









VLDB(International Conference on Very Large Data Bases)是数据库三大国际顶级学术会议之一,每届会议都设有研究(Research Track)、工业(Industrial Track)等方向,展示了当前数据库领域的前沿方向以及工业界最新的技术进展。
VLDB每年的录用率在18%左右,对作品的创新性、完整性、实验设计等方面要求十分严格,因此每篇录用论文质量都非常高,对于推动数据驱动决策、智能系统演进、应用创新等具有重要意义。
今年的VLDB 2023会议在加拿大温哥华落幕,共有9篇论文脱颖而出,荣获最佳论文奖。
为了方便同学们学习,今天我就帮大家整理了一下,除最佳论文奖之外,还补充了获2023 VLDB时间考验奖的论文,建议大家收藏起来慢慢看。
论文原文以及代码也都整理over,文末直接获取
最佳研究论文奖
Auto-Tables: Synthesizing Multi-Step Transformations to Relationalize Tables without Using Examples
标题:自动表格:综合多步转换以关系化表格而无需使用示例
作者:Peng Li (佐治亚理工学院); Yeye He (微软研究院); Cong Yan (微软研究院); Yue Wang (微软研究院); Surajit Chaudhuri (微软研究院)
内容:作者提出了一个名为"Auto-Tables"的系统,它可以自动化将非关系型表格转化为标准的关系型格式,使用多步骤的转换过程,而无需用户手动干预。作者进行了广泛的测试,并发现该系统可以在超过70%的测试案例中成功地快速转换,而无需用户的输入,使其成为数据准备和分析的有价值工具,适用于技术水平各异的用户。

DBSP: Automatic Incremental View Maintenance for Rich Query Languages
标题:DBSP: 富查询语言的自动增量视图维护
作者:Mihai Budiu (VMware 研究院); Tej Chajed (VMware 研究院); Frank McSherry (Materialize); Leonid Ryzhyk (VMware 研究院); Val Tannen (宾夕法尼亚大学)
内容:论文提供了增量视图维护在数据库理论中的长期核心问题的通用解决方案:(1)描述了一种称为DBSP的简单但表达力强的语言,用于描述对数据流的计算;(2)提供了一个通用算法,用于解决任意DBSP程序的增量视图维护问题;(3)展示如何使用DBSP对许多丰富的数据库查询语言进行建模(包括全面的关系查询、分组和聚合、单调和非单调递归以及流式聚合),从而获得了所有这些丰富语言的高效增量视图维护技术。

最佳研究论文亚军
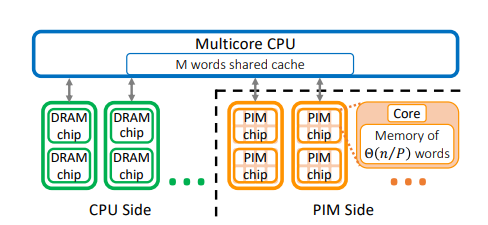
PIM-tree: A Skew-resistant Index for Processing-in-Memory
标题:PIM-tree:一个抗偏斜的内存处理索引
作者:Hongbo Kang (清华大学); Yiwei Zhao (卡内基梅隆大学); Guy E Blelloch (卡内基梅隆大学); Laxman Dhulipala (马里兰大学学院市分校); Yan Gu (加州大学河滨分校); Charles McGuffey (里德学院); Phillip B Gibbons (卡内基梅隆大学)
内容:这篇论文提出了一种面向PIM系统的有序索引结构PIM树,可以在工作负载存在不同程度的偏斜时仍保持低通信量和高负载平衡,从而大幅提升内存索引的性能。该方法是基于主机CPU和PIM节点之间的新型分工,并引入了根据工作负载偏斜动态调整的推拉搜索机制。在实际PIM系统上的实现表明,相比现有PIM索引方法,PIM树可以提供更高的吞吐量。
最佳实验、分析与基准论文奖
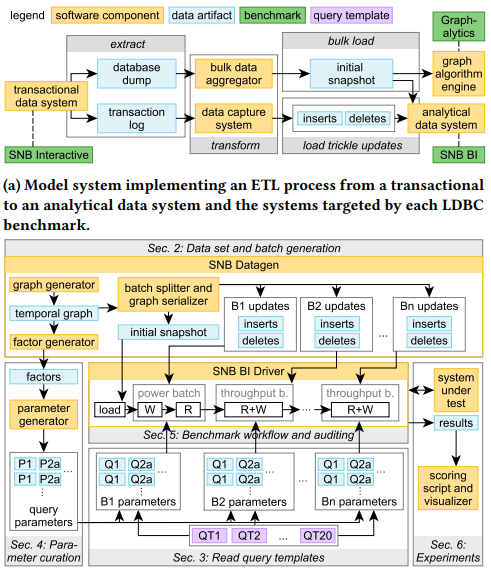
The LDBC Social Network Benchmark: Business Intelligence Workload
标题:LDBC社交网络基准:商业智能工作负载
作者:Gabor Szarnyas (CWI); Jack Waudby (纽卡斯尔大学); Ben Steer (pometry); David Szakallas (LDBC); Altan Birler (TUM); Mingxi Wu (Tigergraph); Yuchen Zhang (TigerGraph); Peter Boncz (CWI)
内容:SNB BI是第一个面向支持图工作负载的分析数据系统的全面图OLAP基准测试。它的特点是:1)使用复杂的数据生成器产生具有小世界现象的社交网络图;2)查询工作负载利用数据的偏斜性和相关性;3)首次在基准中采用参数策展技术;4)定义了两个评测指标。该基准测试可以促进未来图数据库系统的发展。
最佳实验、分析与基准论文亚军
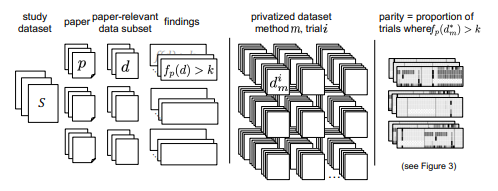
Epistemic Parity: Reproducibility as an Evaluation Metric for Differential Privacy
标题:认识论均等:可复制性作为差分隐私的评估指标
作者:Lucas Rosenblatt (纽约大学); Bernease Herman (华盛顿大学); Anastasia Holovenko (乌克兰天主教大学); Wonkwon Lee (纽约大学); Joshua Loftus (伦敦经济学院); Elizabeth McKinnie (微软); Taras Rumezhak (乌克兰天主教大学); Andrii Stadnik (乌克兰天主教大学); Bill G Howe (华盛顿大学); Julia Stoyanovich (纽约大学)
内容:这篇文章提出了一种针对差分隐私数据合成器的新的评估方法,该方法通过重现使用真实数据的同行评议论文的结论,在合成数据上重新运行实验,比较结果,来估计结论在使用合成数据时是否会改变。结果表明,当前的差分隐私合成器在一定隐私级别下可以实现较高的重现性,但对某些论文及结论的重现仍具挑战。因此需要开发新型机制,优先保证效用而非仅仅隐私。
A Deep Dive into Common Open Formats for Analytical DBMSs
标题:对分析型DBMS的常见开放格式的深入探究
作者:Chunwei Liu (MIT); Anna Pavlenko (微软 Gray Systems实验室); Matteo Interlandi (微软); Brandon Haynes (微soft Gray Systems实验室)
内容:这篇论文评估了Apache Arrow、Parquet和ORC作为分析型数据库管理系统中支持归纳的格式的适用性。作者系统地确定和探索了支持现代OLAP数据库管理系统高效查询的重要的高级特性,并评估了每种格式支持这些特性的能力。作者发现每种格式都有权衡取舍,使其作为数据库管理系统中的格式更适合或不太适合,并确定了更全面协同设计统一内存和磁盘数据表示的机会。
最佳行业论文奖
Kora: A Cloud-Native Event Streaming Platform For Kafka
标题:Kora:一个面向Kafka的云原生事件流平台
内容:Confluent Cloud是一个用于事件流处理的云原生解决方案,其核心是建立在Apache Kafka之上的Kora平台。本文介绍了Kora的设计,它实现了云原生的目标,如可靠性、弹性和成本效率。Kora提供了抽象,使用户可以根据工作负载需求进行思考,而不需要考虑底层基础设施。Kora还致力于在不同的云环境下提供一致可预测的性能表现。总体来说,Kora是一个面向Apache Kafka的云原生平台,为Confluent Cloud提供支持。
最佳行业亚军
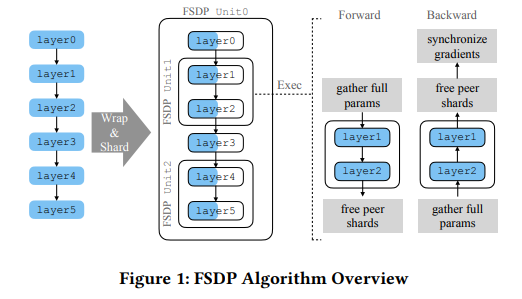
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
标题:PyTorch FSDP:在完全分片数据并行上的经验
内容:本文介绍了PyTorch Fully Sharded Data Parallel (FSDP),这是大模型训练的业界级解决方案。FSDP与PyTorch的几个关键组件如张量实现、调度系统和CUDA内存缓存分配器紧密协作,以提供无缝的用户体验和高训练效率。此外,FSDP内置了一系列技术和设置来优化各种硬件配置的资源利用。实验结果表明,FSDP能够达到分布式数据并行的可比性能,并为规模更大的模型提供近乎线性的可扩展性。
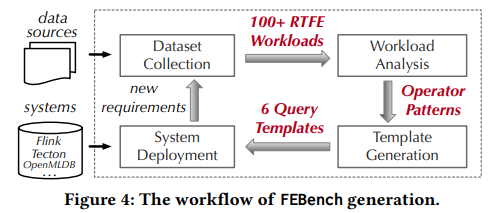
FEBench: A Benchmark for Real-Time Relational Data Feature Extraction
标题:FEBench: 用于实时关系数据特征提取的基准
作者:Xuanhe Zhou(清华大学); Cheng Chen(第四范式); Kunyi Li(清华大学); Bingsheng He(新加坡国立大学); mian lu(第四范式公司)*; Qiaosheng Liu(第四范式); Wei Huang(第四范式); Guoliang Li(清华大学); zhao zheng(第四范式公司); Yuqiang Chen(第四范式)
内容:论文提出了一个名为FEBench的实时特征提取基准测试,该基准测试基于Jim Gray提出的特定领域基准测试的四个重要标准。FEBench由选定的代表性数据集、查询模板和在线请求模拟器组成。作者使用FEBench来评估包括OpenMLDB和Flink在内的特征提取系统的效果。并发现每个系统在整体延迟、尾延迟和并发性能方面都展现出独特的优势和局限性。
2023 VLDB时间考验奖
Distributed Graphlab: A framework for machine learning in the cloud
标题:分布式Graphlab:一个云计算机器学习框架
作者:Yucheng Low, Joseph Gonzalez(加州大学伯克利分校), Aapo Kyrola, Danny Bickson, Carlos Guestrin, Joseph M. Hellerstein(加州大学伯克利分校)
内容:在本文中,作者将GraphLab框架扩展到了substaintially更具挑战性的分布式环境,同时保留了强的数据一致性保证。作者开发了基于图形的管道锁定和数据版本控制扩展,以减少网络拥塞并减轻网络延迟的影响。作者还使用经典的Chandy-Lamport快照算法为GraphLab引入了容错能力,并演示了如何通过利用GraphLab抽象本身来轻松实现它。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“VLDB”获取全部获奖论文+代码合集
码字不易,欢迎大家点赞评论收藏!















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









