










来源:投稿 作者:橡皮
编辑:学姐

paper:https://arxiv.org/pdf/2201.13168.pdf
code:amirhertz/spaghetti (github.com)
背景:
近年来,人们对应用神经隐式场来表示 3D 形状和场景的兴趣激增。通过巧妙设计,此类参数化方法不会限制形状的分辨率,进而可以忠实地恢复底层的一些连续表面或体积。这些属性使它们成为开发新型生成技术的有趣媒介。
最近的大部分研究工作都集中在改进表征信号质量或利用隐式表征进行形状重建。虽然隐式表征在经典的形状建模文献中得到了很好的认可,但到目前为止,对基于神经隐式形状的编辑关注很少。特别是,在指定的用户控件上调节神经隐式形状的形式并不简单,这进一步阻碍了 3D 创意程序的应用。
在本文中,介绍了SPAGHETTI,一种支持直接编辑神经隐式形状的新型生成模型。本文框架允许通过以下方式进行部件级别的控制:
(i)对生成对象的局部区域应用转换;
(ii)混合和插入不同形状的片段。
主要贡献:
网络学习将局部零件表征彼此分开。这是必不可少的,因为对单个部分的修改对其余部分影响不大。网络经过训练可以在没有明确部件监督的情况下实现这种分离。每个部件表征都被分解为内部和外部组件,分别控制其详细的表面几何形状和嵌入3D 空间。这样做允许学习过程在形状部分上引入局部仿射变换,同时将它们保持在数据分布内。
为了能够编辑训练期间未见过的新形状,引入了形状反转优化,它为给定的没见过的形状找到匹配的零件代码。对解耦部分嵌入的中间潜在表征有助于在训练数据之外进行外推,并实现高质量的反演。
使用图形用户界面展示了方法的有效性,其中 SPAGHETTI 由八叉树加速,以允许 3D 隐式形状的交互式编辑体验。
方法概览:
-
首先,隐式形状生成模型学习将形状嵌入
分解为与不同3D 部分相对应的不同嵌入
-
然后,混合网络输出上下文嵌入
。
-
最后,隐式形状由第三个占用网络
给出,该网络以上下文部分嵌入为条件。
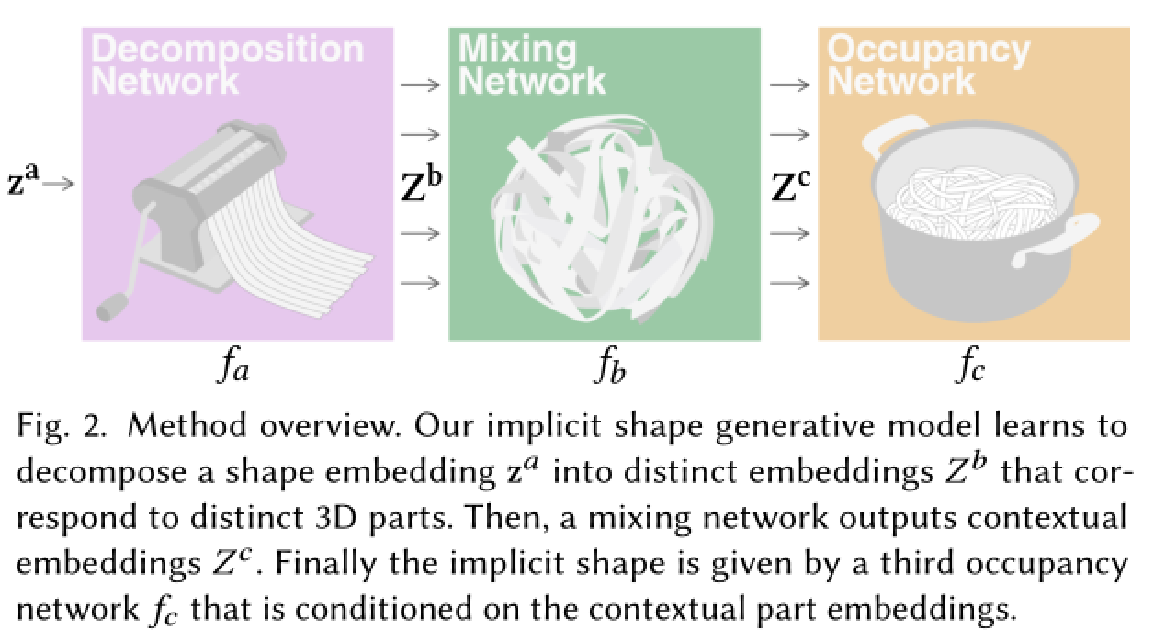
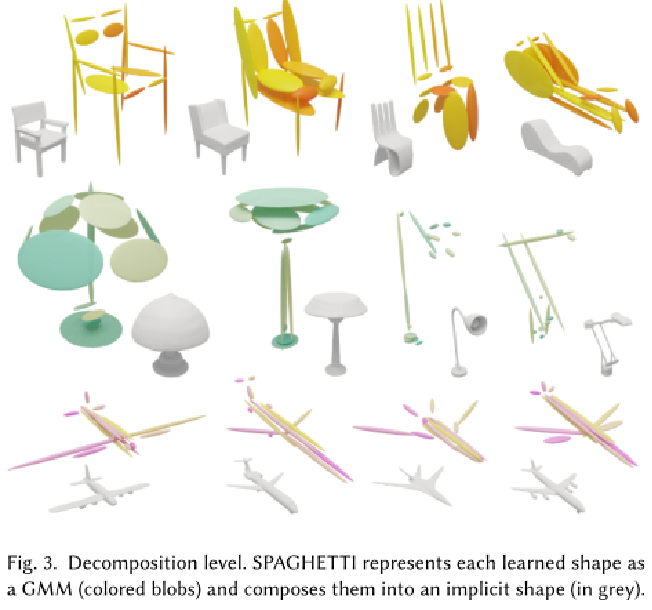
方法流程图:
训练一个仅有解码器网络,它:
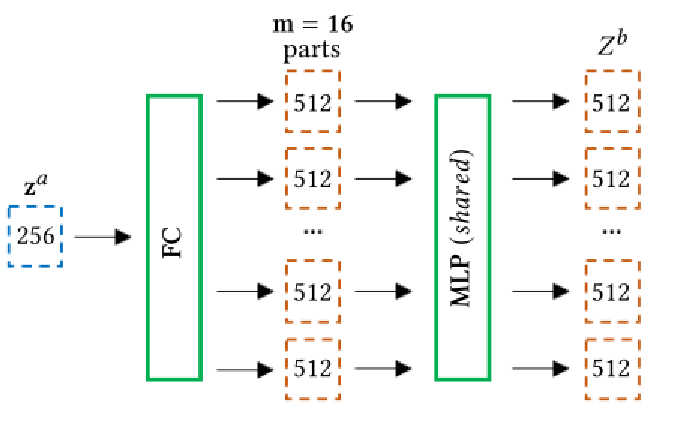
①将形状嵌入 分解为与高斯混合模型 (GMM) 相对应的不同部分嵌入
②将 的(掩码)集处理成上下文嵌入
③输出隐式形状,其中查询坐标 x 使用位置编码投影到高维空间,然后根据进行加权,确定占用指标
![]() 。部件分离是使用自我监督范式实现的,由GMM提供,用于重新标记真值标签y。局部变换控制是通过对高斯坐标和查询坐标应用刚性变换来实现的。
。部件分离是使用自我监督范式实现的,由GMM提供,用于重新标记真值标签y。局部变换控制是通过对高斯坐标和查询坐标应用刚性变换来实现的。
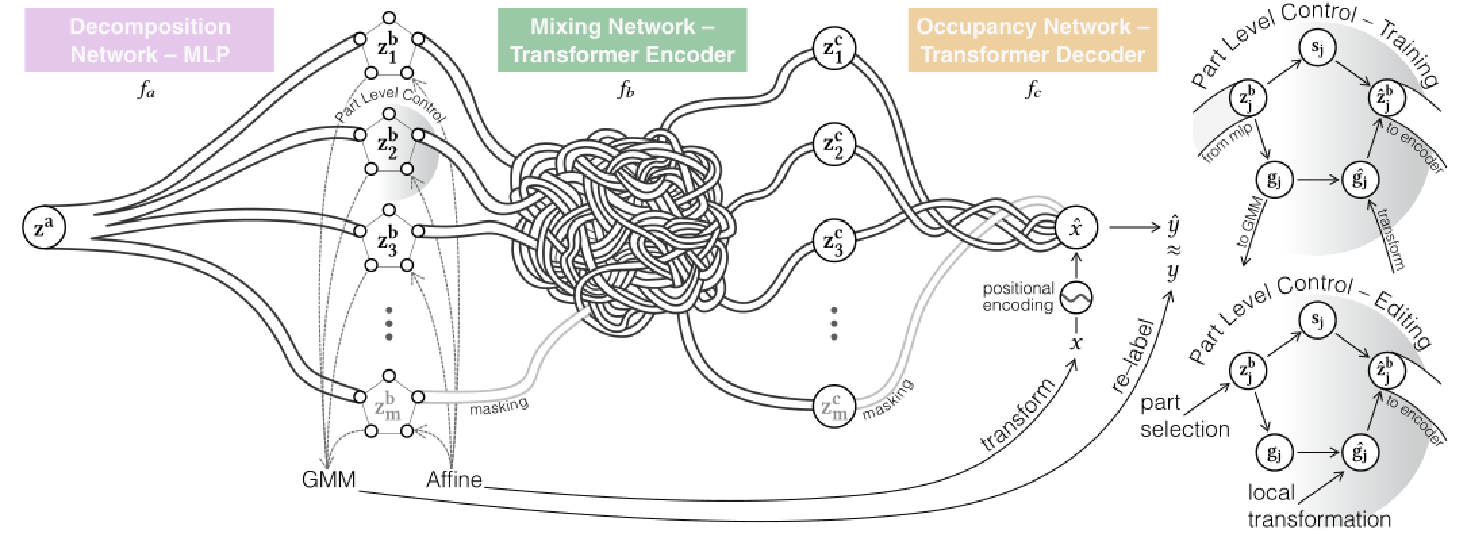
部件级别控制器。网络经过训练(右上)以具有表面几何形状 () 及其刚性属性
![]() 的解耦表征。在推理过程中(右下),用户可以组合和操作形状部件。
的解耦表征。在推理过程中(右下),用户可以组合和操作形状部件。
网络细节1:Decomposition network 分解网络
首要目标是获得给定形状的部分级分解,这构成了我们基于部件编辑的基础。SPAGHETTI 通过在零件分割及其操作上调节形状生成来利用这种能力。

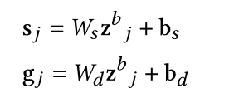

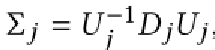

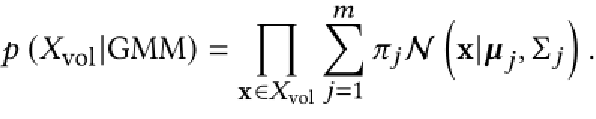
网络细节2:隐式形状构成器Implicit shape composer
这两个网络都是通过Vaswani等人[2017]的完整Transformer架构实现的,其中混合网络通过transformer编码器实现,以及
是解码器的定制变体。Transformer适合我们的任务,因为它具有从各个领域中的序列或无序集学习上下文表示的强大能力。
混合网络的Transformer编码器不使用位置编码,因为我们对无序集的嵌入感兴趣。全局感知表示是通过一系列多头注意力层获得的:
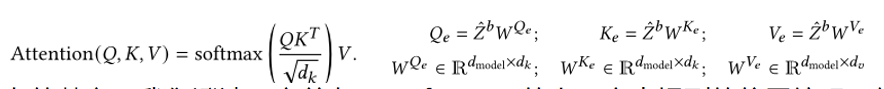
为了避免潜在的歧义,我们澄清了之前在Transformers的上下文中提到的位置编码,作为保持序列顺序的手段。类似的公式已经在神经隐式场的文献中进行了讨论,作为提高网络对基于坐标的输入的敏感性和克服光谱偏差的手段。我们的公式引用了后一种定义,即与基于坐标的网络相关的定义,并且在定义上更接近于单个SIREN层:
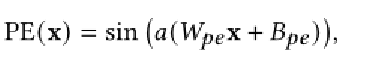
网络的交叉注意力:
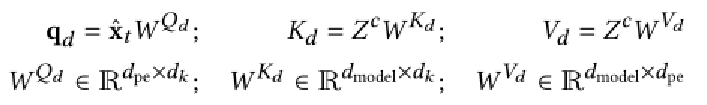
与经典的transformer解码器不同,我们从解码器中省略了自注意层。虽然允许对m 的二次依赖是可以接受的,但最好使网络运行时复杂度在B中保持线性。
最后部分是一个MLP,它解码了一个占用指示符. 占用损失由二进制交叉熵损失给出:
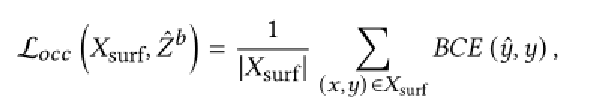
网络细节3:外在属性解耦 Disentanglement of extrinsic attributes
我们转而介绍外部几何分离组件,它可以对生成的形状进行局部变换控制。回想一下,我们已经通过将每个部分表示 投影到高斯
的堆叠表示来检索其几何属性,此外,我们还获得了详细的表面信息表示。
在下文中,我们尝试使嵌入对应用于形状部分的仿射变换不变。同时,我们希望到形状部分几何的映射相对于仿射变换是等变的。为此,我们对应用随机仿射变换T,以获得变换后的高斯。然后我们向上投影并将其注入到
中:
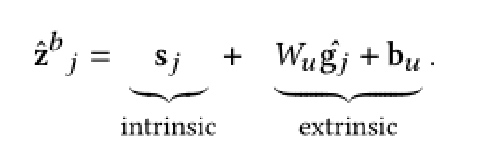
修改后的集合被转到组合网络。
最后,我们在上应用相同的变换T,使得输出隐函数学习模仿变换后的形状。
由此实现了外部和内部几何属性的分离。
网络细节4:部件级别分离 Part-level disentanglement
理想情况下,我们想要零件表征仅包含局部零件信息和上下文表征
带有全局意识。前者需要允许直观的零件编辑机制,而后者对于形状
![]() 的高质量重建至关重要。
的高质量重建至关重要。
尽管每个部分嵌入 对应于单一形状的高斯,不能保证额外的全局信息不会在相同形状的不同零件嵌入之间泄漏。事实上,这种“泄漏”可能会损害本地编辑的质量以及我们在形状之间混合零件的能力。为了克服这个问题,我们用额外的前向传播来增加每次训练迭代,这会促进
以包含局部信息并更好地分离高斯效应区域。
我们将每个坐标x∈到最大化其期望的高斯:
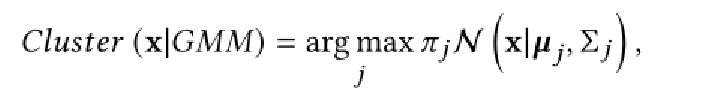
然后,重新标注占用y为:
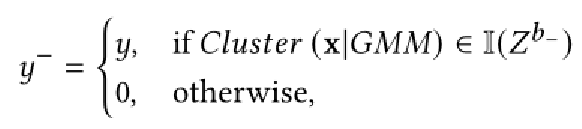
直观地,我们重新标记外部坐标,例如:聚集在的高斯外的坐标,作为“未占用”。然后,通过在修改集合上计算的占用损失项来给出部件级解解耦损失:
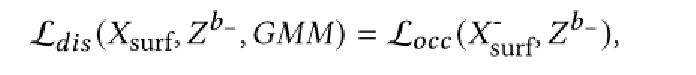
网络细节5:训练损失方程
我们网络的完整损失项由目前讨论的项给出:
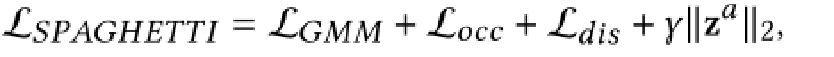
其中γ是控制损失权重的超参数。我们还对每个全局形状嵌入应用正则化∥∥2,正如之前的自动解码器所提倡的那样。潜在正则化促进形状代码呈正态分布。反过来,这使得全局形状代码的空间更容易从中采样。
实验结果:
量化指标
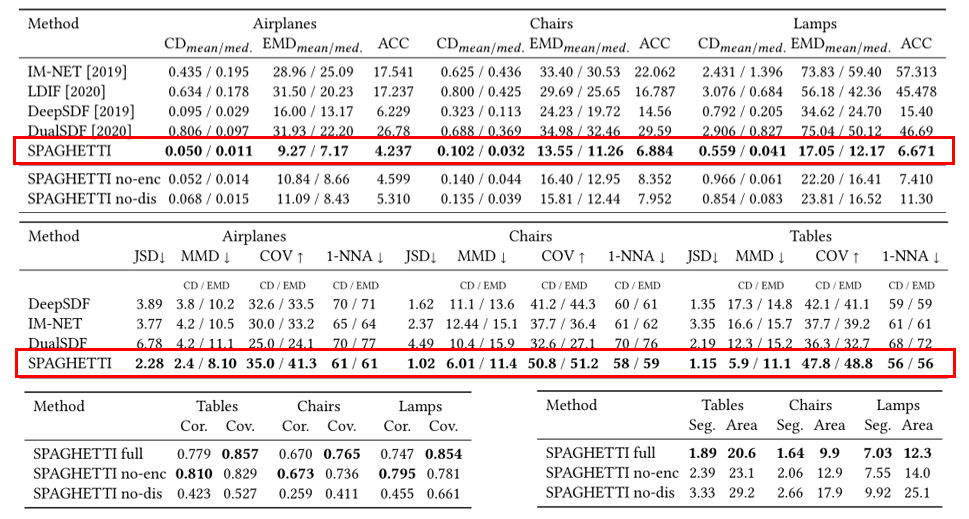
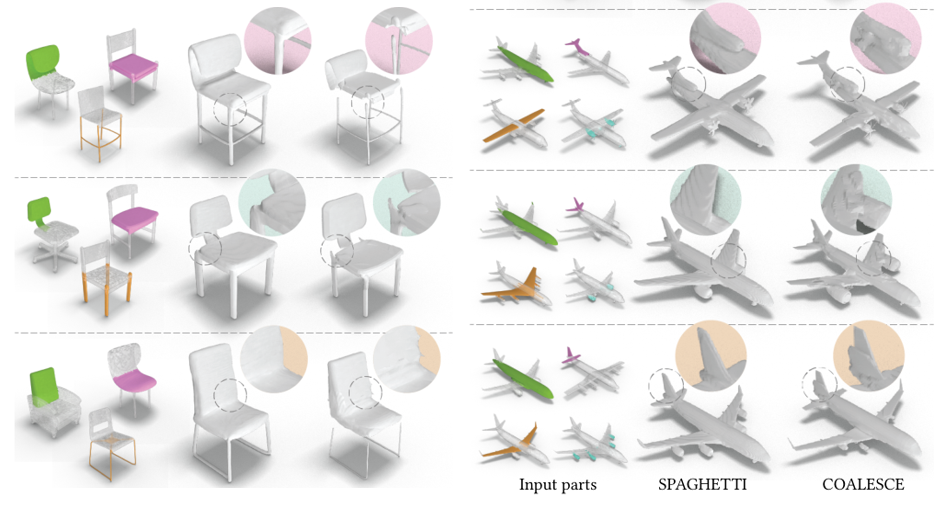
Mixing Comparison
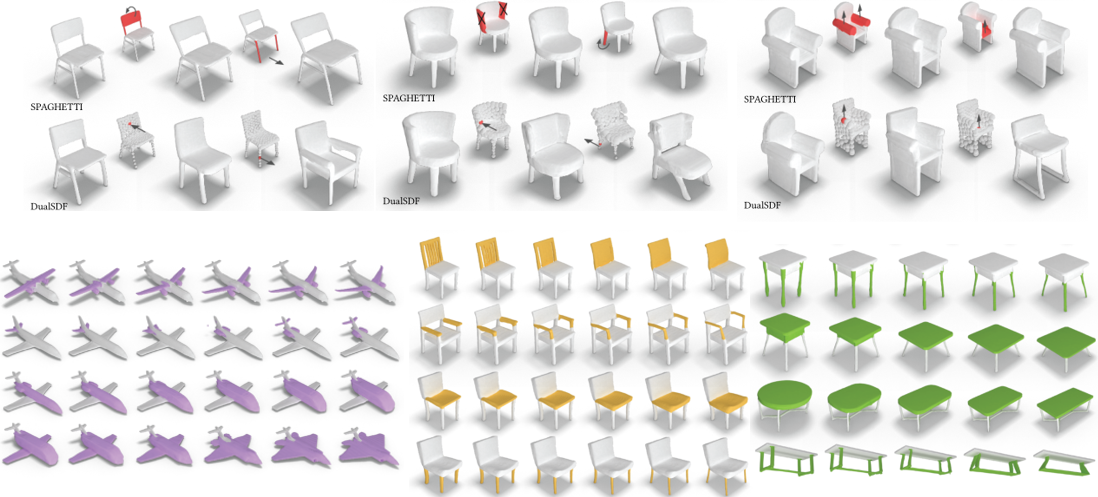
Sequential editing & Part level interpolation
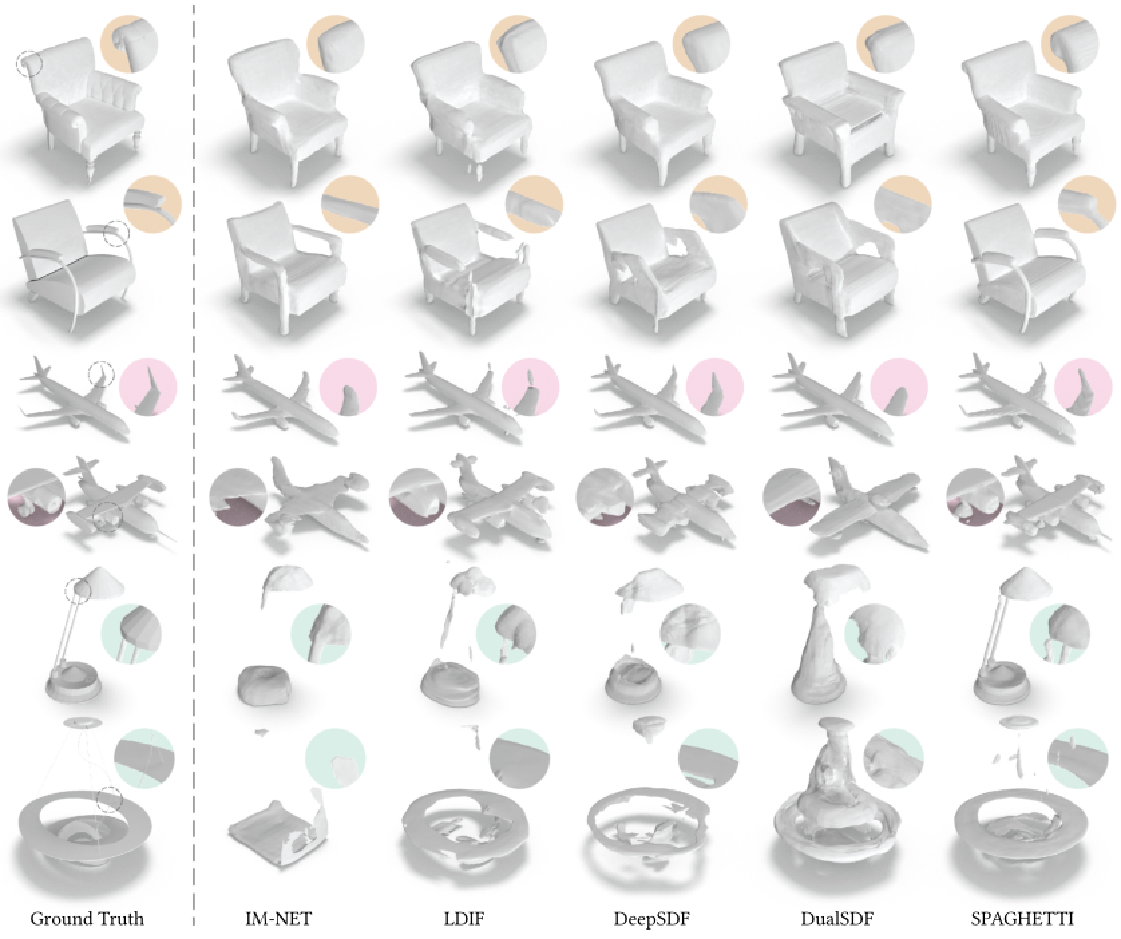
Shape inversion comparison
关注下方【学姐带你玩AI】🚀🚀🚀
免费领取人工智能学习大礼包(电子书、论文、教程视频...)
码字不易,欢迎大家点赞评论收藏!

















 3791
3791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









