









今天来聊聊计算机视觉和自然语言处理交叉的一个热门研究方向:视觉问答(VQA)。
视觉问答的任务是:给出一张图片和一个关于这张图片的自然语言问题,计算机需要根据图片的内容自动回答这个问题。这样的任务考验了计算机在图像理解和语言理解上的能力,需要计算机可以像人一样从图片中抽取信息,理解问题,并用自然语言给出合理的回答。
作为计算机视觉与语言交互的新兴研究热点,视觉问答涉及了图像处理、计算机视觉、自然语言处理等多个领域的技术,是评估计算机视觉系统整体语义理解能力的新方向。
近年来,针对视觉问答方向的研究成果日益增多,各大顶会中的相关论文数量也逐年攀升,我这回就整理了一些视觉问答顶会论文(CVPR、ACL)和大家分享,包括工作中常用的VQA数据集。
论文原文及代码数据集都打包了,需要的同学看文末
常用VQA数据集
通用型 VQA
1.VQA
VQAv1论文:VQA: Visual Question Answering
【视觉问答】
简介:论文提出了一个开放式视觉问答任务:给定图像和问题,回答问题。问题和回答都是开放式的,问题可以询问图像不同区域的细节。因此,视觉问答系统通常需要比图像字幕系统对图像有更深入理解和复杂推理。论文提供包含数百万张图像、问题和答案的大规模数据集,讨论它的信息量。
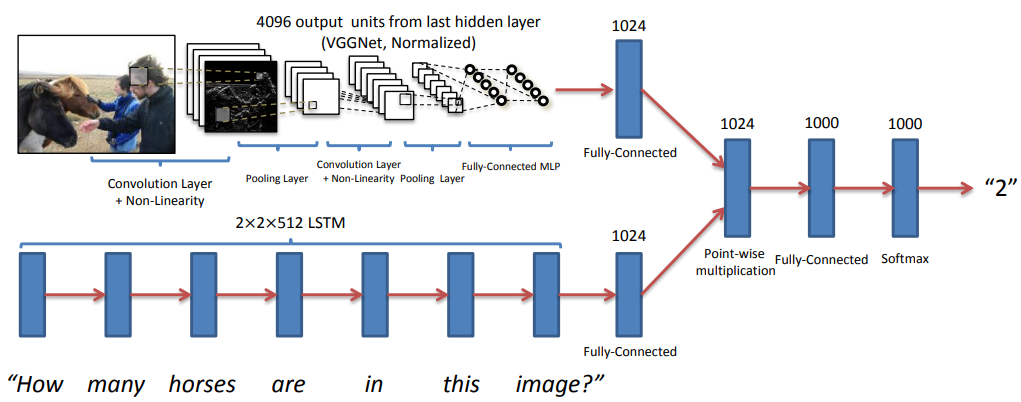
VQAv2论文:Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
【提升图像理解在视觉问答中的作用】
简介:通过收集每个问题对应不同答案的相似图像,构建视觉问答的平衡数据集,测试主流模型表现大幅下降,说明这些模型过于依赖语言先验。论文的数据集构造方法也启发了一个新的可解释的模型,它不仅给出答案,还基于反例图像提供解释,可以建立机器与用户之间的信任。

2.OK-VQA
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
【一个需要外部知识的视觉问答基准测试】
简介:OK-VQA是第一个大规模的需要外部知识才能回答视觉问答问题的基准测试集。它包含超过14000个开放域的问题,每个问题有5个标注答案。问题的构造保证单凭图像内容无法回答,需要利用外部知识库。结果显示当前VQA模型在该数据集上的表现严重下降,说明模型过于依赖语言先验。

3.VizWiz-VQA
VizWiz Grand Challenge: Answering Visual Questions from Blind People
【VizWiz大挑战:回答视障人士的视觉问题】
简介:VizWiz是第一个源自真实视觉问答场景的数据集。它包含超过31,000个视觉问答对,由视障用户拍摄图片并提出语音问题,每个问题有10个群众标注答案。VizWiz与现有VQA数据集不同:1)图像质量较差,拍摄者为视障人士,2)问题为语音形式,更具会话性,3)部分问题无法回答。在该数据集上评估现代VQA算法,结果显示VizWiz是一个有挑战性的数据集。

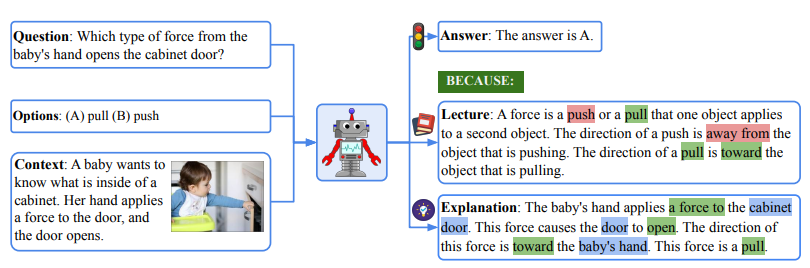
4.ScienceQA
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
【利用思维链进行多模态推理以回答科学问题】
简介:ScienceQA是第一个大规模多模态科学问题回答基准,包含约21k个多项选择题,并标注了对应的讲义和解释作为答案的思维链。作者设计语言模型学习生成讲义和解释,模拟人回答问题的多跳推理过程。结果显示,思维链可以提高GPT-3和UnifiedQA的少样本和微调表现。
5.TDIUC
An Analysis of Visual Question Answering Algorithms
【对视觉问答算法的分析】
简介:现有的VQA数据集存在内容和评估方式上的缺陷,导致评估分数被夸大,主要由较简单的问题决定,难以比较不同方法。本文利用包含超过160万个问题的新数据集分析现有VQA算法,问题按12个类别组织,并设计无意义问题迫使模型进行图像内容推理。

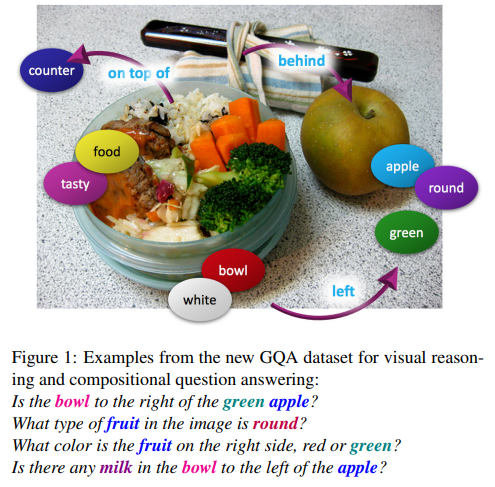
6.GQA
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
【一个用于真实世界视觉推理和组合式问答的新数据集】
简介:GQA是一个大规模真实世界视觉推理和组合式问答数据集。它通过场景图来生成复杂的推理性问题,并提供语义表示的功能程序。该数据集引入了一套新的指标来评估一致性、逻辑性等关键属性,为提升模型鲁棒性、一致性和图像语言理解提供了重要的基准资源。
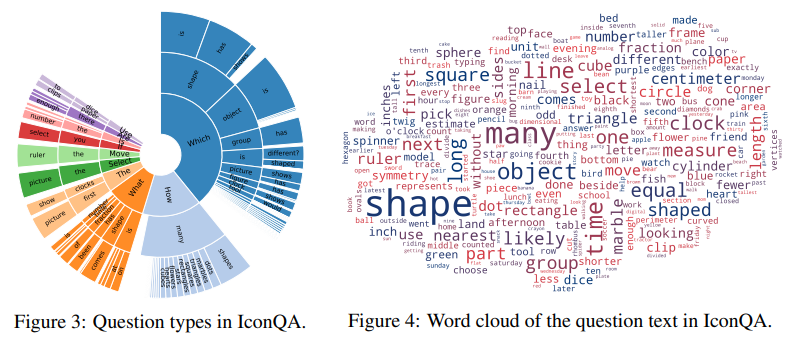
7.IconQA
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
【抽象图表理解和视觉语言推理的新基准】
简介:IconQA是一个新的抽象图表视觉问答基准,包含10万个图表及相关问题。不同于自然图像,抽象图表的语义理解仍是视觉研究的难点。IconQA中的图表需进行几何、常识、算术等复合推理来回答问题,作者还构建了包含65万彩色图标的Icon645数据集。IconQA要求模型深入理解抽象语义和进行复合推理,是视觉语言理解任务的新方向。
文本导向的 VQA
1.OCR-VQA
OCR-VQA: Visual Question Answering by Reading Text in Images
【通过读取图像中的文本进行视觉问答】
简介:本文提出通过读取图像中的文本(OCR)进行视觉问答(OCR-VQA)这个新任务,作者为此构建了一个大规模数据集OCRVQA-200K,包含20多万张书籍封面图像及100多万个相关问答对。实验结果显示,这个任务面临文本检测、识别、语义理解等多方面挑战。
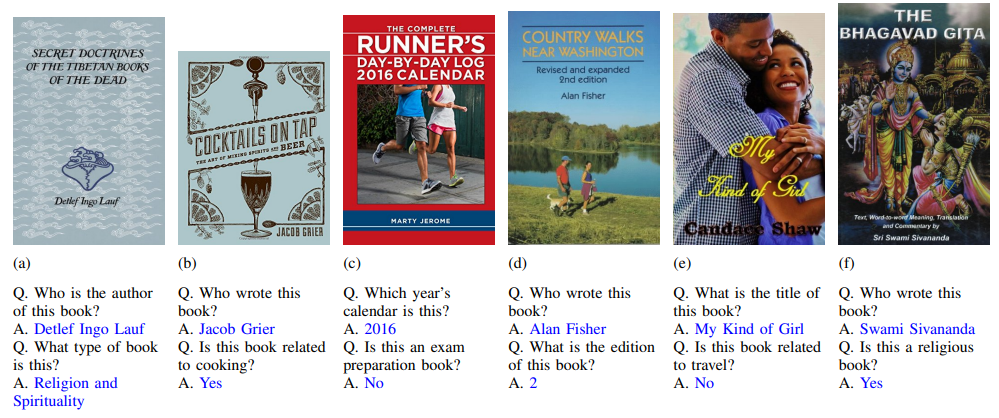
2.TextVQA
Towards VQA Models That Can Read
【迈向能够阅读的VQA模型】
简介:本文提出TextVQA任务和数据集,需要VQA模型读取图像文本并进行多模态推理。提出LoRRA模型,可以检测、理解图像文本并进行问答。结果显示TextVQA上的人机差距大于VQA 2.0,可以有效评估文本理解和多模态推理能力。

VQA顶会论文合集
CVPR
-
1.SimVQA: Exploring Simulated Environments for Visual Question Answering
-
2.A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering
-
3.SwapMix: Diagnosing and Regularizing the Over-reliance on Visual Context in Visual Question Answering
-
4.Dual-Key Multimodal Backdoors for Visual Question Answering
-
5.MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
-
6.Grounding Answers for Visual Questions Asked by Visually Impaired People Maintaining Reasoning Consistency in Compositional Visual Question Answering
ACL
-
1.Co-VQA : Answering by Interactive Sub Question Sequence
-
2.xGQA: Cross-Lingual Visual Question Answering
-
3.CLIP Models are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment
-
4.CARETS: A Consistency And Robustness Evaluative Test Suite for VQA
-
5.Hypergraph Transformer: Weakly-Supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering
-
6.DuReader_vis: A Chinese Dataset for Open-domain Document Visual Question Answering
关注下方《学姐带你玩AI》🚀🚀🚀
回复“VQA”获取全部论文+源代码+数据集
码字不易,欢迎大家点赞评论收藏

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









