self._apply_token_pattern(tokens) ## 使用正则再次对Token分词,得到结巴最终的分词
@classmethod
def load(
cls,
meta: Dict[Text, Any],
model_dir: Optional[Text] = None,
model_metadata: Optional["Metadata"] = None,
cached_component: Optional[Component] = None,
**kwargs: Any,
) -> "JiebaTokenizer":
relative_dictionary_path = meta.get("dictionary_path")
# get real path of dictionary path, if any
if relative_dictionary_path is not None:
dictionary_path = os.path.join(model_dir, relative_dictionary_path)
meta["dictionary_path"] = dictionary_path
return cls(meta)
@staticmethod
def copy_files_dir_to_dir(input_dir: Text, output_dir: Text) -> None:
# make sure target path exists
if not os.path.exists(output_dir):
os.makedirs(output_dir)
target_file_list = glob.glob(f"{input_dir}/*")
for target_file in target_file_list:
shutil.copy2(target_file, output_dir)
def persist(self, file_name: Text, model_dir: Text) -> Optional[Dict[Text, Any]]:
"""Persist this model into the passed directory."""
# copy custom dictionaries to model dir, if any
if self.dictionary_path is not None:
target_dictionary_path = os.path.join(model_dir, file_name)
self.copy_files_dir_to_dir(self.dictionary_path, target_dictionary_path)
return {"dictionary_path": file_name}
else:
return {"dictionary_path": None}
















 1912
1912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











