









损失函数+注意力机制在深度学习领域是一个热门研究方向,它可以提高模型的性能和泛化能力,帮助我们构建更加精确且高效的模型。
具体来说:
-
通过结合注意力机制的聚焦能力和损失函数的优化指导,模型能够更精确地捕捉数据中的关键信息,同时减少不必要的计算消耗。这不仅提高了预测精度,还能加速模型推理过程。
-
注意力机制在处理长序列或捕捉复杂依赖关系时占据优势,而损失函数则为模型提供了清晰的优化目标。这种结合能让模型更加有效地利用数据,不断改善其行为以达预期目标。
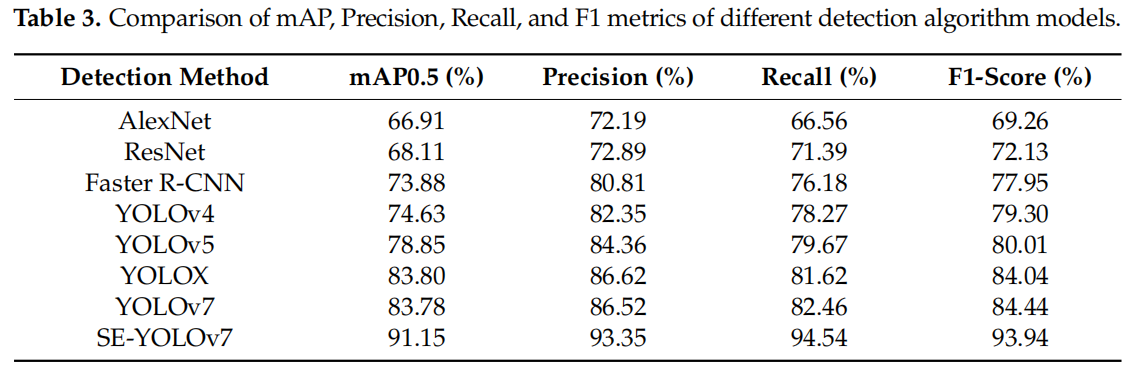
比如SE-YOLOv7,它在模型中引入挤压激励注意力机制,并将原始损失函数替换为VariFocal损失函数,在滑坡识别的AP、精确度、召回率和F1分数分别达到91.15%、93.35%、94.54%和93.94%。
目前,损失函数结合注意力机制已经成为了深度学习领域的重要工具,被众多研究者广泛探索。为帮助同学们从中获取灵感,除SE-YOLOv7外,我还整理了9种结合创新方案,原文以及开源代码都附上了,方便同学们学习。
论文原文以及开源代码需要的同学看文末
SE-YOLOv7 Landslide Detection Algorithm Based on Attention Mechanism and Improved Loss Function
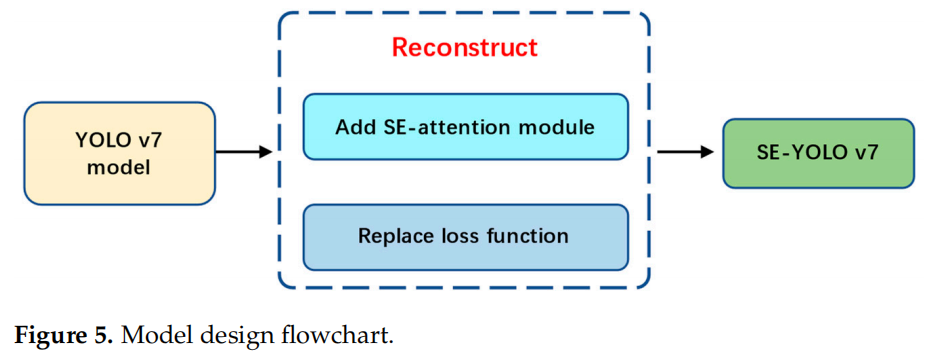
方法:论文基于YOLOv7算法模型进行创新,提出了一种新的SE-YOLOv7模型,通过添加SE压缩注意机制和VariFocal损失函数,进一步提高了遥感图像中复杂背景下对滑坡的检测精度。研究通过构建包含各种类型滑坡遥感图像的DN滑坡数据集,对滑坡进行识别研究。
创新点:
-
引入了Squeeze Excitation (SE)机制到YOLOv7模型中,构建了SE-YOLOv7深度学习模型,用于对遥感图像中复杂背景下的滑坡进行自动识别。
-
通过对SE-YOLOv7、YOLOv7和YOLOX的检测结果与现场调查结果进行比较,证明了SE-YOLOv7模型在复杂滑坡遥感图像中具有更高的检测精度,能够更准确地定位滑坡位置,检测范围更准确,漏检较少,具有广泛的应用前景。
Relation-Aware Network with Attention-Based Loss for Few-Shot Knowledge Graph Completion
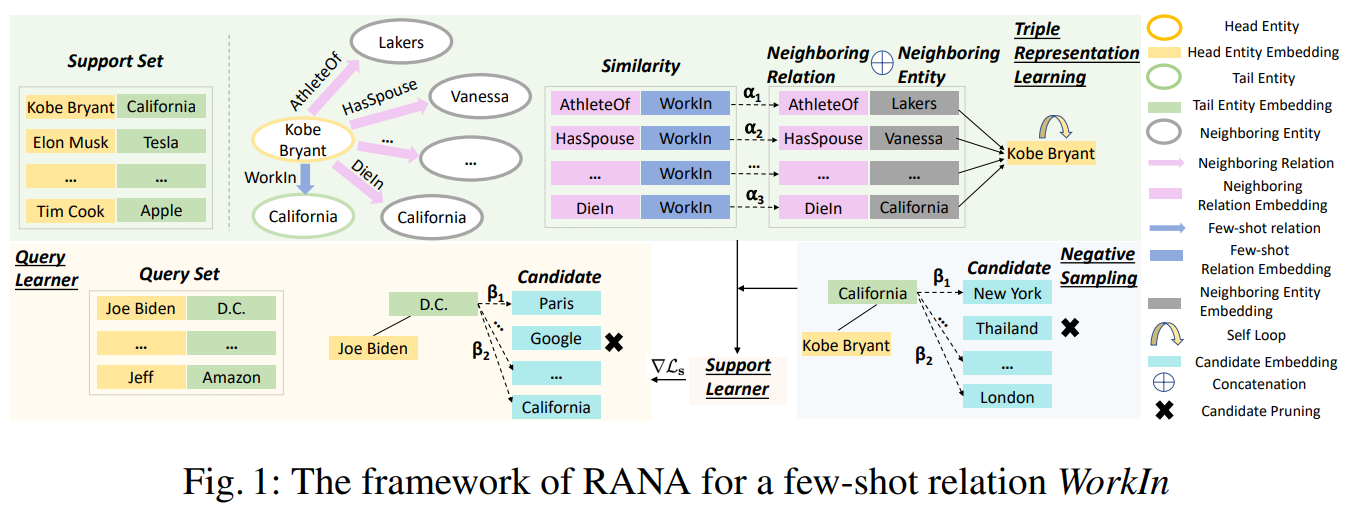
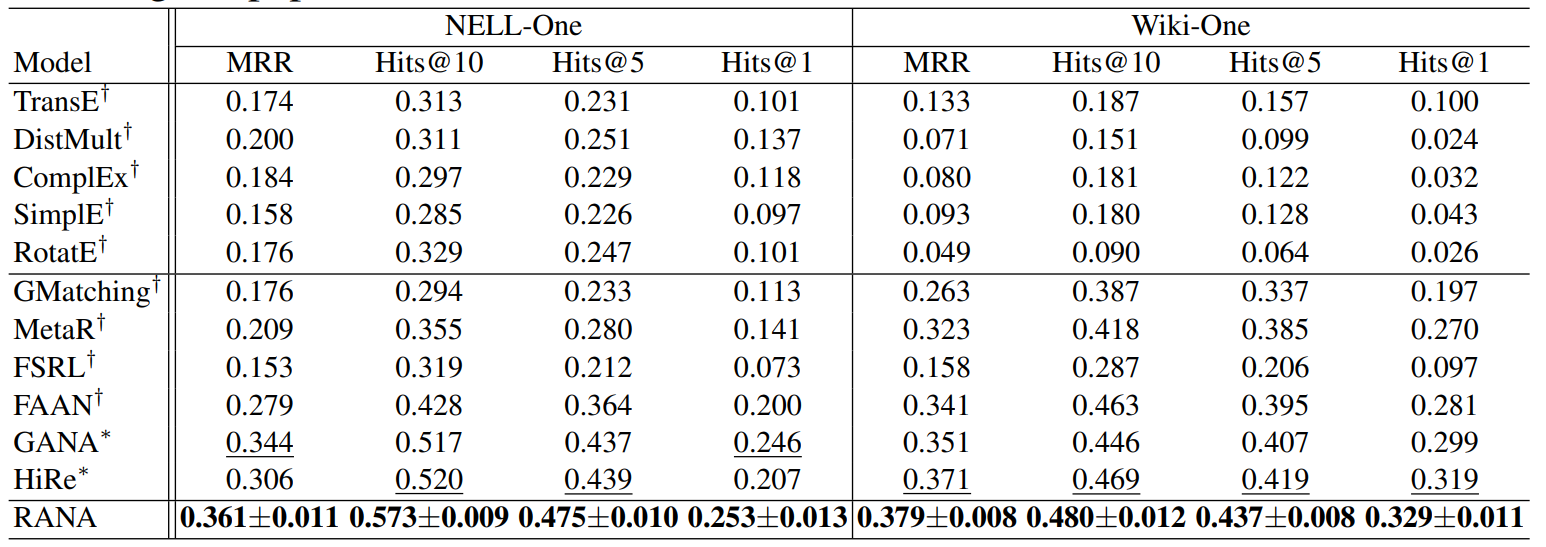
方法:本文提出了一种关系感知网络,结合基于注意力的损失函数,用于Few-Shot知识图谱补全任务。研究内容包括三元组表示、负采样策略和元学习方法。通过选择多个负样本,并使用注意力机制区分每个负样本的重要性,提高了模型的性能。
创新点:
-
通过选择多个负样本并提出了注意力损失来区分每个负样本的重要性。这种关注样本选择和注意力损失的方法在FKGC任务中取得了比其他方法更好的表现。
-
设计了一个动态关系感知实体编码器来学习上下文相关的实体表示。实验结果表明,这种动态关系感知实体编码器在两个基准数据集上优于其他SOTA基线模型。
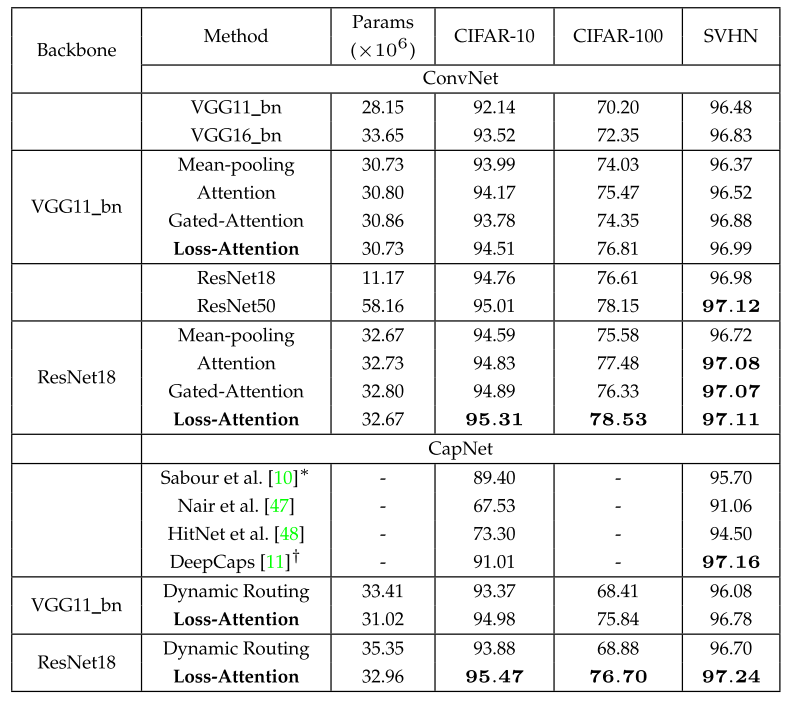
Loss-Based Attention for Interpreting Image-Level Prediction of Convolutional Neural Networks
方法:论文提出了一种新的通用注意机制,称为基于损失的注意力,通过利用相同的参数来学习图块权重和逻辑(类向量)以及图像预测,从而将注意机制与损失函数相连接,以提高图块精度和召回率。通过修改当前流行的卷积神经网络,作者设计了两种深度架构,分别是卷积架构和胶囊架构,用于挖掘图像中的显著图块,从而解释哪些部分决定了图像的决策。
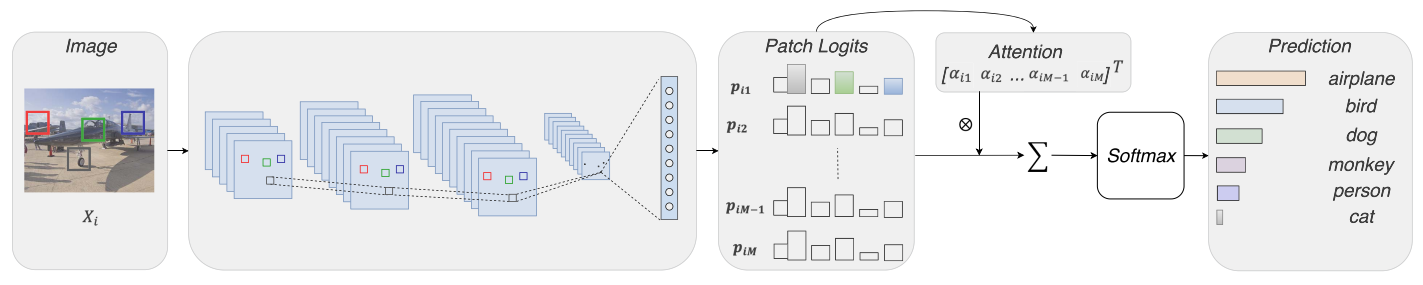
创新点:
-
提出了一种新的注意力机制,称为Loss-Attention机制。该机制利用相同的参数学习补丁权重和标签,从而将注意力机制与损失函数相连接。这种机制可以挖掘显著的补丁,并通过新的损失函数进一步提高其精确度和召回率。
-
通过修改当前流行的卷积神经网络和胶囊网络,提出了两种新的深层架构。这两种架构都保留了图像补丁的空间关系,使图像级决策成为补丁的加权和。
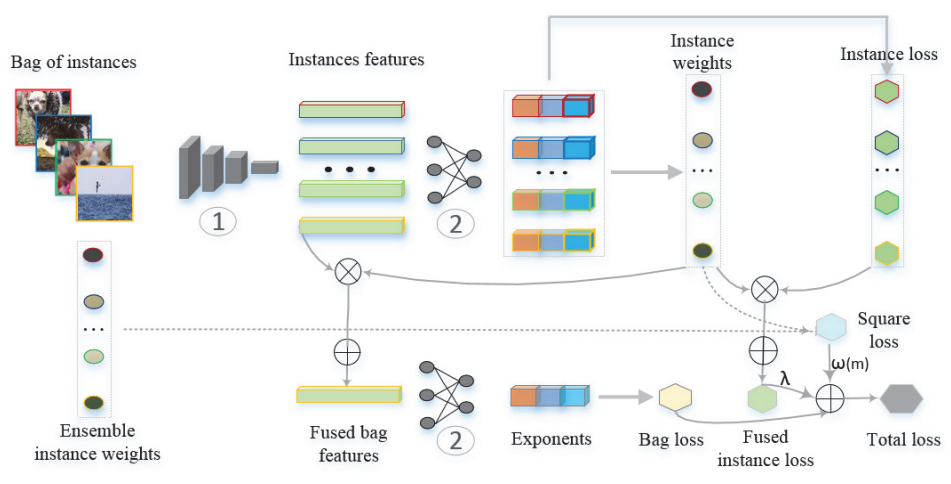
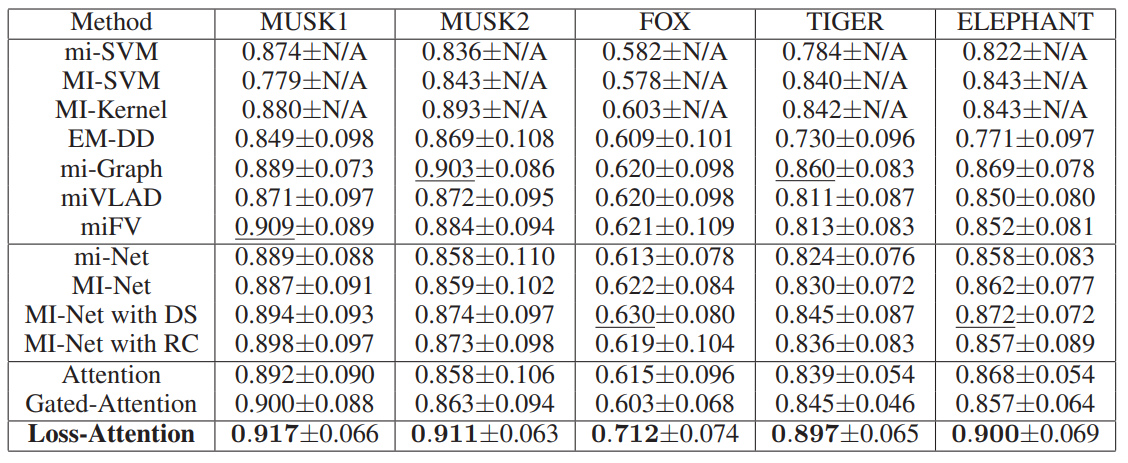
Loss-Based Attention for Deep Multiple Instance Learning
方法:本文提出了一种新颖的基于损失的注意机制,通过将注意机制与softmax和交叉熵损失函数相连接,同时学习实例权重和预测结果,以及深度多实例学习中的包预测。提出的注意机制使用全连接层的参数来学习实例权重,并根据损失函数直接计算实例权重。
创新点:
-
提出了一种新颖的基于损失的注意力机制,用于同时学习实例权重和预测以及包的预测。该注意力机制将注意力机制与softmax和交叉熵损失函数相连接,通过使用全连接层的参数来学习实例权重,并直接基于损失函数计算实例权重。
-
引入了一个由学习的权重和交叉熵函数组成的正则化项,以进一步提高实例的召回率,并引入了一致性成本来平滑神经网络的训练过程。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“损失注意力”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









