







基本概念
- 决策树又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶节点代表某个类或类的分布。
- 决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。
决策树的学习过程
- 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
- 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
- 剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
(1)数据如何分割
分裂属性的数据类型分为离散型和连续性两种情况,对于离散型的数据,按照属性值进行分裂,每个属性值对应一个分裂节点;对于连续性属性,一般性的做法是对数据按照该属性进行排序,再将数据分成若干区间,如[0,10]、[10,20]、[20,30]…,一个区间对应一个节点,若数据的属性值落入某一区间则该数据就属于其对应的节点。
(2)如何选择分裂的属性
- 决策树采用贪婪思想进行分裂,即选择可以得到最优分裂结果的属性进行分裂。选择分裂属性是要找出能够使所有孩子节点数据最纯的属性,决策树使用信息增益或者信息增益率作为选择属性的依据。
-
用信息增益表示分裂前后根的数据复杂度和分裂节点数据复杂度的变化值,计算公式表示为:
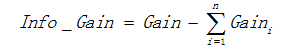
其中Gain表示节点的复杂度,Gain越高,说明复杂度越高。信息增益说白了就是分裂前的数据复杂度减去孩子节点的数据复杂度的和,信息增益越大,分裂后的复杂度减小得越多,分类的效果越明显。
节点的复杂度可以用以下两种不同的计算方式:
a)熵
熵描述了数据的混乱程度,熵越大,混乱程度越高,也就是纯度越低;反之,熵越小,混乱程度越低,纯度越高。 熵的计算公式如下所示:
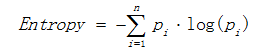
其中Pi表示类i的数量占比。以二分类问题为例,如果两类的数量相同,此时分类节点的纯度最低,熵等于1;如果节点的数据属于同一类时,此时节点的纯度最高,熵 等于0。
b)基尼值
基尼值计算公式如下:
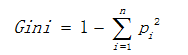
其中Pi表示类i的数量占比。其同样以上述熵的二分类例子为例,当两类数量相等时,基尼值等 于0.5 ;当节点数据属于同一类时,基尼值等于0 。基尼值越大,数据越不纯。 -
使用信息增益作为选择分裂的条件有一个不可避免的缺点:倾向选择分支比较多的属性进行分裂。为了解决这个问题,引入了信息增益率这个概念。信息增益率是在信息增益的基础上除以分裂节点数据量的信息增益,其计算公式如下:
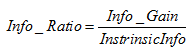
表示分裂子节点数据量的信息增益
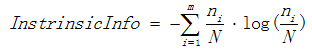
其中m表示子节点的数量,表示第ni个子节点的数据量,N表示父节点数据量,说白了, 其实是分裂节点的熵,如果节点的数据链越接近,该值越大;如果子节点越大,该值越大,信息增益率而就会越小,能够降低节点分裂时选择子节点多的分裂属性的倾向性。信息增益率越高,说明分裂的效果越好。
-
(3)什么时候停止分裂
- 决策树不可能不限制地生长,总有停止分裂的时候,最极端的情况是当节点分裂到只剩下一个数据点时自动结束分裂,但这种情况下树过于复杂,而且预测的经度不高。一般情况下为了降低决策树复杂度和提高预测的经度,会适当提前终止节点的分裂。
以下是决策树节点停止分裂的一般性条件:
(1)最小节点数
当节点的数据量小于一个指定的数量时,不继续分裂。两个原因:一是数据量较少时,再做分裂容易强化噪声数据的作用;二是降低树生长的复杂性。提前结束分裂一定程度上有利于降低过拟合的影响。
(2)熵或者基尼值小于阀值。
由上述可知,熵和基尼值的大小表示数据的复杂程度,当熵或者基尼值过小时,表示数据的纯度比较大,如果熵或者基尼值小于一定程度数,节点停止分裂。
(3)决策树的深度达到指定的条件
节点的深度可以理解为节点与决策树跟节点的距离,如根节点的子节点的深度为1,因为这些节点与跟节点的距离为1,子节点的深度要比父节点的深度大1。决策树的深度是所有叶子节点的最大深度,当深度到达指定的上限大小时,停止分裂。
(4)所有特征已经使用完毕,不能继续进行分裂。
被动式停止分裂的条件,当已经没有可分的属性时,直接将当前节点设置为叶子节点。
(4)决策树的构建方法
-
根据决策树的输出结果,决策树可以分为分类树和回归树,分类树输出的结果为具体的类别,而回归树输出的结果为一个确定的数值。
-
决策树的构建算法主要有ID3、C4.5、CART三种,其中ID3和C4.5是分类树,CART是分类回归树,其中ID3是决策树最基本的构建算法,而C4.5和CART是在ID3的基础上进行优化的算法。
决策树的学习的其他问题
剪枝策略
- 预剪枝
- 后剪枝
连续值和缺失值的处理
- 连续值离散化
- 缺失值处理
常见决策树算法(ID3、C4.5、CART)
原理及代码实现:https://shuwoom.com/?p=1452
原理分析:https://blog.csdn.net/choven_meng/article/details/82878018















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









