






尽管围绕llm或其它lm在推理过程中模型内部原理及解释的研究在当前AI理论的发展阶段上仍然是相当大的挑战,但令人欣慰的是总有一些人在这一路途中持续并默默的的进行着探索,就像这篇来自于MIT以及几周前来自Meta的LLM数学隐推理过程验证与阐释(详细内容大家感兴趣的话可以翻看两周前笔记内容或原论文,阅读点赞还蛮高哈)中的那样..
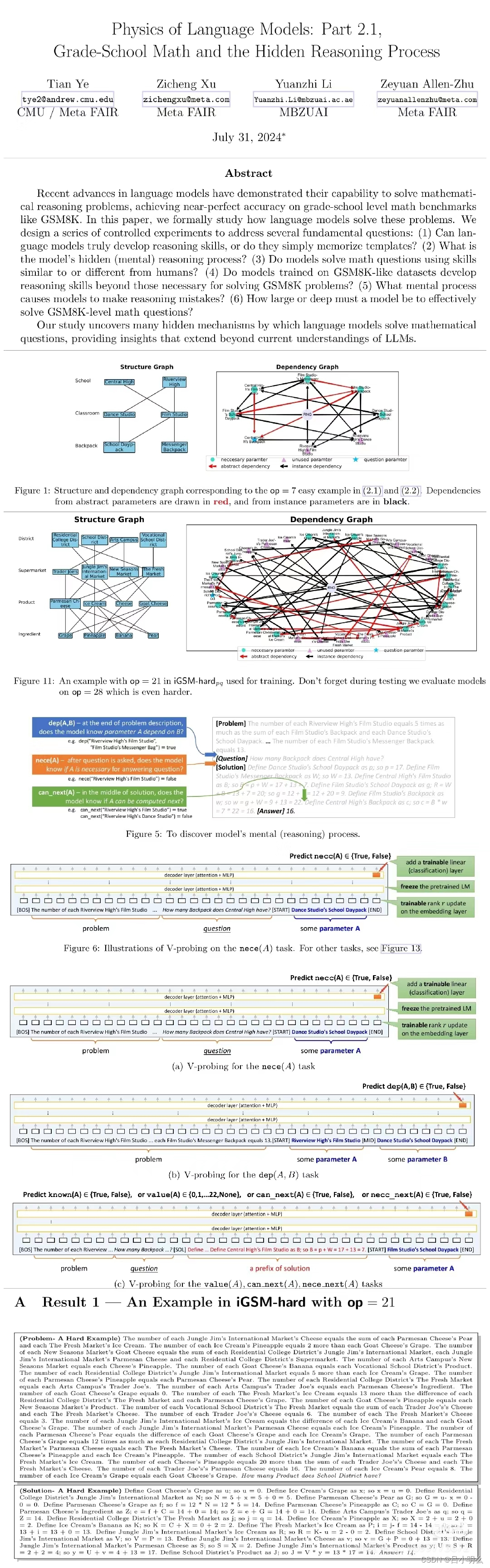
MIT CSAIL的研究人员发现印证,llm的「内心深处」某种程度上已经展现出了对现实的模拟,模型对语言和世界的理解,绝不仅仅是简单的随机鹦鹉。
也许,在未来,llm会比今天更深层地理解语言。
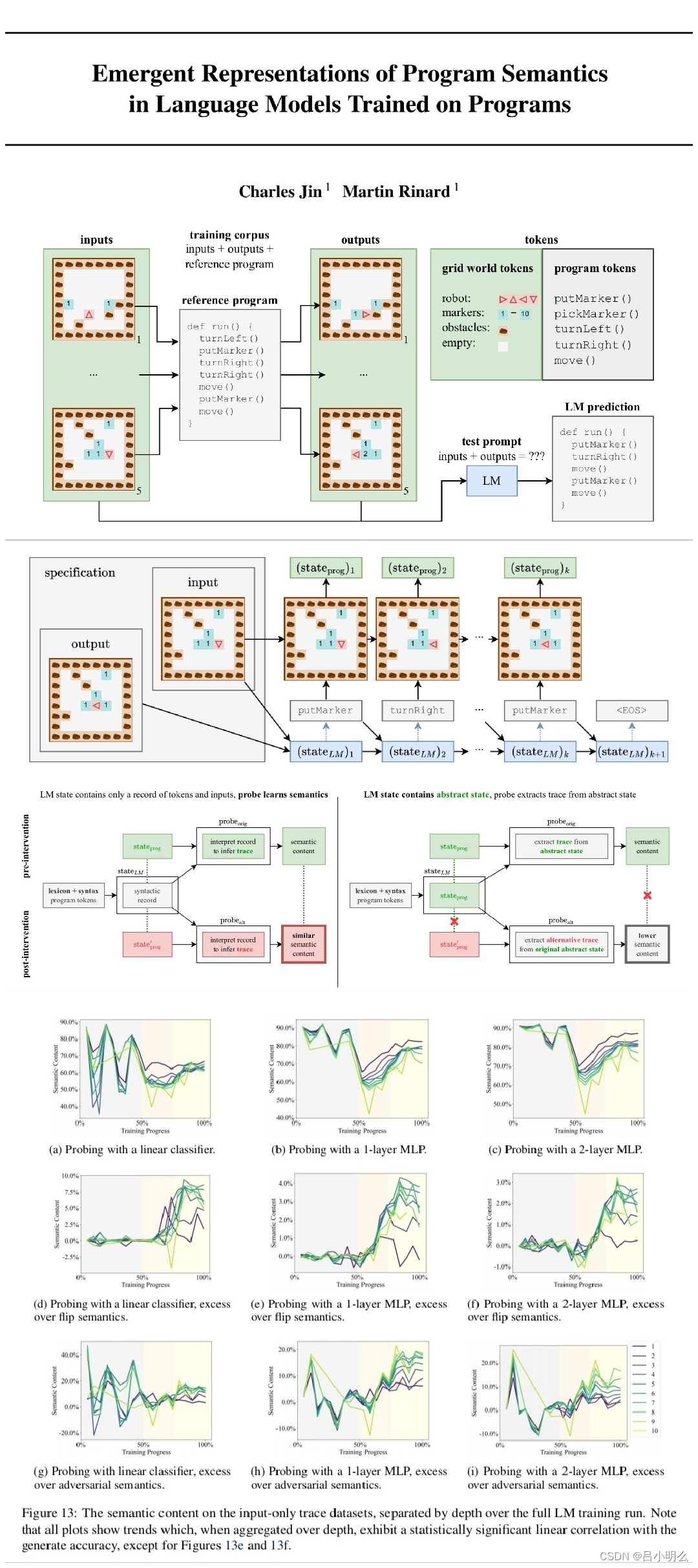
具体来说,MIT的两名学者发现——尽管只用「next token predict」这种看似只包含纯粹统计概率的自回归目标,来训练llm学习编程语言,其依旧可以学习到程序中的形式化语义。因为这一切发生在llm神经网络中的隐层,这表明,llm可能会发展自己对现实的理解,以此作为提高其生成能力的一种方式。
为了探究这个谜团,MIT的研究者们首先开发了一套小型卡雷尔谜题。其主要目的是构造一个“真实”有限域受控环境,以实现模型生成的指令内涵得到在环境中控制行动的映射。
同时,在构造了超过100万个随机谜题上进行训练的同时,嵌入了一种名为「思维探针」probing的技术,用于在模型生成新解决方案时,深入了解模型内部隐状态的表征即「思维过程」,其本质上是可由一个线性分类器、单或2层MLP进行某种程度的Abstract interpretation「抽象解释」,并使用这种抽象的解释来建立具体的现实程序状态和在实验中测量的抽象程序状态之间的精确的、形式化联系。
相应的结论应该不用多说了,即是:llm自己的隐层中实现了的内部模拟,来模拟机器人如何响应每条指令而移动。感兴趣的大伙可以去读下原论文,还是比较好理解的,与其它论文类似采用脑电生理介入原理的方式方式类同·均是通过某种方式跟踪或观察模型中隐空间激活状态。
正如作者所说,虽然这项研究存在一些局限性,即仅使用了非常简单的编程语言Karel,以及非常简单的probe模型架构。但本文优雅的实验设计,也让我们体现出一种乐观的心态,表明也许LLM可以更深入地了解语言的『含义』。
而让我更加兴奋的是回想起一年前自己曾思考的模型对于system2复杂推理过程中隐状态表征与现实推理逻辑上的映射统一的猜想...















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









