









 本文介绍了Ollama作为开源模型仓库的多种应用,包括与Obsidian的集成。作者提到,虽然大模型如Qwen存在响应速度问题,但本地存储的优势在于隐私保护和个性化知识库。未来可能的方向是学习如何结合Streamlit构建自定义模型。
本文介绍了Ollama作为开源模型仓库的多种应用,包括与Obsidian的集成。作者提到,虽然大模型如Qwen存在响应速度问题,但本地存储的优势在于隐私保护和个性化知识库。未来可能的方向是学习如何结合Streamlit构建自定义模型。
Ollma 作为开源模型仓库真的有很多用法,最近看到也可以结合 obsdian 使用,还是很香的。
前期准备
Ollama
Ollama https://ollama.ai
Ollama GitHub 仓库 ollama/ollama: Get up and running with Llama 2, Mistral, Gemma, and other large language models. (github.com)
选择 windows 预览版傻瓜式安装不多赘述,是很好的开源模型库,可以通过 GitHub 查看如何使用,为了方便学习,我摘录如下:
目前已入驻模型
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| 注意下载根据自己的内存来决定,推荐普通电脑用 qwen 1.8 b |
查询已安装的模型
ollama list
运行模型 windows 直接运行软件即可默认开机启动
ollama serve
Obsidian
安装插件 copilot 直接点击安装即可
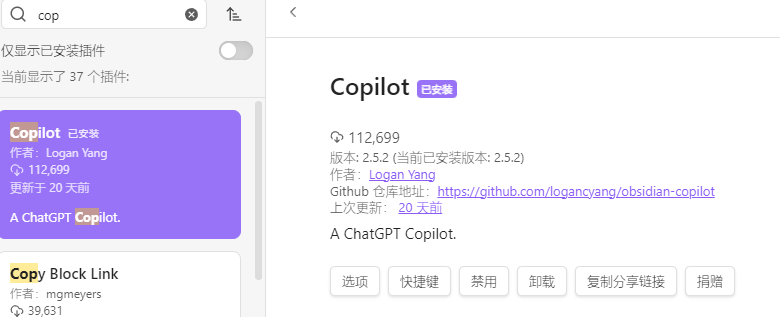
插件设置
Default Model :OLLAMA
Embedding Model : ollama
Ollama Model 这个根据你下载的开源模型来决定,要本地快速响应的话,用 qwen 1.8 b 即可。其他太慢了。
Ollama base url :默认即可,如果你改了,那就用改了的,可以在浏览器试一下,是否正在运行。

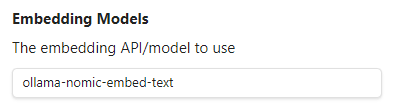
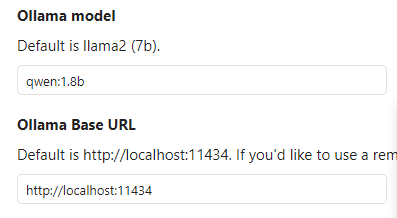
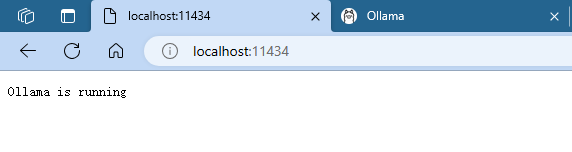
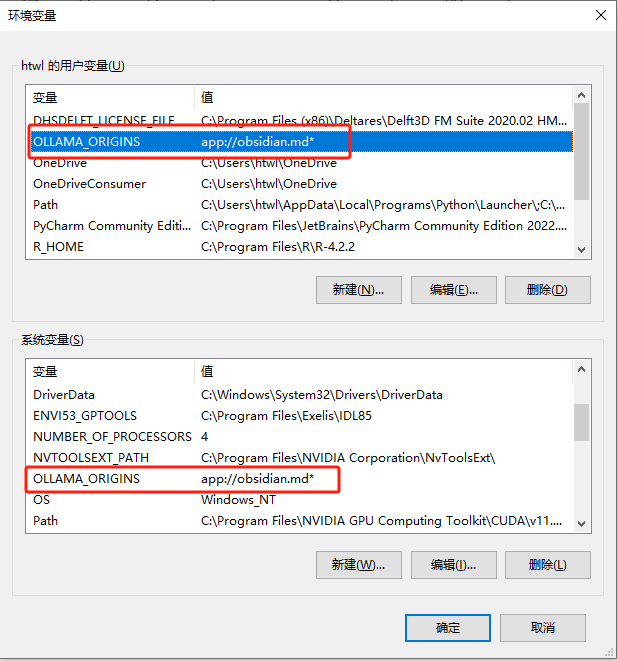
环境变量设置
在插件中有提示,需要添加环境变量。

OLLAMA_ORIGINS=app://obsidian.md ollama serve*
使用方法
以上完成设置后,即可直接使用。
对话方式
- 直接对话

- 用文件对话,其实是内置了 Prompt 组合,会默认英文回答。
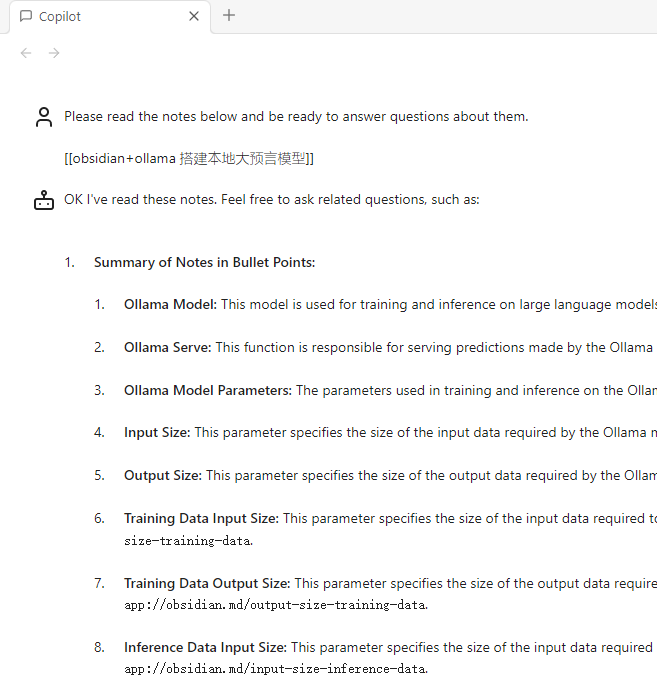
而且也能看到通义千问 1.8 b 版本在处理长文本上能力比较弱,回答会有很多重复内容。
总结
如今大模型泛滥的情况下,本地大开源大模型的优势是个人隐私及配合个人知识库搭建自己的模型,用 obsidian 这款插件的用途不是很大,接下来还是要深入学习如何用 streamlit 结合本地知识库搭建大预言模型。
如果对你有所启发记得点赞。
参考:Obsidian - 本地AI助手 - 哔哩哔哩 (bilibili.com)



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











