










来源:投稿 作者:小灰灰
编辑:学姐
了解数据
Q:我现在什么基础也没有,我要学习深度学习,学习cv,学习nlp。
A:首先我们知道,深度学习是建立在数据集的基础上。现在呢,我要有数据,数据可以选择官网下载,或者自己手机上随便找些数据。
假设我有下图人民币数据,有100张一元人民币和一百张100元人民币,总共200张,使用代码划分为训练,验证,测试集比例为8:1:1

现在我有数据啦,但怎么训练呢,就要了解epoch,iteration,batchsize
Epoch:是整个训练集数据样本都输入到模型里面了,称为一个epoch。
iteration:是一批样本输入到模型中,就称为一个iteration。
batchsize:是批大小,假设我们有一个数据集,里面包含80张图片,我把batchsize设置为8,那么我们需要10个iteration才能训练完整个数据集,就是一个epoch。
代码加载数据
现在我们知道了数据集,那么用代码怎样实现加载呢,就会用到pytorch框架里面的dataset,dataloader,或者tensorflow,mxnet框架里面的数据加载的方法。 我们要设置读取数据集的硬盘路径,

接下来构建dataset和dataloader

#构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
#构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
上面是准备工作,具体的开始在
for i, data in enumerate(train_loader):
#print(data)
# forward
inputs, labels = data
outputs = net(inputs)
可以看到train_loader里面会调用RMBDataset,那么下图就是这个类,最主要的就是__getitem__函数的编写。输入框架中随机打乱的index,得到数据和标签。因此,pytorch会从dataset里面shuffle=True的条件下,随机打乱形成index,复写__getittem__函数,将下标index输入,实现自己的功能。

因此最终获取数据出来的结果为:获取到图片的路径,然后用image读取出来。
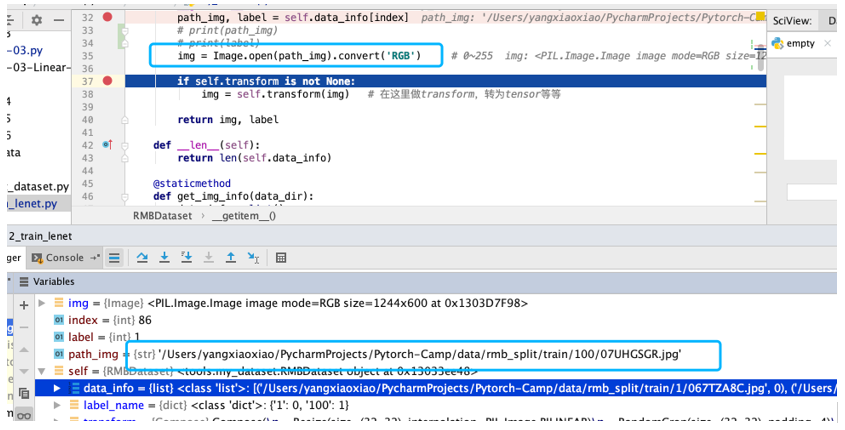
我们现在开始训练,拿到train_loader里面的值,就可以了。
数据预处理
当然上面的步骤只是单独的获取到了数据集,如果我们想要提高模型的泛化能力,就得使用transforms,对图片进行数据中心化,缩放,裁剪,填充等的一些操作,当然pytorch下的torchvision里面已经做好了基本的一些数据增强的操作。
那么我们就要知道,在框架中应该怎么写,根据上图RMBDataset这个类,在创建mydataset的时候就已经传进去框架里面指定好的数据增强类型。
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
那么我们就需要知道,到底框架哪里执行transforms运算。
根据第二步,我们在getitem中获取到数据,下一步就是数据增强。

这里的self.transform就会根据写的数据增强进行运算。

以上就是对数据进行处理的过程,那么对每一步数据增强,我们都可以进行可视化,看效果是否与自己一样。
点击下方卡片关注《学姐带你玩AI》🚀🚀🚀
回复“环境搭建”免费领取AI开发环境搭建视频教程
码字不易,欢迎大家点赞评论收藏!















 9484
9484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









