









李沐大神前阵子在上交大的演讲大家关注了没,听完确实认同多模态才是当下的一个趋势。特别是为了应对任务复杂性、数据标注难题等方面的需求,当前我们对多模态预训练的研究热情已经空前高涨。
多模态预训练是一种简单高效的方法,它可以通过同时处理多种类型的数据,全面提高模型的表征、泛化等各项能力,也不需要我们大量标注数据,因此无论是在学术界还是工业界,都是香饽饽。
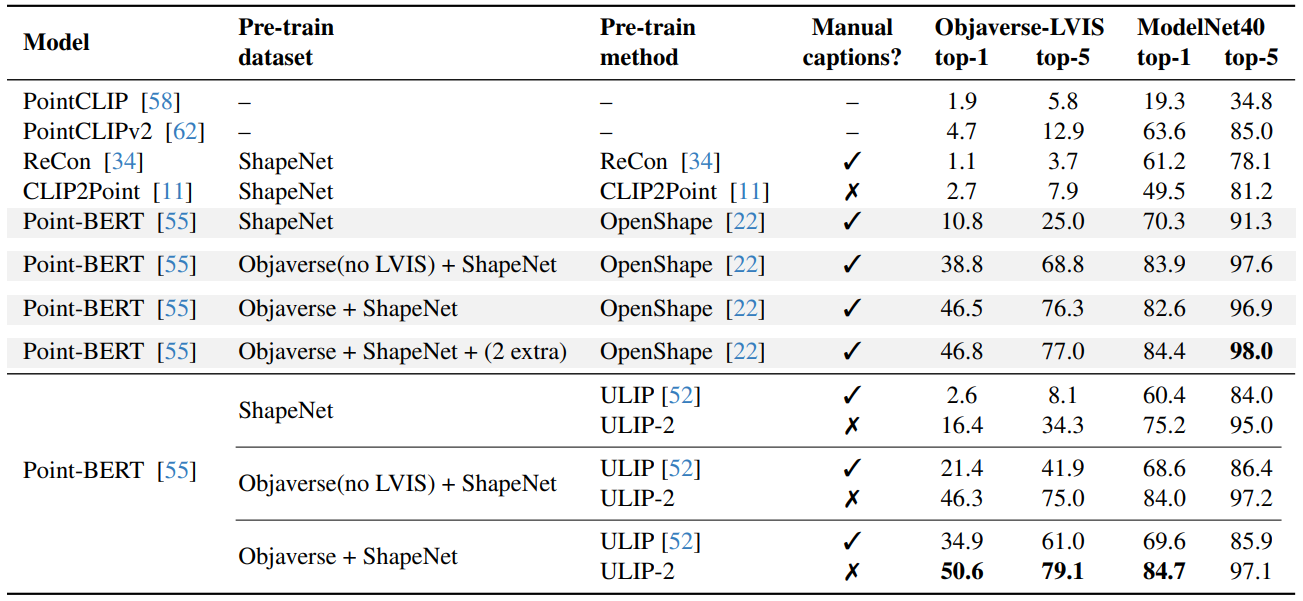
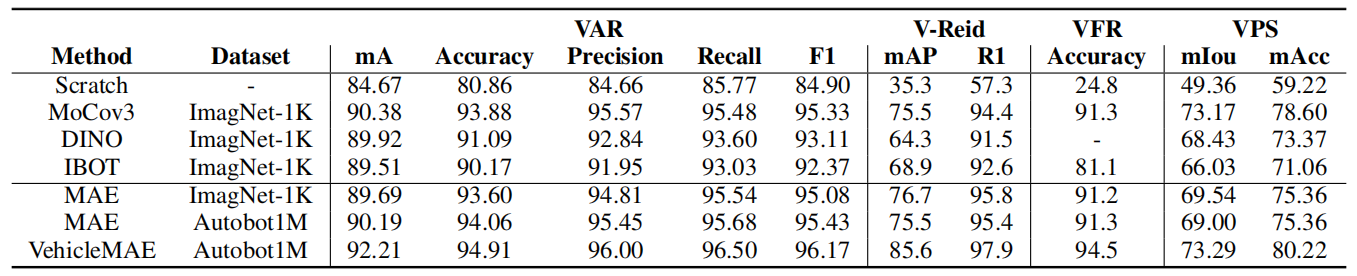
最近这方向一些阶段性的结果已经在各大顶会发表了,比如CVPR 2024的ULIP-2框架,无需标注数据即可刷新SOTA;还有AAAI 2024的VehicleMAE框架,各方面都显著优于其他预训练模型。
如果有同学想发表相关论文冲冲顶会,我这边整理好了10篇最新的多模态预训练论文以供参考,全部都有开源代码,希望能帮大家加快点进度。
论文原文+开源代码需要的同学看文末
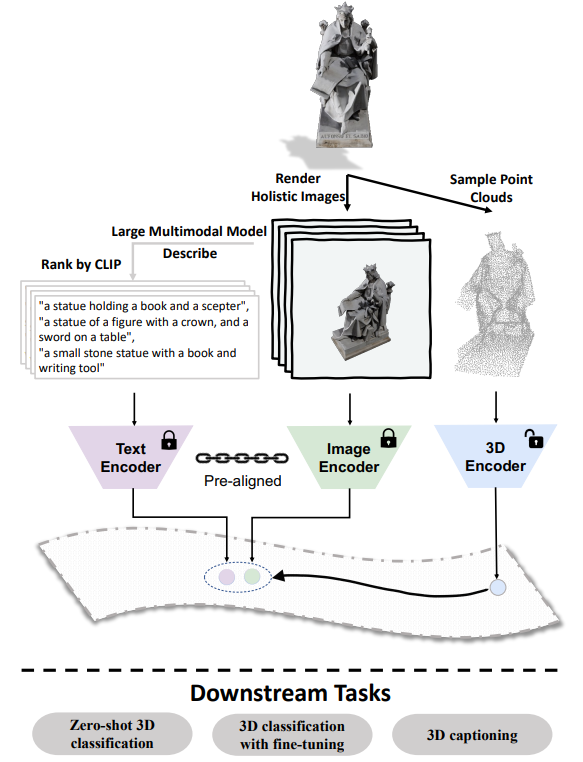
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
方法:论文提出了一个名为ULIP-2的新型三模态预训练框架,该框架利用大规模多模态模型自动生成3D形状的全面语言描述。这种预训练方法只需要3D数据作为输入,从而消除了手动3D注释的需求,因此可以扩展到大型数据集。
创新点:
-
通过使用更强大的图像和文本编码器,以及扩大模型规模,ULIP-2在多模态3D预训练中实现了更广义的学习。这种扩大规模的方法在零样本分类任务中取得了显著的改进,并且在模型的可扩展性和质量方面解决了现有数据集的挑战。
-
ULIP-2使用生成的描述来提升性能,并与之前所用的手动描述进行了比较。实验证明,使用生成的描述在零样本分类任务中取得了显著的改进。
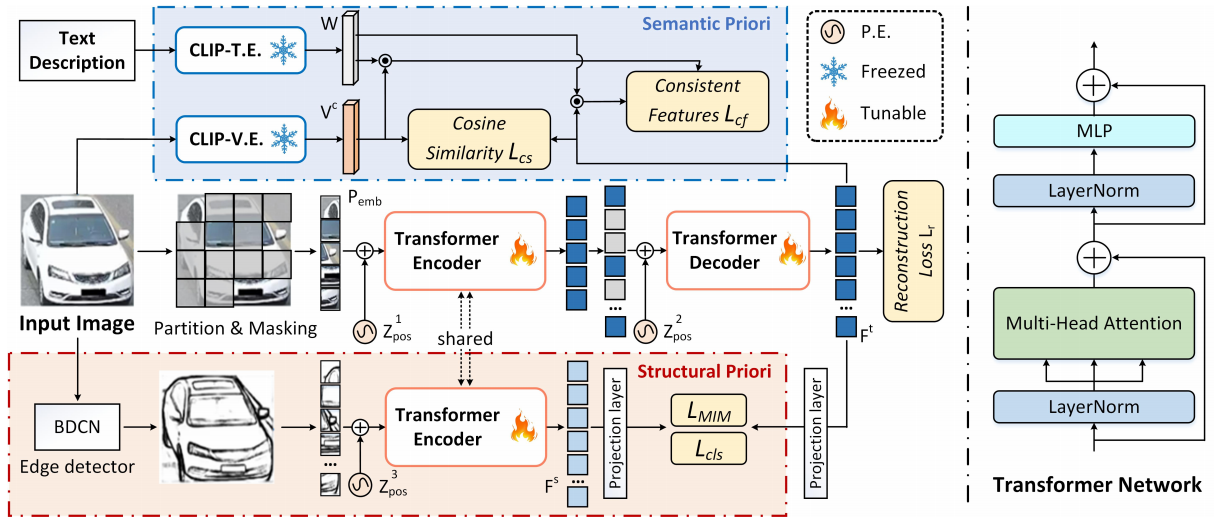
Structural Information Guided Multimodal Pre-training for Vehicle-Centric Perception
方法:文章讲述的是一种多模态预训练框架,名为VehicleMAE,专为车辆感知任务设计。这个框架结合了车辆的视觉结构信息(如车辆轮廓线条)和语义信息(来自车辆的自然语言描述),以提高模型对车辆外观的理解和重建能力。
创新点:
-
提出了车辆中心预训练框架VehicleMAE,该框架引入了结构轮廓信息和高层语义先验,以实现更准确的掩码标记重建。
-
引入了结构先验来指导给定车辆图像的重建,在四个下游任务上的性能都有所提升,如车辆属性识别的结果提升到了91.27%、94.11%、95.29%、95.82%、95.50%。
CIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling
方法:论文提出了一种多模态预训练框架,名为CIRP,用于产品捆绑的项表示学习。CIRP框架旨在通过结合商品的图像和文本表示来捕捉单个商品的语义信息,同时利用跨商品关系来增强模型的性能。

创新点:
-
提出了一种新颖的框架CIRP,它结合了单项跨模态对比损失(ITC)和跨项对比损失(CIC),以将跨项关系整合到多模态预训练模型中。
-
为了减少关系中的噪声并降低训练成本,作者设计了一种关系修剪方法,以增强和加速预训练。
-
通过定量研究表示学习分析来解释他们的方法的工作机制,结果表明他们的方法能够更好地捕捉同一捆绑内的物品之间的关系。
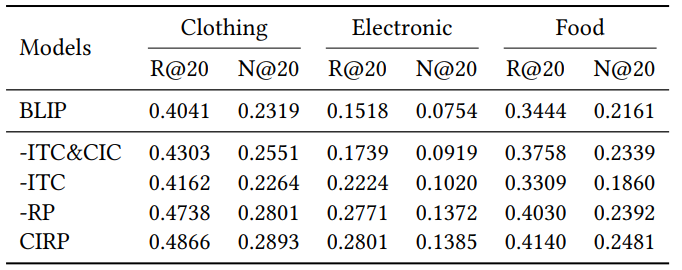
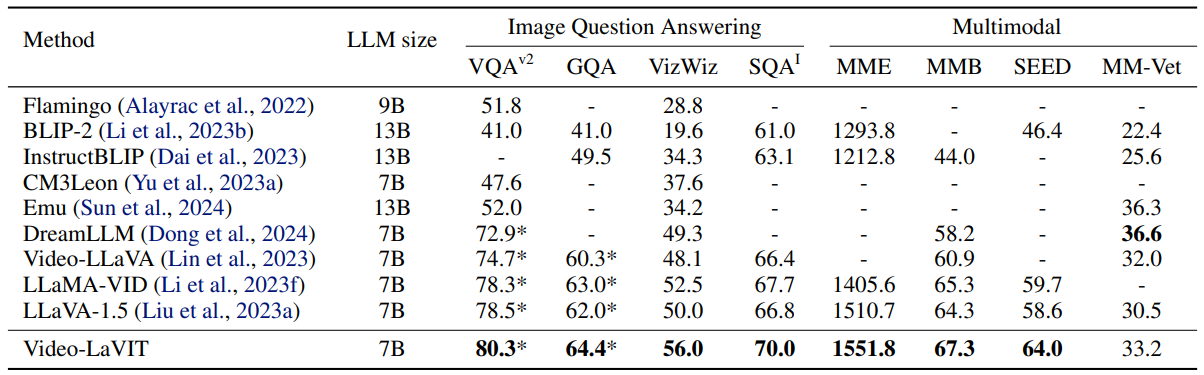
Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization
方法:论文提出了一个多模态预训练方法,名为Video-LaVIT,该方法通过视频分解方案有效地对时间信息进行建模,并将图像和文本知识与视频结合起来进行统一的生成预训练,实现了对视频、图像和语言的综合理解和生成能力。
创新点;
-
通过Video-LaVIT,作者提出了一种有效的视频预训练框架,利用大型语言模型(LLMs)的出色建模能力来促进对视频模态的学习。
-
设计了视频分词器和视频去分词器这两个核心组件,分别用于将视频表示为离散的记号序列,并将生成的离散记号映射回连续的像素空间。
-
Video-LaVIT通过统一的自回归训练范式进行优化,从而能够同时理解和生成各种多模态内容。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“多模态预训练”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









