






1.P-Tuning v2结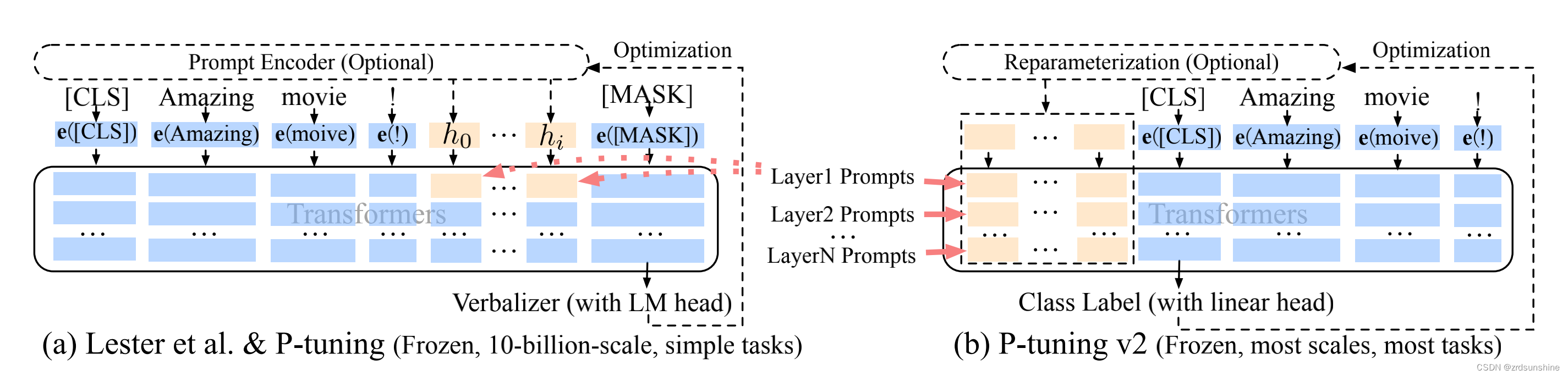
2.具体操作步骤如下:
步骤1.
source activate
(conda env list)
conda activate torch1.13
pip install rouge_chinese nltk jieba datasets
conda activate chatglm2-6b
步骤2.
git clone https://github.com/THUDM/ChatGLM2-6B
步骤3.
cd ChatGLM2-6B
步骤4.
cd ptuning
步骤5.
mkdir AdvertiseGen
步骤6.
到 https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view 下载数据
步骤7.
在本地执行命令行,不要在服务器内上传
传入AdvertiseGen 数据集

步骤8.
vi train.sh
修改train.sh文件:去掉最后的 --quantization_bit 4。、model_name为自己的文件路径 :/data/sim_chatgpt/chatglm2-6b
最后修改文件内容如下:
PRE_SEQ_LEN=8
LR=1e-2
CUDA_VISIBLE_DEVICES=0 nohup python -u main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /data/sim_chatgpt/chatglm2-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
>> log.out 2>&1 &
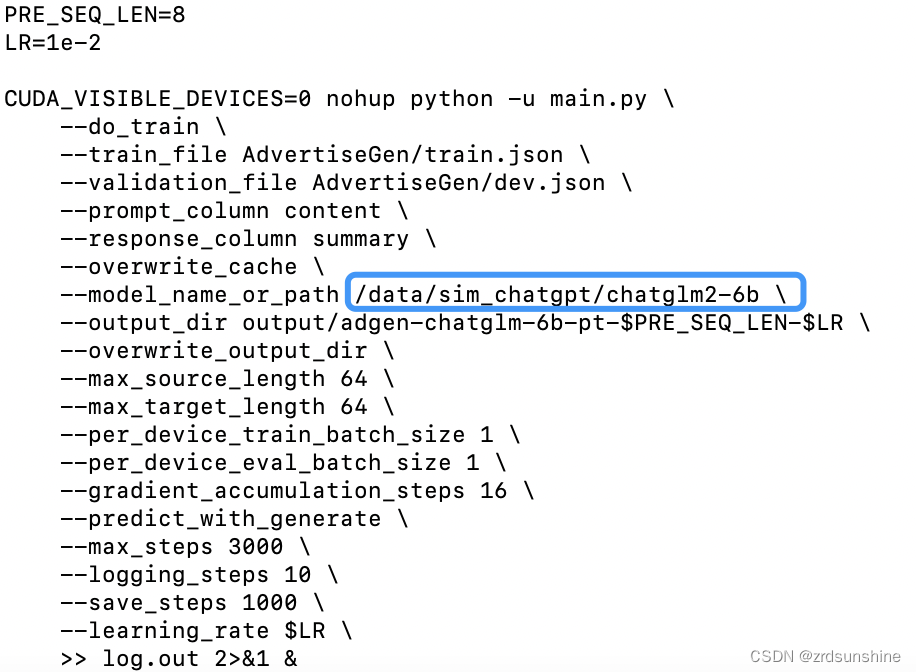
步骤9.
bash train.sh
















 2356
2356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









