







spacy教程–基础
安装
pip install spacy
训练模型
安装之后还要下载官方的训练模型, 不同的语言有不同的训练模型,这里只用对应中文的模型演示:
python -m spacy download zh_core_web_sm
代码中使用:
import spacy
nlp = spacy.load("zh_core_web_sm")
模型官方文档: https://spacy.io/models
每种语言也会有几种不同的模型,例如中文的模型除了刚才下载的 zh_core_web_sm 外,还有zh_core_web_trf、zh_core_web_md 等,它们的区别在于准确度和体积大小, zh_core_web_sm 体积小,准确度相比zh_core_web_trf差,zh_core_web_trf相对就体积大。这样可以适应不同场景。
LANGUAGE : 那种语言的模型
SIZE : 模型体积的大小
COMPONENTS(组件): 模型具备的功能:
- tok2vec: 分词
- tagger: 词性标注
- parser: 依存分析
- senter: 分句
- ner: 命名实体识别
- attribute_ruler: 更改属性映射(没有具体了解)
功能
import spacy
s = "小米董事长叶凡决定投资华为。在2002年,他还创作了<遮天>。"
nlp = spacy.load("zh_core_web_sm")
doc = nlp(s)
分句 (sentencizer)
# 1. 分句 (sentencizer)
for i in doc.sents:
print(i)
"""
小米董事长叶凡决定投资华为。
在2002年,他还创作了<遮天>。
"""
分词 (Tokenization)
# 2. 分词 (Tokenization)
print([w.text for w in doc])
"""
['小米', '董事长', '叶凡', '决定', '投资', '华为', '。', '在', '2002年', ',', '他', '还', '创作', '了', '<遮天>', '。']
"""
词性标注 (Part-of-speech tagging)
细粒度
print([(w.text, w.tag_) for w in doc])
"""
[('小米', 'NR'), ('董事长', 'NN'), ('叶凡', 'NR'), ('决定', 'VV'), ('投资', 'VV'), ('华为', 'NR'), ('。', 'PU'), ('在', 'P'), ('2002年', 'NT'), (',', 'PU'), ('他', 'PN'), ('还', 'AD'), ('创作', 'VV'), ('了', 'AS'), ('<遮天>', 'NN'), ('。', 'PU')]
"""
粗粒度
print([(w.text, w.pos_) for w in doc])
"""
[('小米', 'PROPN'), ('董事长', 'NOUN'), ('叶凡', 'PROPN'), ('决定', 'VERB'), ('投资', 'VERB'), ('华为', 'PROPN'), ('。', 'PUNCT'), ('在', 'ADP'), ('2002年', 'NOUN'), (',', 'PUNCT'), ('他', 'PRON'), ('还', 'ADV'), ('创作', 'VERB'), ('了', 'PART'), ('<遮天>', 'NOUN'), ('。', 'PUNCT')]
"""
识别停用词 (Stop words)
print([(w.text, w.is_stop) for w in doc])
"""
[('小米', False), ('董事长', False), ('叶凡', False), ('决定', True), ('投资', False), ('华为', False), ('。', True), ('在', True), ('2002年', False), (',', True), ('他', True), ('还', True), ('创作', False), ('了', True), ('<遮天>', False), ('。', True)]
"""
命名实体识别 (Named Entity Recognization)
# 命名实体识别 (Named Entity Recognization)
print([(e.text, e.label_) for e in doc.ents])
"""
[('小米', 'PERSON'), ('叶凡', 'PERSON'), ('2002年', 'DATE')]
"""
依存分析 (Dependency Parsing)
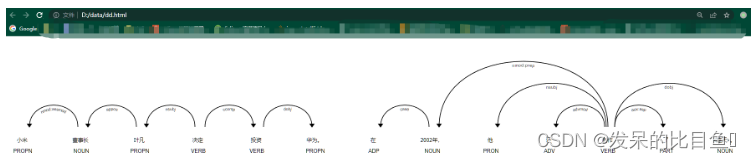
print([(w.text, w.dep_) for w in doc])
"""
[('小米', 'nmod:assmod'), ('董事长', 'appos'), ('叶凡', 'nsubj'), ('决定', 'ROOT'), ('投资', 'ccomp'), ('华为', 'dobj'), ('。', 'punct'), ('在', 'case'), ('2002年', 'nmod:prep'), (',', 'punct'), ('他', 'nsubj'), ('还', 'advmod'), ('创作', 'ROOT'), ('了', 'aux:asp'), ('<遮天>', 'dobj'), ('。', 'punct')]
"""
词性还原 (Lemmatization)
这个模型没有这个功能,用英文模型演示下
找到单词的原型,即词性还原,将am, is, are, have been 还原成be,复数还原成单数(cats -> cat),过去时态还原成现在时态 (had -> have)。
import spacy
nlp = spacy.load('en_core_web_sm')
txt = "A magnetic monopole is a hypothetical elementary particle."
doc = nlp(txt)
lem = [token.lemma_ for token in doc]
print(lem)
"""
['a', 'magnetic', 'monopole', 'be', 'a', 'hypothetical', 'elementary', 'particle', '.']
"""
提取名词短语 (Noun Chunks)
noun_chunks = [nc for nc in doc.noun_chunks]
print(noun_chunks)
"""
[A magnetic monopole, a hypothetical elementary particle]
"""
指代消解 (Coreference Resolution)
指代消解 ,寻找句子中代词 he,she,it 所对应的实体。为了使用这个模块,需要使用神经网络预训练的指代消解系数,如果前面没有安装,可运行命令:pip install neuralcoref
这个模型没有这个功能,用英文模型演示下
txt = "My sister has a son and she loves him."
# 将预训练的神经网络指代消解加入到spacy的管道中
import neuralcoref
neuralcoref.add_to_pipe(nlp)
doc = nlp(txt)
doc._.coref_clusters
"""
[My sister: [My sister, she], a son: [a son, him]]
"""
可视化
from spacy import displacy
# 可视化依存关系
html_str = displacy.render(doc, style="dep")
#可视化命名名称实体
# html_str = displacy.render(doc, style="ent")
with open("D:\\data\\ss.html", "w", encoding="utf8") as f:
f.write(html_str)
html_str 是一个html格式的字符串, 保存到本地 ss.html文件,浏览器打开效果:
依存关系
命名实体

官方还有一个可视化的库: spacy-streamlit , 专门用于spacy相关的nlp可视化。
streamlit 也是一个专门可视化的库。
spacy-streamlit 有一个使用demo:
https://share.streamlit.io/ines/spacy-streamlit-demo/app.py
demo对应githup
GitHub - ines/spacy-streamlit-demo















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









