







分类效果评估
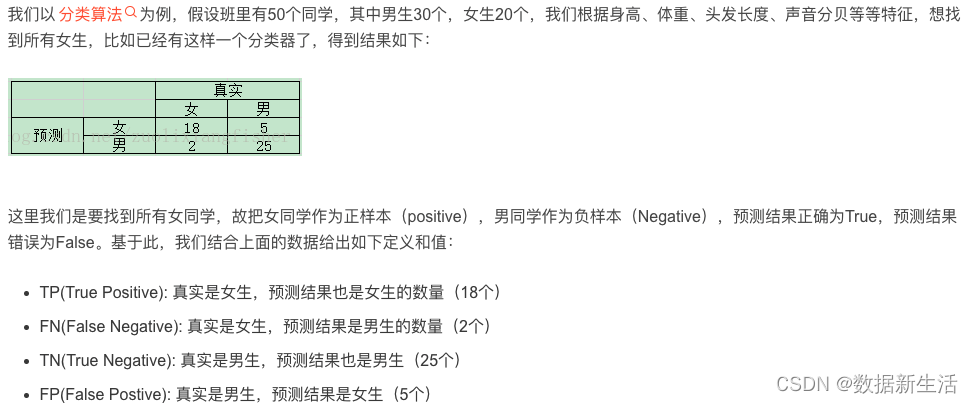
P(Positive)/N(Negative)是针对预测结果而言的.
- 准确率(Accuracy)
A c c u r a c y = T P + T N T P + F P + T N + F N Accuracy=\frac{TP+TN}{TP + FP + TN + FN} Accuracy=TP+FP+TN+FNTP+TN - 精确率(Precision)-查准率,衡量正样本的分类准确性
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP - 召回率(Recall)
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP - F1-Score:精确率和召回率的调和平均
2 F 1 = 1 P r e c i s i o n + 1 R e c a l l \frac{2}{F_1}=\frac{1}{Precision}+\frac{1}{Recall} F12=Precision1+Recall1
ROC、AUC
交叉验证(Cross Validation-CV)

目的:防止模型在训练集上过拟合,导致在测试上表现不好,使用验证集筛选出最优参数。
交叉验证仍需要测试集做最后的模型评估,但不再需要验证集。
最基本的方法被称之为,k-折交叉验证 。 k-折交叉验证将训练集划分为 k 个较小的集合(其他方法会在下面描述,主要原则基本相同)。 每一个 k 折都会遵循下面的过程:
- 将 k-1 份训练集子集作为 training data (训练集)训练模型,
- 将剩余的 1 份训练集子集用于模型验证(也就是把它当做一个测试集来计算模型的性能指标,例如准确率)。
模型
- HistGradientBoostingRegressor
- LightGBM
数据预处理
归一化(离差标准化)
x* = (x-min)/(max-min), x* ∈ \in ∈(0,1), 适用于数据集中,缺点——受异常影响大,实际应用中会取经验max/min
零-均值规范化(z-score标准化)
x* = (x− μ \mu μ)/ σ \sigma σ x* ∈ \in ∈[-1,1]
分类算法
- predict vs predict_proba:
model.predict(X_test)返回的是一个预测的值,modle.predict_proba(X_test)返回的是对于预测为各个类别的概率
predict_proba返回的是一个 n 行 k 列的数组,n 表示测试集中样本的个数, 第 i 行 j列的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1
特征选择
F-test的方法计算两个随机变量之间的线性相关程度。另一方面,mutual information methods(互信息)能够计算任何种类的统计相关性,但是作为非参数的方法,互信息需要更多的样本来进行准确的估计。Permutation feature importance(置换特征重要性): 通过打乱某列的数据排序,会降低模型预测的准确性,结果数据与现实中不可能观察到。如果模型对该列越依赖,模型的准确性就会下降的越明显,从而挖掘出重要特征。
随机森林
参数
- n_estimators:达到一定程度之后精确度不在上升,越大计算量越大
- criterion: 不纯度的衡量指标,有基尼系数和信息熵两种选择
- max_depth: 树的最大深度,超过最大深度的树枝都会被剪掉
- min_samples_leaf: 一个节点在分枝后的每个子节点都必须包含至少个训练样 本,否则分枝就不会发生
- min_samples_split: 一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生
- max_features: 限制分枝时考虑的特征个数(每棵树随机分配了多少特征;越小,过拟合的可能性就越小,但太小会开始引入欠拟合),超过限制个数的特征都会被舍弃, 默认值为总特征个数开平方取整
- min_impurity_decrease: 限制信息增益的大小,信息增益小于设定数值的分枝不会发生
参考文献:中文文档















 5263
5263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









