







- 背景
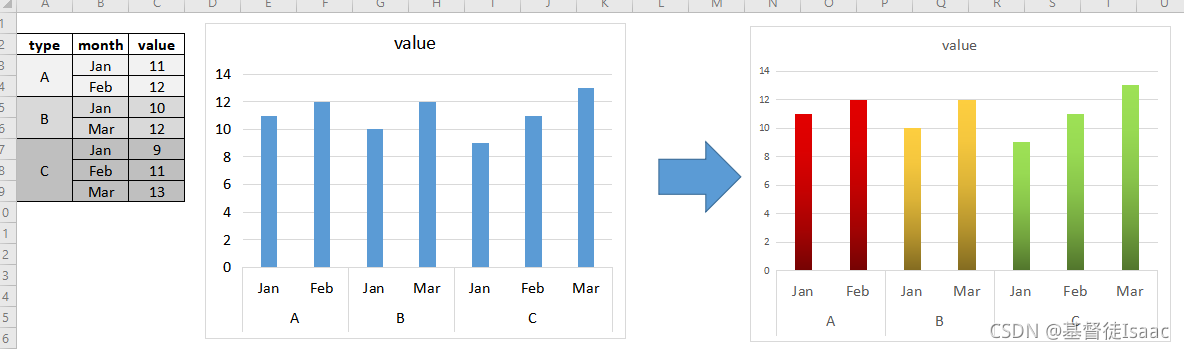
Excel中无法实现分组区分颜色。
右边的图是我手动点击各个柱形修改分组颜色的。
请问如何在R和Excel中分别实现右图?
- 更新后完整解决方案:
# 数据载入 --------------------------------------------------------------------
# 处理合并单元格:
# openxlsx::read.xlsx(fillMergedCells = TRUE)
# 处理拆散单元格(向下填充缺失值):
# tidyr::fill(type, .direction = “down”)
library(tidyverse)
a <- readxl::read_excel("E:/histgram_filled_by_groups.xlsx",
sheet = "Sheet4",
col_names = TRUE)
a <- a %>% tidyr::fill(type, .direction = "down")
# 数据整理 --------------------------------------------------------------------
a <- a %>% mutate(num = 1:nrow(a)) %>% # 新创建一个有序变量,用于给新变量排序
unite(col = type_month,
c(type, month),
sep = "_",
remove = FALSE) # 合并为新变量,mutate(paste)、unite均可以
a %>% glimpse() %>% anyNA()
# 三种排序错误:
# ①:num作为字符融合为num_type_month,造成十位数跑到个位数前面
# ②:num没有因子化,默认识别为连续变量导致覆盖标签时个数不一致
# ③:aes修改坐标系,type_month没有因子化,导致按照字母顺序排序
# 对应解答:
# ①:要用独立的num作为自变量
# ②:使用factor对其离散化处理
# ③:aes(x = type_month %>% factor(levels = c(type_month)))
# 累积柱状图,不需要对type、month融合,根据其中一个作为横坐标即可
# 绘图方法一 ---------------------------------------------------------------------
# 方法一参考文献:https://www.delftstack.com/zh/howto/r/ggplot-axis-tick-labels-in-r/
# scale_x_discrete(标题,breaks,labels)离散变量,要求先将变量转化为因子/离散数据
# scale_x_continuous连续变量
p1 <- a %>%
ggplot(mapping =
aes(x = num %>% factor(), # num转化为因子变量,横坐标变为离散数据
y = value,
col = type,
fill = type, # 为geom_col
group = type)) + # 为geom_line
scale_x_discrete("type_month",
labels = a$type_month) # 用融合后的字符向量覆盖原刻度标签
gridExtra::grid.arrange(
p1 + geom_col(),
p1 + geom_line() + geom_point(),
nrow = 2)
# 这种方法最有效,覆盖后的横坐标也严格按照num的顺序排序~
# 绘图方法二 ----------------------------------------------------------------------
# 方法二参考文献:https://blog.csdn.net/qq_43209742/article/details/106643870
p2 <- a %>%
ggplot(mapping =
aes(x = num, # 此时factor(num)对结果无效,因为aes会被改变
y = value,
col = type,
fill = type, # 为geom_col
group = type)) + # 为geom_line
aes(x =
type_month %>% factor(
levels = c(type_month))) + # 修改横坐标,只根据新的坐标顺序排列
labs(x = "type_month")
gridExtra::grid.arrange(
p2 + geom_col(width = 0.8),
p2 + geom_line() + geom_point(),
nrow = 2)
-
结果展示

-
致谢
这是一篇从科学和历史证据的角度探讨信仰的文章: https://chinesecreation.files.wordpress.com/2020/12/e6b182e79c9fe6b182e8af81.pdf
- 遇到的问题及解决
问题:横坐标只能画三组,无法组内进行对比
解决:
把两组因子变量融合成一组变量*。然后再用ggplot+geom_col()画图就好啦
更新:
*错误:创建一个1:n的序列,作为变量名的开头,会导致十位数跑到2、3、4等个位数的前面,所以不能这么做!!
R语言中对字符型数据有默认的排序方法,所以一般采用行列索引进行循环。如果要直接对字符型数据进行排序,需要按照对应的排序规则调用相关函数。
一般都是提取字符串中的数字,再按照数字进行排序。
解决方法:mutate创建了一个数字向量作为横坐标,然后再用原始数据paste成新字符向量作为横坐标标签覆盖上去。
例如:
mutate(num = 1:nrow(data), v1_v2 = paste…)
mutate(num = 1:nrow(data)); unite(v1_v2, c( v1,v2 ))
问题:将字符向量转化为因子向量
解决:检查格式,自定义factor函数的水平levels
问题:geom_histogram错误:stat_bin() can only have an x or y aesthetic.
解决:直方图(geom_histogram)与柱形图有区别。
柱状图有geom_bar() 和 geom_col():
geom_bar() 经过统计变换(count, …prop…);
geom_col()不经过统计变换,代表的就是该分类变量的实际值。
geom_histogram()等同于geom_bar()+stat_bin()。https://www.jianshu.com/p/57ec06c83fba
参考资料:https://www.jianshu.com/p/05391806ab80
有两种类型的条形图:geom_bar()和geom_col()。
geom_bar()使条的高度与每组中的案例数成正比(或者,如果weight提供美观,则为权重的总和)。
如果您希望条形的高度代表数据中的值,请geom_col()改用。
geom_col需要分类变量x和数值y
geom_bar只需要x,y轴自动映射prob = table[i,j]
https://zhuanlan.zhihu.com/p/101917540
问题:处理合并单元格和缺失值
解决:
处理合并单元格:
openxlsx::read.xlsx(fillMergedCells = TRUE) # 填充所拆散的合并单元格
处理拆散单元格(向下填充缺失值):
tidyr::fill(type, .direction = “down”) # 向下填充
-
其他
请问有人知道如何在Excel中实现吗? -
应用案例,绘制不同缺陷四至十月产生的报废重量的柱状图
# 数据载入 ----------------------------------------------------------------------
library(tidyverse)
item <- readxl::read_excel("E:/histgram_filled_by_groups.xlsx",
sheet = "Sheet3")
names(item) <- c("type", "month", "weight")
item <- item %>% tidyr::fill(type, .direction = "down")
item %>% .$type %>% table("type" = .) %>% knitr::kable() # 查看填充后频数表 #
# 数据整理 --------------------------------------------------------------------
item <- item %>%
mutate(num = 1:nrow(item),
type_month = paste(item$type,
item$month,
sep = "_")) # mutate(paste)、unite均可以
item %>% glimpse() %>% anyNA()
# 画图 ----------------------------------------------------------------------
p <- item %>%
ggplot(mapping =
aes(x = num %>% factor(),
y = weight,
col = type,
fill = type,
group = type)) +
scale_x_discrete(labels = item$type_month) +
theme(axis.text.x =
element_text(angle = 90, hjust = 1)) + # 竖排 #
labs(x = "各缺陷四至十月趋势",
y = "每月累计重量(吨)")
gridExtra::grid.arrange(
p + geom_col(width = 0.8),
p + geom_line() + geom_point(),
nrow = 2)
- 案例2:绘制跨年度产量折线图
library(tidyverse)
library(openxlsx)
a <- read.xlsx("e:cross.xlsx",
fillMergedCells = TRUE)
a <- a %>% mutate(num = 1:nrow(a)) %>%
mutate(year = year %>% factor()) # year转化为因子变量,横坐标变为离散数据
a %>%
ggplot(mapping =
aes(x = num %>% factor(), # num转化为因子变量
y = weight,
col = year,
group = year)) + # 为geom_line
scale_x_discrete(labels = a$month) +
geom_line() + geom_point() +
ggtitle("2#横剪2020-2021每月产量趋势") +
labs(x = "月份",
y = "产量")
- 其他补充:
# 查看填充后频数表 #
item %>% .$type %>% table("type" = .) %>% knitr::kable()
# 竖排刻度标签 #
p + theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
模板:
library(tidyverse)
library(openxlsx)
# 载入 openxlsx::read.xlsx; readxl::read_excel + tidyr::fill
a <- read.xlsx("e:cross.xlsx",
fillMergedCells = TRUE)
# aes
ggplot(a, aes(x = factor(1:nrow(a)),
y = weight,
col = year,
group = year)) +
# geom
geom_line() + geom_point() +
# scale_x_discrete(labels)
scale_x_discrete(labels = a$month)
# ggtitle; labs; ...
## 如果将两组连成一条线,请设置group = factor(1)
library(tidyverse)
library(openxlsx)
# 载入 openxlsx::read.xlsx; readxl::read_excel + tidyr::fill
a <- read.xlsx("e:cross.xlsx",
fillMergedCells = TRUE)
# aes
ggplot(a, aes(x = factor(1:nrow(a)),
y = weight,
col = year,
group = 1)) +
# geom
geom_line() + geom_point() +
# scale_x_discrete(labels)
scale_x_discrete(labels = a$month)
# ggtitle; labs; ...















 1018
1018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









