







论文:Densely Connected Convolutional Networks
目录
Abstract
研究表明,如果卷积网络在靠近输入和接近输出的层之间包含更短的连接,那么卷积网络可以更深入、更准确、更有效地训练。在本文中,作者引入了DenseNet,它以前馈方式将每一层连接到其他每一层。传统的L层卷积网络有L个连接——每层和后续层之间有一个连接——而本文的网络有L(L+1)/2个直接连接。对于每一层,使用所有前一层的特征映射作为输入,并使用其自身的特征映射作为所有后续层的输入。DenseNets有几个引人注目的优点:它们缓解了梯度消失问题,加强了特征传播,鼓励特征重用,并大大减少了参数的数量。作者在四个高度竞争的目标识别基准任务(CIFAR-10、CIFAR-100、SVHN和ImageNet)上评估了我们提出的架构。DenseNets在大多数情况下获得了最先进的显著改进,同时需要更少的计算来实现高性能。
Introduction
DenseNets
考虑通过卷积网络传递的单个图像x0。该网络由L层组成,每一层都实现了一个非线性变换,其中
可以是Batch Normalization(BN)、rectified linear units (ReLU) 、Pooling、Conv等操作的复合函数。我们把第
层的输出表示为
。
传统的网络在𝑙l层的输出为:
ResNet:传统的卷积前馈网络将第层的输出作为输入连接到第
层,这就产生了如下的层跃迁:
。ResNets添加了一个skip-connection,通过恒等函数绕过非线性转换:
DenseNet:为了进一步改善层之间的信息流,作者提出了一种不同的连接模式:我们引入从任何层到所有后续层的直接连接。
DenseBlock
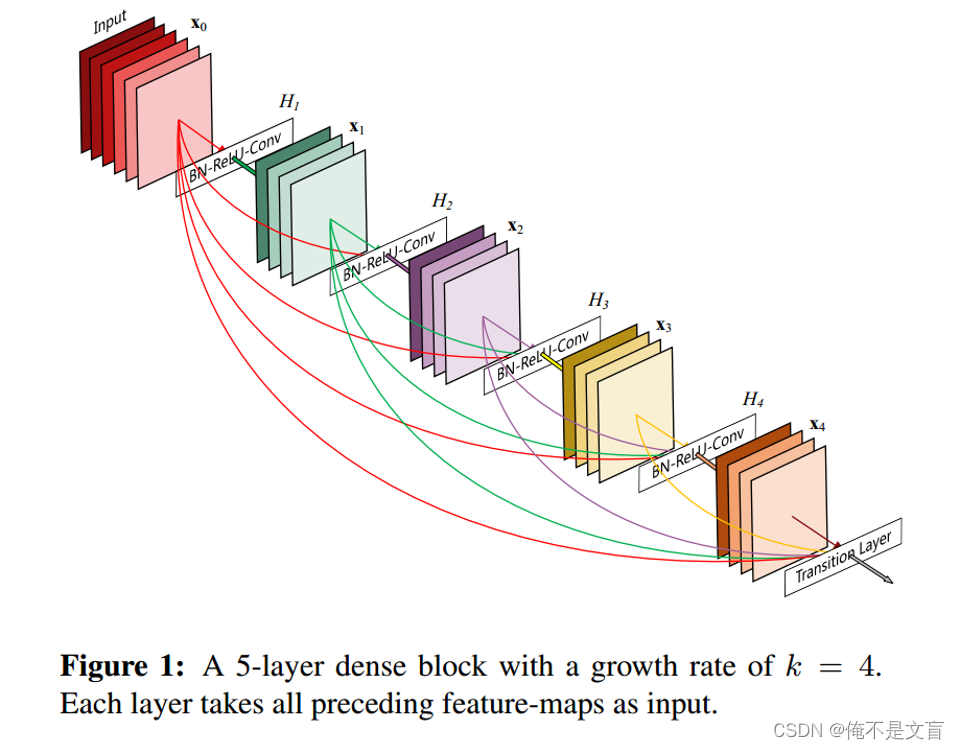
bottleneck

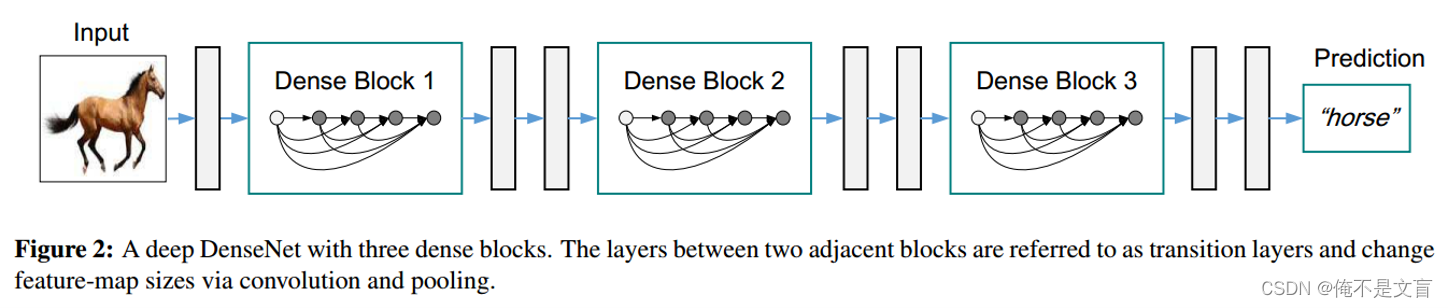
Transition
它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1×1的卷积和2×2的AvgPooling,结构为
Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为,Transition层可以产生
个特征(通过卷积层),其中[0,1]是压缩系数。当
=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,一般使用
=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
Experiments

Table2是DenseNet与其他经典算法在三个数据集(C10,C100,SVHN)上的对比结果。我们可以也很明显的看出DenseNet的算法的错误率远低于其他算法。DenseNet-BC的网络参数和相同深度的DenseNet相比确实减少了很多!在相同深度情况下,DenseNet-BC比DenseNet拥有更小的参数量,且错误率也更低。在SVHN数据集上k24的情况下,DenseNet反而比DenseNet-BC的效果更好,应该是SVHN数据集较为简单导致的。
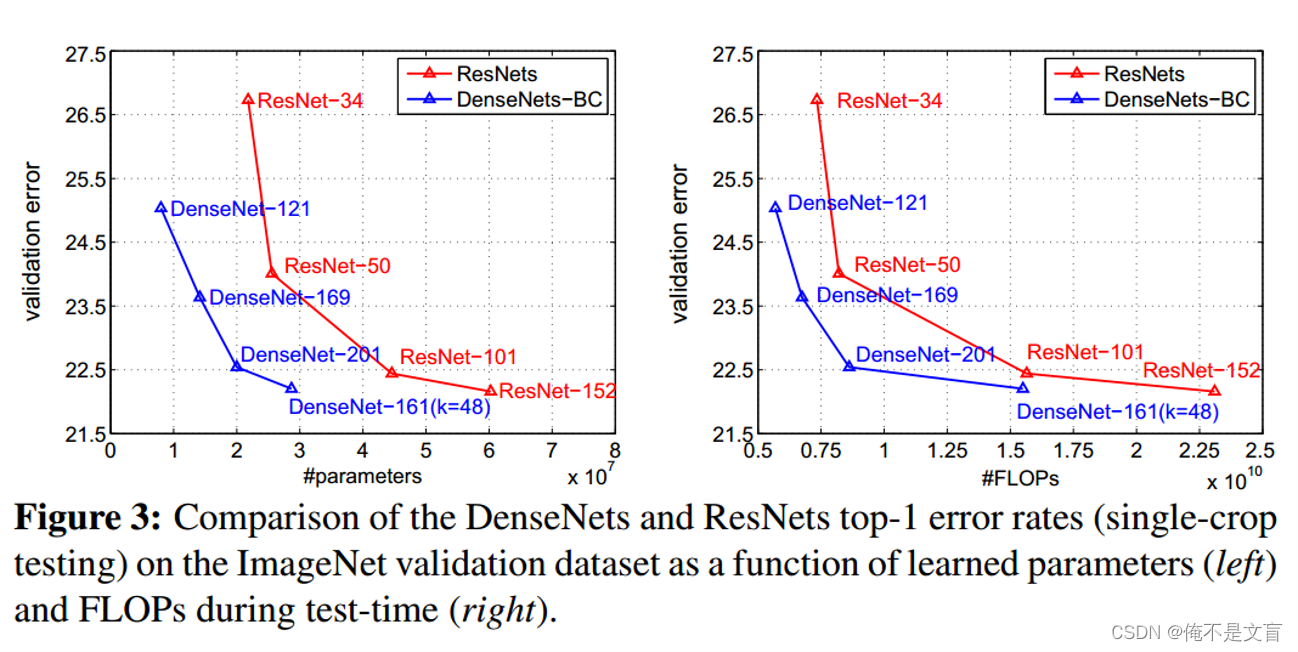
Figure3为DenseNets和ResNets算法在ImageNet数据集上的对比,左图可以明显的看出在参数量相同的情况下,DenseNet的错误率更低,右图可以明显看出在运算量相同的情况下DenseNet的错误率更低。

Figure4的左图是不同类型DenseNet算法在不同参数量的错误率情况,中间图为DenseNet-BC与ResNet相同参数下错误率情况,可以明显看出DenseNet-BC在相同参数下的错误率更低。右图可以看出DenseNet-BC-100在极少的参数就可以达到ResNet01001的效果。
Conclusion
本文作者提出了一种新的卷积网络结构,称之为DensNet,它可以自然扩展到数百层,同时不存在优化困难。有效地解决了深度学习中的一些关键问题,如梯度消失和参数效率,已成为深度学习领域的一个重要里程碑。
DenseNet的优点:
1、省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。对于工业界而言,小模型可以显著地节省带宽,降低存储开销。
2、省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右。
3、抗过拟合。DenseNet 具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。对于 DenseNet 抗过拟合的原因有一个比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。
4、泛化性能更强。如果没有data augmention,CIFAR-100下,ResNet表现下降很多,DenseNet下降不多,说明DenseNet泛化性能更强。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









