







文章目录
背景
LLM训练有3D并行的需求(alpa将数据并行视为张量并行,即张量沿batch切分)
- 算子间并行的通信成本小,但会引入数据依赖性,产生bubble,流水线仅可以缓解
- 算子内并行性无bubble,但通信成本更高
- 由于节点内外通信带宽不同,需根据异构网络拓扑将划分结果映射到 GPU 设备
alpa
TPU 集群上仅使用JAX的算子内并行即可,但在GPU集群,JAX 没有提供流水线并行
Alpa 的关键 API 是@alpa.parallelize装饰器,可以自动并行化和优化最佳模型并行策略。JAX 具有已知大小和形状的静态图,对样本批次的训练进行跟踪即可捕获自动划分和并行化所需的所有信息。
简介
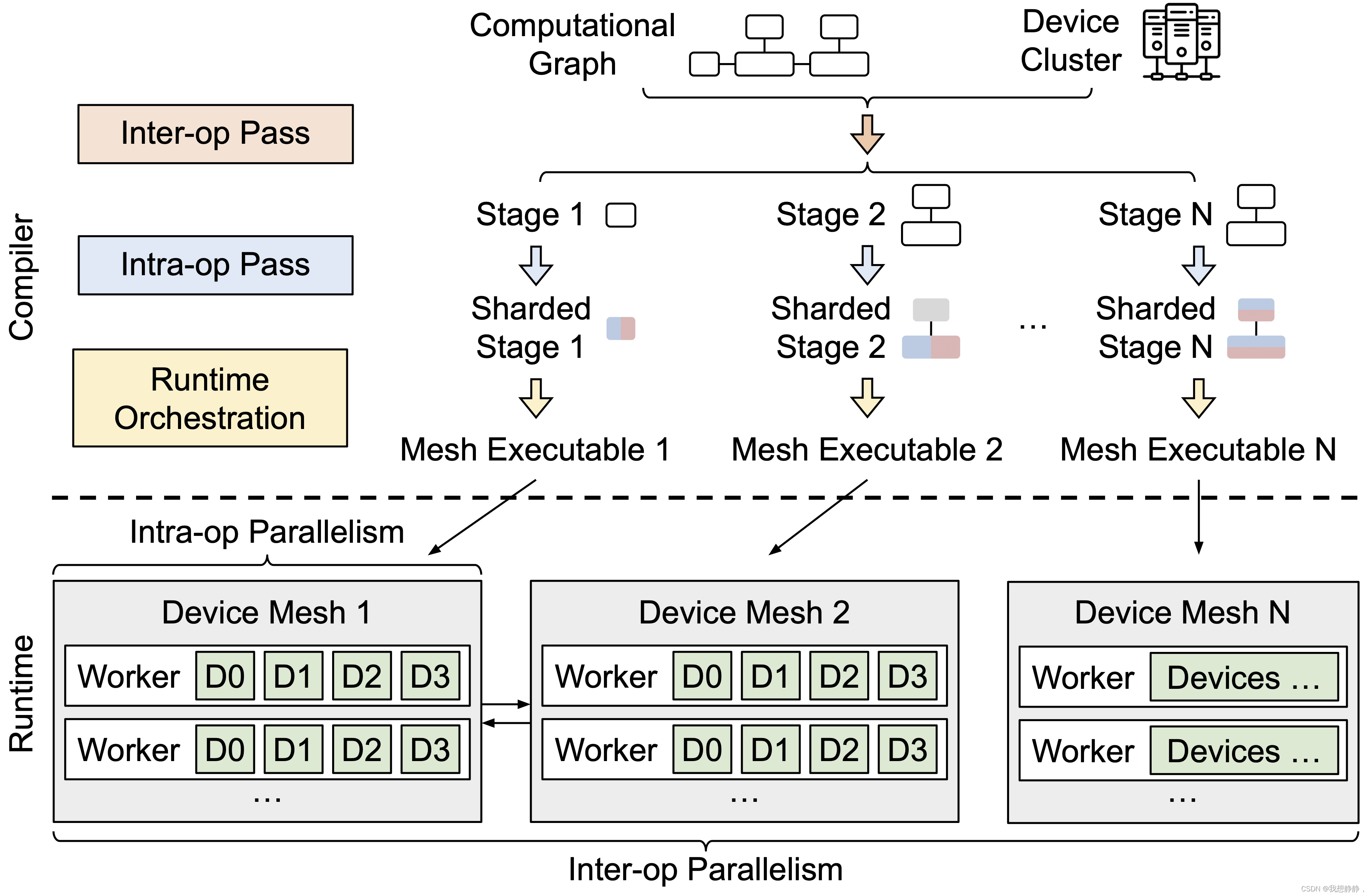
在编译步骤中,Alpa采用计算图形式的模型描述和设备集群作为输入,并执行一些编译和优化以生成模型并行执行计划,该计划是为模型和集群定制的。
然后,Alpa根据训练代码和并行执行计划为集群中的每个参与计算设备生成二进制可执行文件。
在运行时步骤中,Alpa编排这些可执行文件在集群上的并行执行。
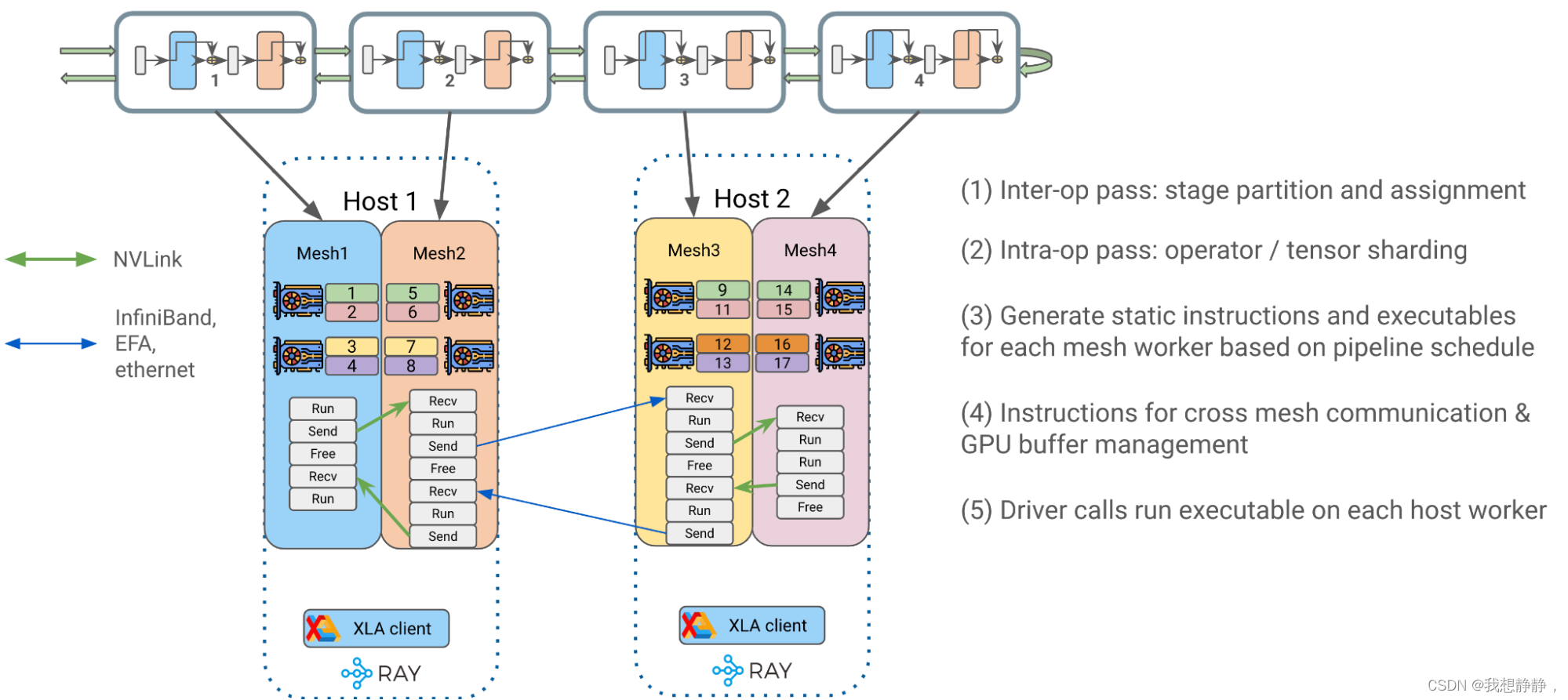
DeviceMesh
Alpa 利用 Ray Actors 创建更高级的设备管理抽象,例如 DeviceMesh:GPU 设备的二维网格Mesh。一个Mesh可以跨越多个物理主机;多个网格可以驻留在同一台主机上;一个网格可以包含整个主机。
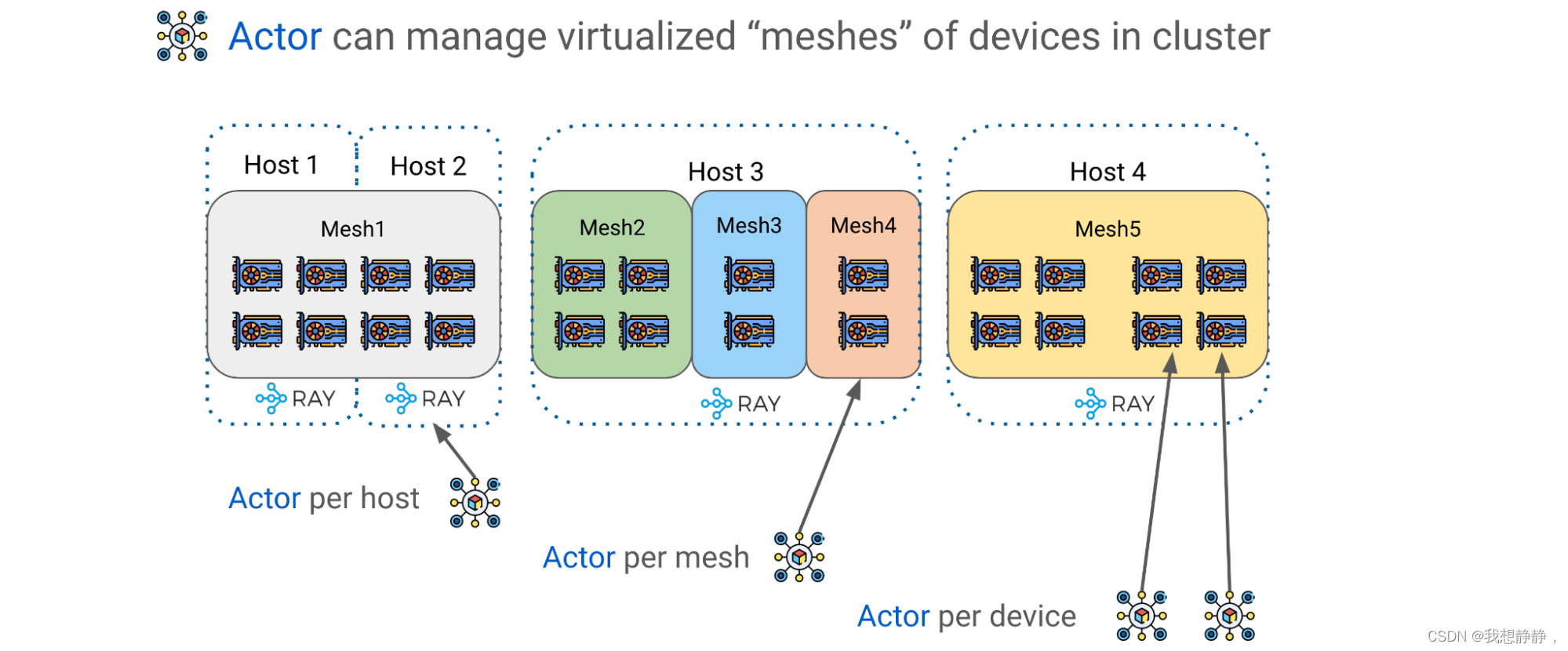
Ray Actors 为管理集群内的 GPU 设备提供了极大的灵活性。 可以选择每个主机一个Actor,每个网格一个Actor,甚至每个设备一个Actor
算子间并行会将集群切分为多个设备组。每个组可能包含许多具有高通信带宽的设备,例如NVIDIA NVLink。我们将每组设备称为DeviceMeshes
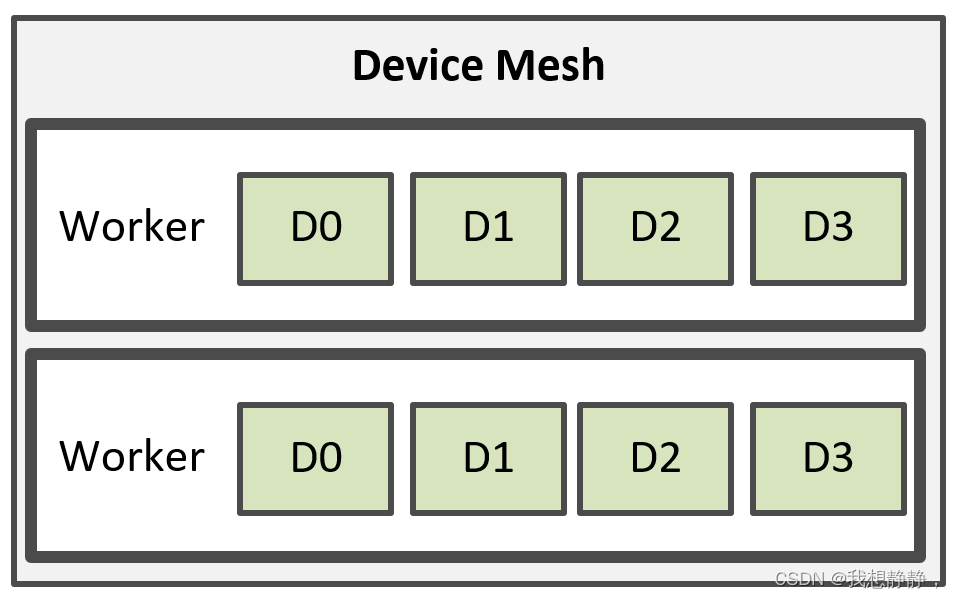
worker即Ray actors。每个DeviceMesh可能包含来自单个节点或多个节点的部分或完整设备。Alpa 使用一个 worker 从一个节点管理多个设备;因此,一个DeviceMesh可能包含多个worker,每个worker映射到一个进程,该进程管理一个节点上的多个设备。
跨 DeviceMeshes 的 GPU Buffer管理
在GPU计算过程中,我们经常使用GPU张量来表示更大矩阵的块。Alpa有一个应用级GPU Buffer管理系统,为每个GPU Buffer分配一个UUID,并提供基本的原语,如Send/Recv/Delete,以实现跨DeviceMeshes 张量移动和生命周期管理。
使用Ray Actors和DeviceMesh抽象,可以通过在主机上调用相应的方法来管理和传输缓冲区,以方便高级模型训练范例。
Ray Collective
它是一组通信原语,可实现跨不同 CPU、GPU 和 DeviceMesh 的高效灵活的张量移动。它是pipeline并行的重要通信层。
Pipeline parallelism runtime orchestration
在JAX和Alpa中,计算、通信和指令往往被设计为静态的。静态特性是一个重要的属性,因为在JAX中,用户程序可以被编译为中间表示(IR),然后作为自包含的可执行文件传递给XLA。用户可以将输入传递给可执行文件,并期望得到输出结果,其中所有的张量在大小和形状上都是已知的。
JAX的函数式特性以及它的较低级别中间表示(IR)与Ray很好地配合。如果我们回顾一下Ray任务,在其中我们装饰一个函数并让它在集群中执行,装饰的函数就是"可执行文件"。在Ray中,可执行文件总是通过序列化装饰的Python函数或包装任意代码的类来生成。
然而,使用JAX时,可执行文件是一个具有清晰数学属性的强大计算单元。通过良好的调度和编排可执行文件,我们可以表示复杂且强大的神经网络,例如transformer和pipeline并行性的训练范式,这是将LLM(语言模型)扩展到GPU集群的基本技术。
下面是编译过程:
- 算子间并行: Alpa 将 transformer 块最佳地拆分为单独的流水线阶段stage,并将它们分配给相应的 DeviceMesh(es)。
- 算子内并行 :接收生成的 <stage, mesh> 对,并为该阶段生成最佳的 intra-op 并行执行计划以在其分配的网格上运行。Alpa 将运算符输入和输出矩阵与GSPMD(ML计算图的通用和可扩展并行化)一起划分到位于同一主机上的 GPU 设备上。
- 为网格workers生成静态指令:为每个 DeviceMesh 编译一个静态可执行文件,与用户配置相关,例如pipeline调度(1F1B、GPipe)、micro-batch、梯度累积等。
- 每条指令都可以是{RUN、SEND、RECV、FREE},用于处理运行自包含的 JAX HLO/XLA 程序,跨 DeviceMesh 分配/传输/释放 GPU 缓冲区。
- 通过静态指令,我们大大降低了 Ray single controller级别的调度频率和开销,以获得更好的性能和可扩展性。
- 尝试生成关于如何在两个网格之间传递张量的最佳方案。
- 将编译后的可执行文件放入相应的主机 Ray actor 中,供以后调用。
两层流水线并行的静态指令示例
这三个编译过程是在XLA和GSPMD之上实现的。除了分布式执行的编译过程外,XLA和GSPMD还额外执行了一些其他必要的优化以提高单设备执行性能。
运行时
Driver 调用并编排每个host worker上编译的可执行文件,以启动端到端流水线transformer 训练。
https://alpa.ai/architecture/overview.html?highlight=ray#design-and-architecture
https://www.anyscale.com/blog/training-175b-parameter-language-models-at-1000-gpu-scale-with-alpa-and-ray














 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









