









原始的NeRF主要针对静态场景设计,对于动态场景的处理能力有限。改进后的NeRF通过引入时间维度或者与其他动态建模方法结合,能够更好地处理动态对象和场景。比如NeRF-HuGS模型。
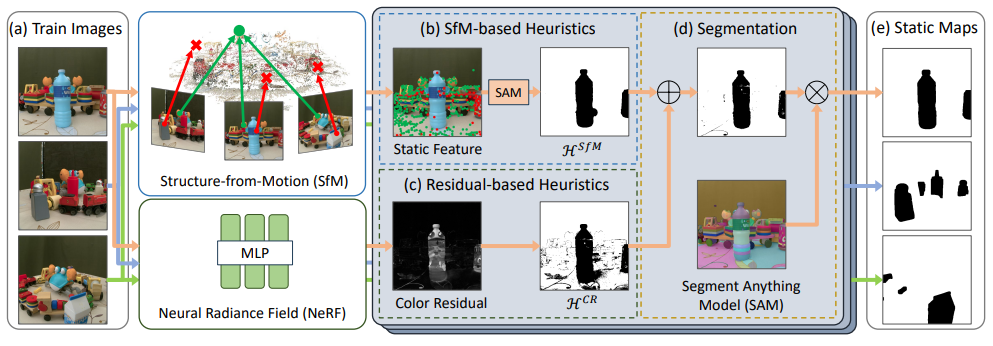
NeRF-HuGS旨在改进神经辐射场在非静态场景中的表现。通过使用启发式方法提供粗略的静态对象线索,并使用分割模型对这些线索进行精确的分割,生成准确的静态地图,从而实现对复杂场景中瞬态干扰的高效处理。
在减轻非静态场景中的短暂干扰物方面,NeRF-HuGS取得了SOTA效果。
除以上优势,改进的NeRF还可以做到:
-
通过优化算法和网络结构,减少所需的计算量,加快渲染速度,提升计算效率。比如谷歌的MobileNeRF模型,比SNeRG渲染速度快10倍,输出质量几乎相同。
-
通过增加语义信息或采用更通用的网络结构,提高对不同场景和目标类别的适应性,提升泛化能力。
因此,针对NeRF的改进也是最近发文的热门方向,且成果颇丰。本文整理了11个NeRF最新改进方案,开源的都附上了代码方便复现,希望能给各位的论文加加速。
论文原文以及开源代码需要的同学看文末
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
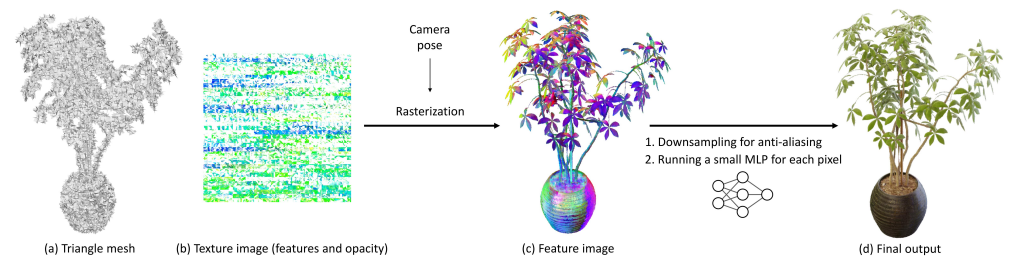
方法:MobileNeRF是一种可以在各种常见移动设备上以交互帧率运行的NeRF架构。该方法使用纹理多边形来表示NeRF,并利用传统的光栅化渲染管道进行高效的图像渲染。渲染过程中,使用z-buffer进行多边形光栅化,得到每个像素的特征向量,并将其传递给在GLSL片段着色器中运行的轻量级多层感知机(MLP),以生成最终的像素颜色。
创新点:
-
MobileNeRF通过使用带有纹理的多边形来表示NeRF,实现了在标准渲染管道下高效渲染表面型神经场。
-
MobileNeRF使用了离散的不透明度来避免对多边形进行深度排序,从而实现了在标准渲染管道下处理半透明多边形的能力。它通过对特征进行超采样来进行抗锯齿处理,提高了渲染质量。
-
MobileNeRF通过在HTML网页中使用WebGL和three.js库实现交互式查看器,可以在各种设备上运行,并且与SNeRG相比,需要的GPU内存更少。
-
MobileNeRF还通过在训练过程中逐步优化NeRF的连续表示,从而得到了一个显式的多边形网格表示。

GSNeRF: Generalizable Semantic Neural Radiance Fields with Enhanced 3D Scene Understanding
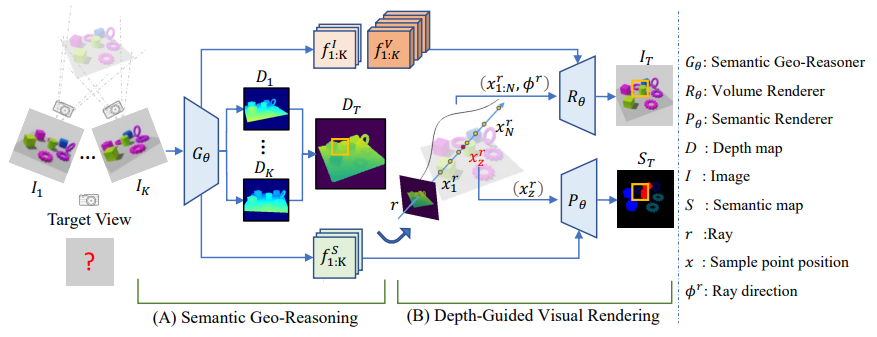
方法:本文提出了通用的语义神经辐射场(GSNeRF)方法,用于在未见过的场景中进行新视角图像合成和语义分割。
GSNeRF由两个阶段组成:语义地理推理和深度引导的可视化渲染。通过从多视角图像中提取视觉特征和每个源视角的深度预测,GSNeRF能够估计目标视角的深度图,并利用该深度信息进行图像和语义渲染。
创新点:
-
GSNeRF是一种通用的神经辐射场模型,用于合成新视角图像和语义分割。
- GSNeRF包含两个关键的学习阶段:语义几何推理和深度引导的可视化渲染。
-
在语义几何推理阶段,GSNeRF通过观察多视角图像输入,从场景中提取语义和几何特征。
-
在深度引导的可视化渲染阶段,GSNeRF使用预测的深度信息执行图像和语义渲染,提高了渲染效果。
-
GSNeRF通过深度引导的采样策略实现了对采样点数量不敏感的性能,保持了视觉质量和细节。
-
-
GSNeRF在新视角图像合成和语义分割合成方面表现出色,优于现有的通用语义感知NeRF方法。

Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
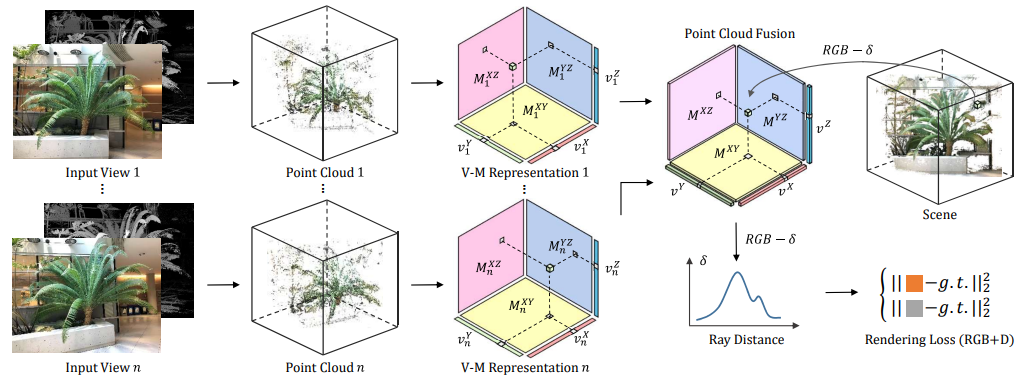
方法:本文介绍了一种新的深度引导的稀疏视角输入点云融合NeRF方法。该方法通过迭代地优化平面和向量,在训练过程中对整个场景的点云进行组合,通过从其他视角获取的深度值修正或替换不准确的深度值。
创新点:
-
本文首次将点云融合引入NeRF框架,提出了用于稀疏输入的深度引导的强大且快速的点云融合NeRF方法。
-
通过矢量矩阵分解技术,实现了更快的重建速度和更高的紧凑性。
-
通过点云融合和体素网格优化,可以有效地改进深度值的准确性。
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
方法:本文提出了一个统一的框架CustomNeRF,用于支持自适应源驱动的3D场景编辑。该框架利用一个主题感知的文本到图像(T2I)模型,将参考图像中包含的特定视觉主体V * 嵌入到混合提示中,满足通用和特定的编辑要求。
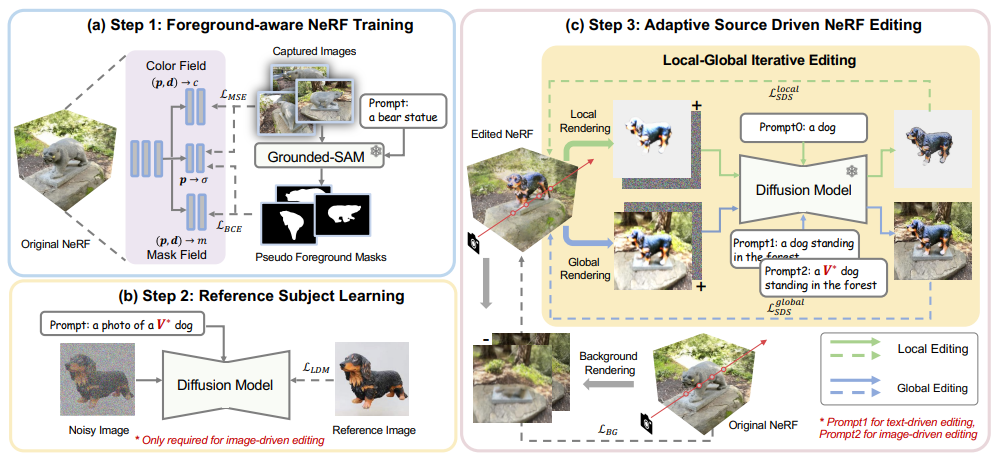
创新点:
-
提出了CustomNeRF模型,用于自适应源驱动的三维场景编辑,可根据文本或参考图像进行统一的编辑提示。通过解决确保仅对前景进行编辑和在使用单视图参考图像时保持多视图一致性这两个关键挑战,实现了精确的编辑。
-
提出了一种类别引导正则化方法,利用T2I模型中的类别先验信息,以缓解图像驱动编辑中的Janus问题。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“辐射11”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









