









文章目录
- Image classification
- 2020
- 2021
- Dense Contrastive Learning for Self-Supervised Visual Pre-Training
- Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
- Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- Geography-Aware Self-Supervised Learning(ICCV)
- Decoupled Contrastive Learning
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction
- How Well Do Self-Supervised Models Transfer?(CVPR)
- Whitening for Self-Supervised Representation Learning
- Emerging Properties in Self-Supervised Vision Transformers
- 2022
- Masked Autoencoders Are Scalable Vision Learners
- SimMIM: a Simple Framework for Masked Image Modeling
- Decoder Denoising Pretraining for Semantic Segmentation
- Crafting Better Contrastive Views for Siamese Representation Learning(CVPR)
- Self-Supervised Pretraining Improves Self-Supervised Pretraining
- DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
- SimReg:RegressionasaSimpleYet EffectiveToolforSelf-supervised KnowledgeDistillation
- VICRegL: Self-Supervised Learning of Local Visual Features
- TiCo: Transformation Invariance and Covariance Contrast for Self-Supervised Visual Representation Learning
- 2023
- Semantic segmentation
- object detection
- 2021
- 2022
- Context Autoencoder for Self-Supervised Representation Learning
- SELF-SUPERVISED TRANSFORMERS FOR UNSUPERVISED OBJECT DISCOVERY USING NORMALIZED CUT
- Refine and Represent: Region-to-Object Representation Learning
- DETReg: Unsupervised Pretraining with Region Priors for Object Detection
- UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
- 2023
- Remote sensing
- 2021
- 2022
- Embedding Earth: Self-supervised contrastive pre-training for dense land cover classification
- Semantic-aware Dense Representation Learning for Remote Sensing Image Change Detection
- Semantic Segmentation of Remote Sensing Images With Self-Supervised Multitask Representation Learning
- Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images
- Hyperspectral Image Classification With Contrastive Self-Supervised Learning Under Limited Labeled Samples
- Prior Knowledge
- 2020
- 2022
- Prior Knowledge-Augmented Self-Supervised Feature Learning for Few-shot Intelligent Fault Diagnosis of Machines
- Interaction of A Priori Anatomic Knowledge with Self-Supervised Contrastive Learning in Cardiac Magnetic Resonance Imaging
- A Novel Knowledge Distillation Method for Self-Supervised Hyperspectral Image Classification
- 综述
- 相关开源库
Image classification
2020
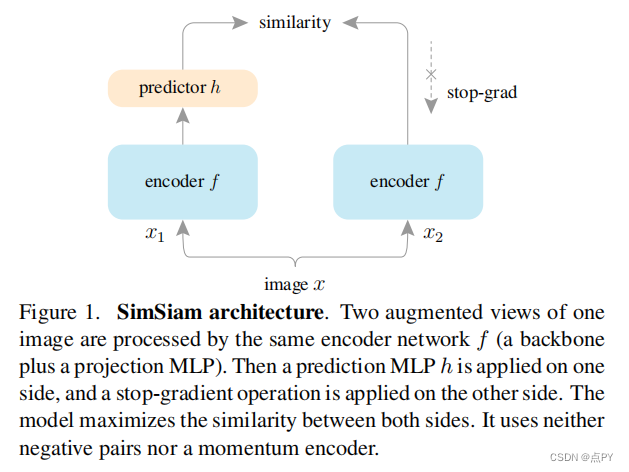
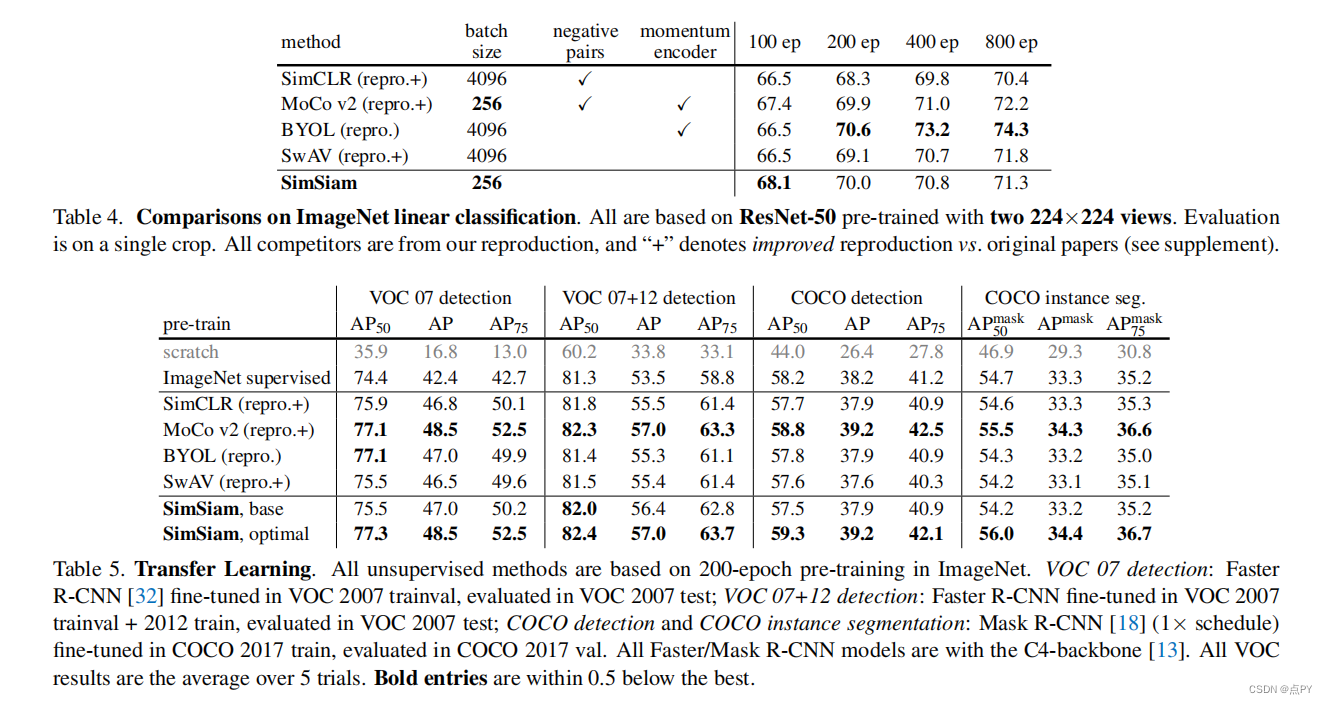
Exploring Simple Siamese Representation Learning
code: https://paperswithcode.com/paper/exploring-simple-siamese-representation
暹罗网络已经成为最近各种无监督视觉表示学习模型的共同结构。这些模型最大限度地提高了一个图像的两个增强之间的相似性,在一定的条件下避免崩溃的解。在本文中,我们报告了令人惊讶的经验结果,简单的暹罗网络可以学习有意义的表示,即使不使用以下内容:(i)负样本对,(ii)大批量,(iii)动量编码器。我们的实验表明,对于损失和结构确实存在坍塌解,但停止梯度操作在防止坍塌方面起着至关重要的作用。我们给出了一个关于停止梯度含义的假设,并进一步证明了概念验证实验的验证。我们的“SimSiam”方法在ImageNet和下游任务上取得了有竞争的结果。我们希望这个简单的基线将激励人们重新思考暹罗体系结构在无监督表示学习中的作用。
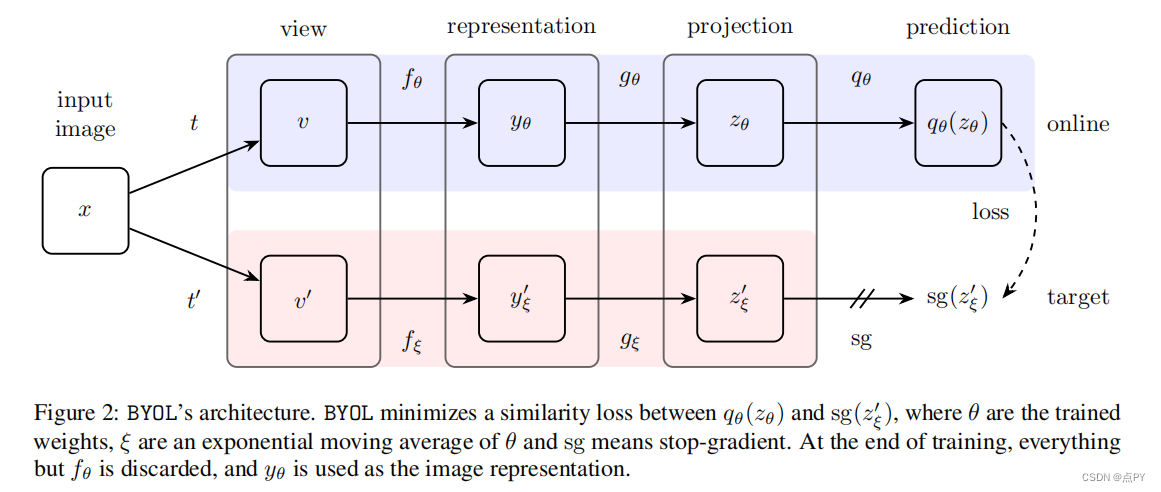
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
code: https://paperswithcode.com/paper/bootstrap-your-own-latent-a-new-approach-to
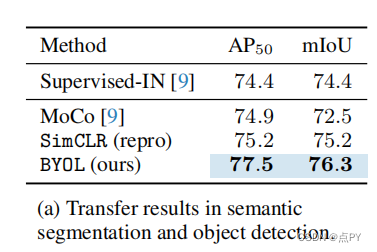
摘要: 我们介绍了引导你自己的潜在性(BYOL),一种新的自监督图像表示学习方法。BYOL依赖于两个神经网络,即在线网络和目标网络,它们相互作用和相互学习。从一个图像的增广视图出发,我们训练在线网络来预测同一图像在不同的增广视图下的目标网络表示。同时,我们用在线网络的慢移动平均值来更新目标网络。虽然最先进的方法依赖于负对,但BYOL在没有它们的情况下实现了一种新的艺术状态。使用ResNet-50架构的线性评估,BYOL在ImageNet上的分类准确率达到74.3%,使用更大的ResNet的分类准确率达到79.6%。我们证明了BYOL在转移和半监督基准上的表现与当前的水平相当或更好。
2021
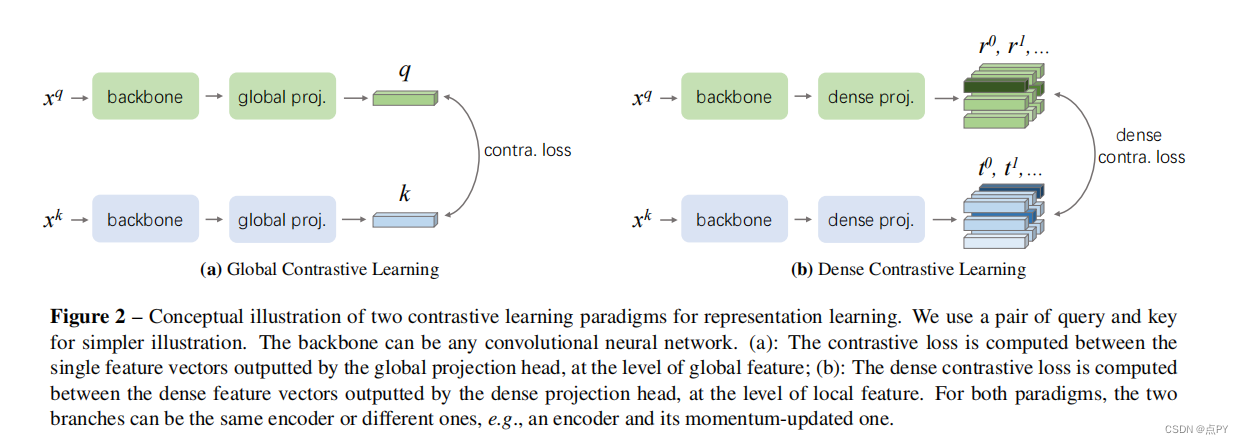
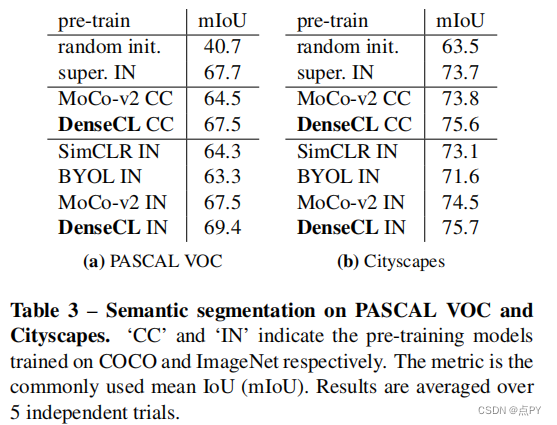
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
code: https://paperswithcode.com/paper/dense-contrastive-learning-for-self
摘要: 到目前为止,大多数现有的自监督学习方法都是为图像分类而设计和优化的。由于图像级预测和像素级预测之间的差异,这些预先训练好的模型对于密集的预测任务可能是次优的。为了填补这一空白,我们的目标是设计一种有效的、密集的自监督学习方法,通过考虑局部特征之间的对应关系,直接在像素(或局部特征)的水平上工作。我们提出了密集对比学习(DenseCL),它通过在输入图像的两个视图之间优化像素水平上的成对对比(dis)相似性损失来实现自监督学习。
与基准方法MoCo-v2相比,我们的方法引入的计算开销可以忽略不计(仅慢1%),但在转移到下游密集预测任务(包括对象检测、语义分割和实例分割)时,表现出持续卓越的性能mance;而且远远超过了最先进的方法。具体而言,在强MoCo-v2基线上,我们的方法在PASCAL VOC对象检测上取得了2.0% AP、COCO对象检测上1.1% AP、COCO 姿态分割上0.9% AP、PASCAL VOC s上3.0% mIoU的显著改进。
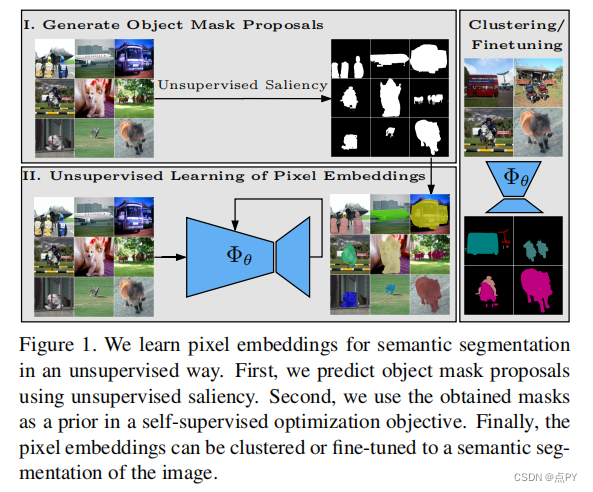
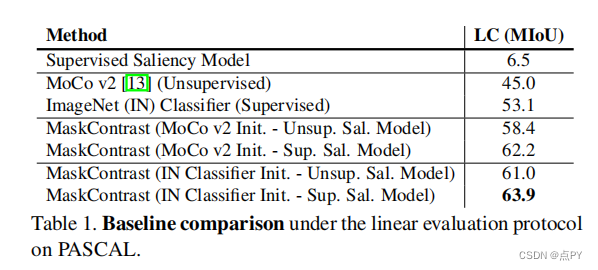
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
code: https://paperswithcode.com/paper/unsupervised-semantic-segmentation-by
摘要:能够在没有监督的情况下学习图像的密集语义表示是计算机视觉中的一个重要问题。然而,尽管这个问题很重要,但这个问题仍然相当未被探索,除了少数例外,考虑了在具有狭窄视觉域的小规模数据集上的无监督语义分割。在本文中,我们首次尝试解决传统上用于监督情况的数据集上的问题。为了实现这一点,我们引入了一个两步框架,在一个对比优化目标中采用一个预先确定的中间水平先验来学习像素嵌入。这标志着与依赖于代理任务或端到端集群的现有工作有很大的偏差。此外,我们讨论了包含对象或其部分信息的先验的重要性,并讨论了以无监督的方式获得这样种先验的几种可能性。
实验评价表明,我们的方法比现有的工作具有关键的优势。首先,学习到的像素嵌入可以利用pascal上的K-Means直接聚类在语义组中。在完全无监督的设置下,在这样一个具有挑战性的基准测试上解决语义分割任务是没有先例的。其次,当转移到新的数据集时,例如COCO和davis时,我们的表示可以改进超过强基线。
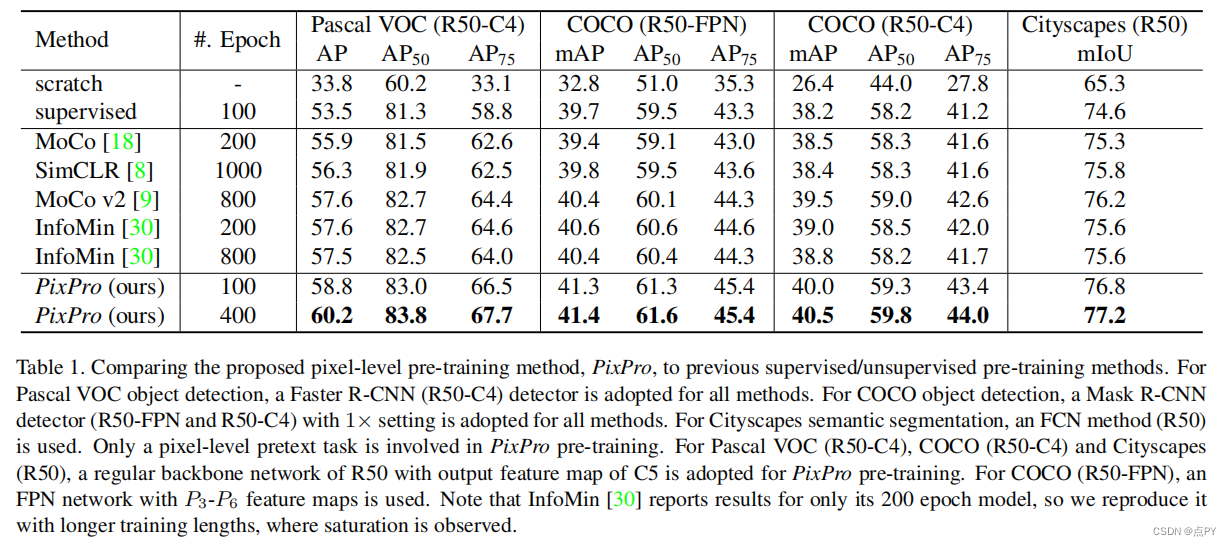
Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
code: https://paperswithcode.com/paper/propagate-yourself-exploring-pixel-level
摘要: 无监督视觉表示学习的对比学习方法已经达到了显著的迁移表现水平。我们认为,对比学习的能力尚未被完全释放,因为目前的方法只在实例级的借口任务上进行训练,导致对于需要密集像素预测的下游任务可能是次优的表示。在本文中,我们引入了像素级的借口任务来学习密集的特征表示。第一个任务直接在像素水平上应用对比学习。此外,我们还提出了一个像素到传播的一致性任务,它可以产生更好的结果,甚至大大超过了最先进的方法。具体来说,通过转移到PascalVOC目标检测(C4)、COCO目标检测(FPN/C4)和城市网络实现60.2AP、60.2AP、41.4/40.5mAP和77.2mIoU语义分割,达到2.6AP、0.8/1.0mAP和1.0mIoU。
此外,像素级借口任务不仅对常规主干网络进行预训练,而且对密集下游任务的头网络也有效,是实例级对比方法的补充。这些结果表明了在像素水平上定义借口任务的强大潜力,并为无监督视觉表示学习提供了一条新的前进路径。

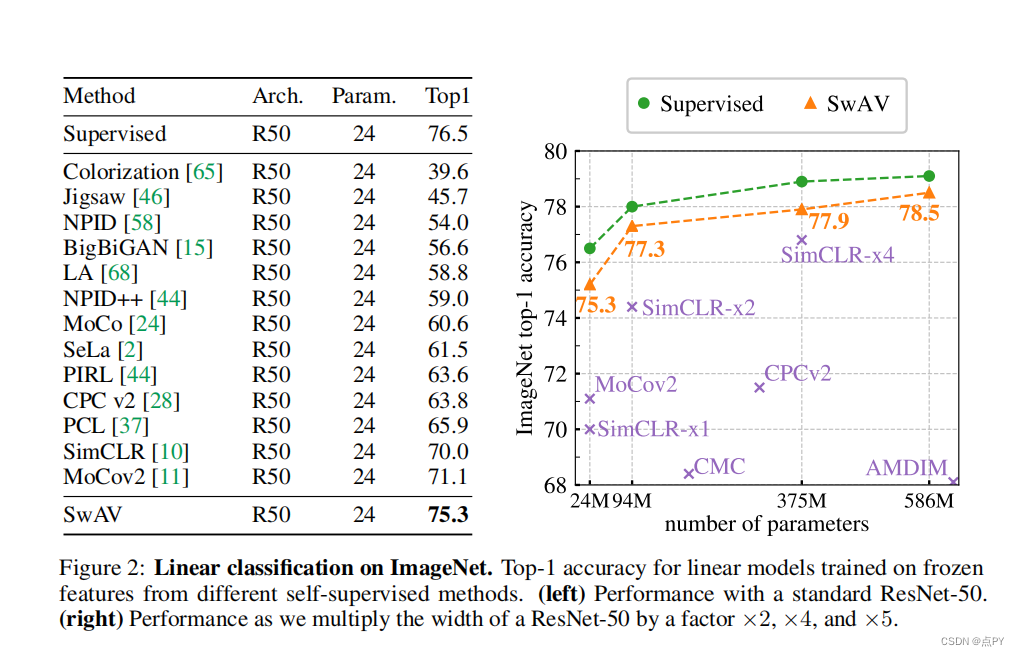
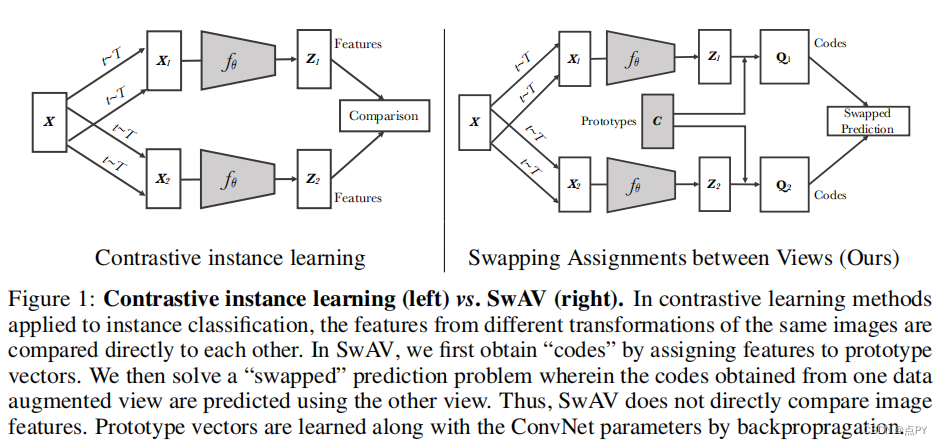
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
code: https://paperswithcode.com/paper/unsupervised-learning-of-visual-features-by
摘要:无监督图像表示显著减少了监督预训练的差距,特别是最近对比学习方法的成就。这些对比方法通常在线工作,依赖于大量显式成对特征比较,这在计算上具有挑战性。在本文中,我们提出了一个在线算法,SWAV,它利用了对比的方法,而不需要计算两两比较。具体来说,我们的方法同时对数据进行聚类,同时加强为同一图像的不同增强(或“视图”)产生的聚类分配之间的一致性,而不是像对比学习那样直接比较特征。简单地说,我们使用一种“交换”的预测机制,其中我们从另一个视图的表示来预测一个视图的代码。我们的方法可以用大批量和小批量进行训练,并可以扩展到无限量的数据。与以往的对比方法相比,我们的方法的内存效率更高,因为它不需要一个大的内存库或一个特殊的动量网络。此外,我们还提出了一种新的数据增强策略,多作物,它使用不同分辨率的混合视图来代替两个全分辨率的视图,而不增加内存或计算需求。我们通过使用ResNet-50在ImageNet上达到75.3%的前1名准确率,并在所有考虑的转移任务上超过监督预训练来验证我们的发现。
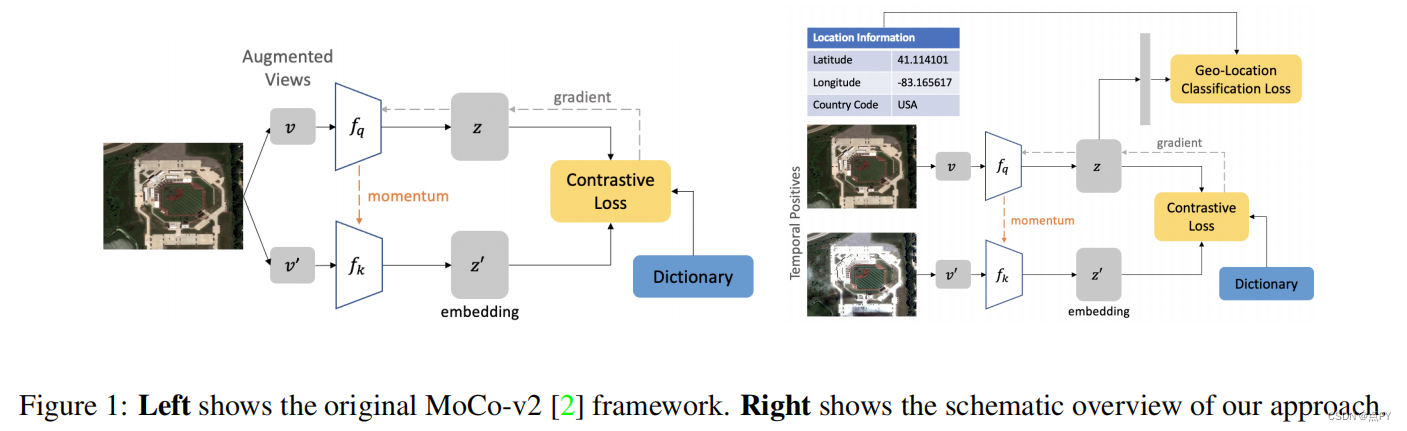
Geography-Aware Self-Supervised Learning(ICCV)
摘要: 对比学习方法显著缩小了计算机视觉任务中有监督学习和无监督学习之间的差距。在本文中,我们探讨了它们在地理定位数据集上的应用,例如遥感,其中未有标记的数据往往是丰富的,但有标记的数据是稀缺的。我们首先表明,由于它们的不同特征,在标准基准上对比学习和监督学习之间存在非平凡的差距。为了缩小这一差距,我们提出了利用遥感数据时空结构的新训练方法。我们利用随时间变化的空间对齐图像,在对比学习和地理位置中构建时间正对来设计前文本任务。实验结果表明,该方法缩小了在遥感图像分类、目标检测和语义分割等方面的对比学习和监督学习之间的差距。此外,我们还证明了该方法也可以应用于地理标记的图像网图像,提高了各种任务的下游性能。
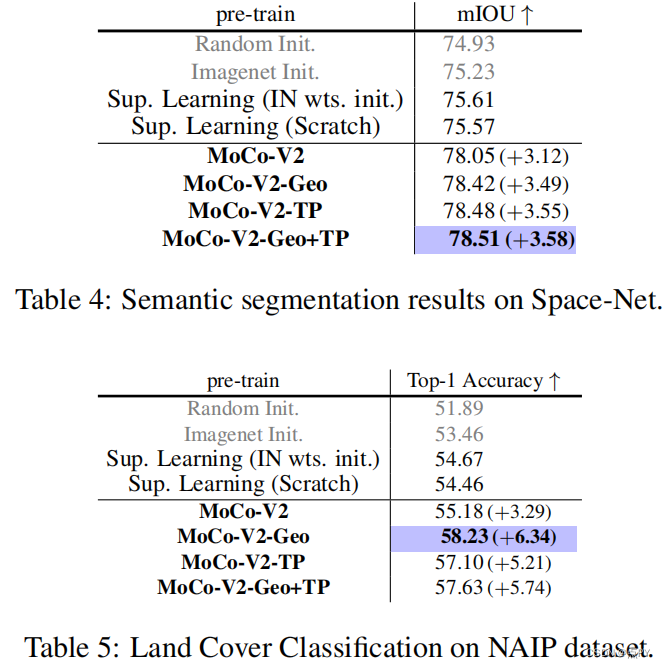
Decoupled Contrastive Learning
code: https://paperswithcode.com/paper/decoupled-contrastive-learning-1
摘要: 对比学习(CL)是自我监督学习(SSL)中最成功的范式之一。在原则上,它认为同一图像的两个增强“观点”被拉近,而所有其他图像为消极,被推得更远。然而,在基于cl的技术令人印象深刻的成功背后,它们的制定往往依赖于大量的计算设置,包括大样本批次、广泛的训练时代等。因此,我们有动力去解决这些问题,并建立一个简单、有效、但有竞争力的对比学习基线。具体来说,我们从理论和实证研究中发现,在广泛使用的InfoNCE损失中存在明显的负-正耦合(NPC)效应,导致对批次大小的学习效率不合适。通过消除NPC效应,我们提出了解耦对比学习(DCL)损失,从分母中去除正项,显著提高了学习效率。DCL在对次优超参数敏感性较低的情况下实现了竞争性能,既不需要SimCLR的大批量,也不需要MoCo的动量编码,也不需要大时代。我们用各种基准测试来演示,同时显示鲁棒性对次优超参数不那么敏感。值得注意的是,使用DCL的SimCLR在200个周期内使用256的批处理,达到了68.2%的ImageNet-1K前1的精度,比SimCLR基线高出6.4%。此外,DCL可以与SOTA对比学习方法NNCLR相结合,在400个时代实现了512批大小的ImageNet-1K前1的准确率,这代表了对比学习中的一种新的SOTA。我们相信DCL为未来的对比SSL研究提供了一个有价值的基线。
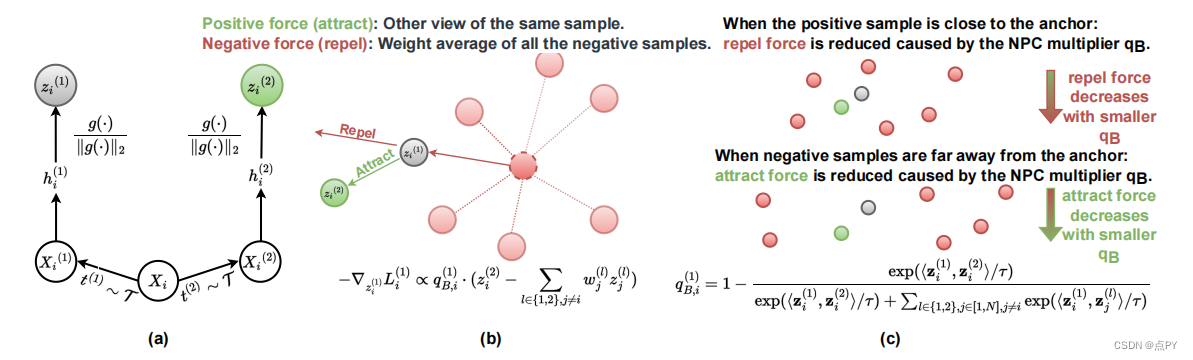
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
code: https://paperswithcode.com/paper/barlow-twins-self-supervised-learning-via
摘要: 自监督学习(SSL)正在迅速缩小在大型计算机视觉基准上与监督方法的差距。SSL的一个成功方法是学习对输入样本的失真不变的嵌入。然而,这种方法反复出现的一个问题是平凡常数解的存在。目前的大多数方法都是通过仔细的实现细节来避免这样的解决方案的。我们提出了一个目标函数,通过测量两个相同的网络的输出之间的互相关矩阵,自然地避免了崩溃,并使其尽可能接近单位矩阵。这导致一个样本的扭曲版本的嵌入向量相似,同时最小化这些向量的分量之间的冗余。这种方法被称为巴洛双胞胎,因为神经科学家H.巴洛的冗余减少原理应用于一对相同的网络。巴洛双胞胎不需要大量的数量,也不需要网络双胞胎之间的不对称,如预测网络、梯度停止或权重更新的移动平均值。有趣的是,它受益于非常高维的输出向量。在低数据状态下,巴洛双胞胎在ImageNet上优于以前的方法,并且与目前使用线性分类器头的ImageNet分类以及分类和目标检测的转移任务的技术相同。
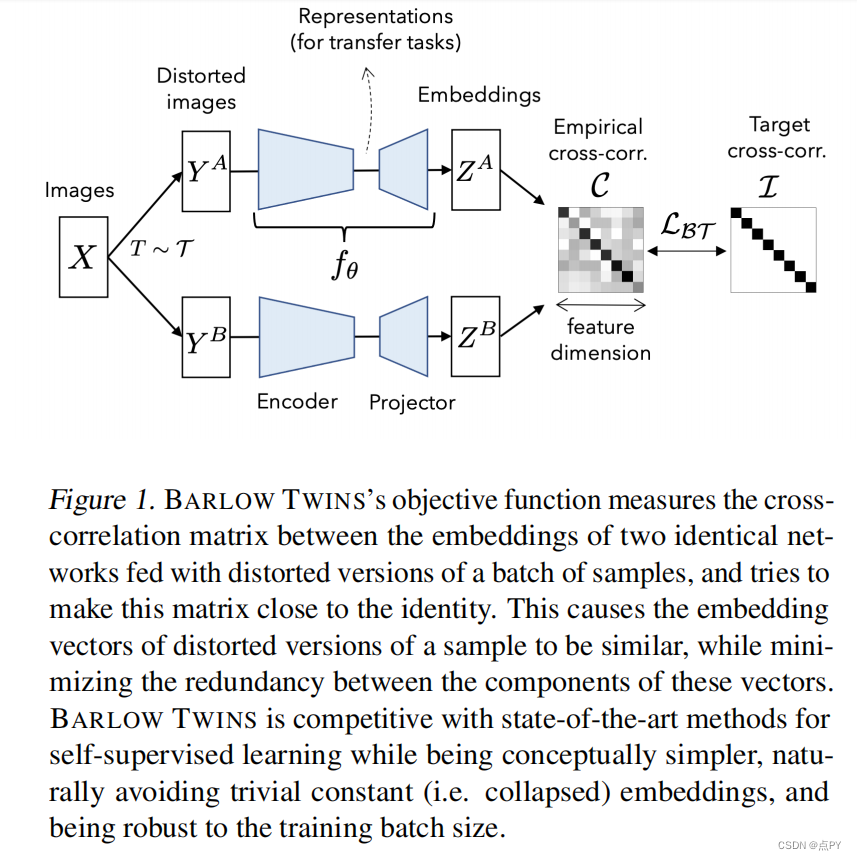
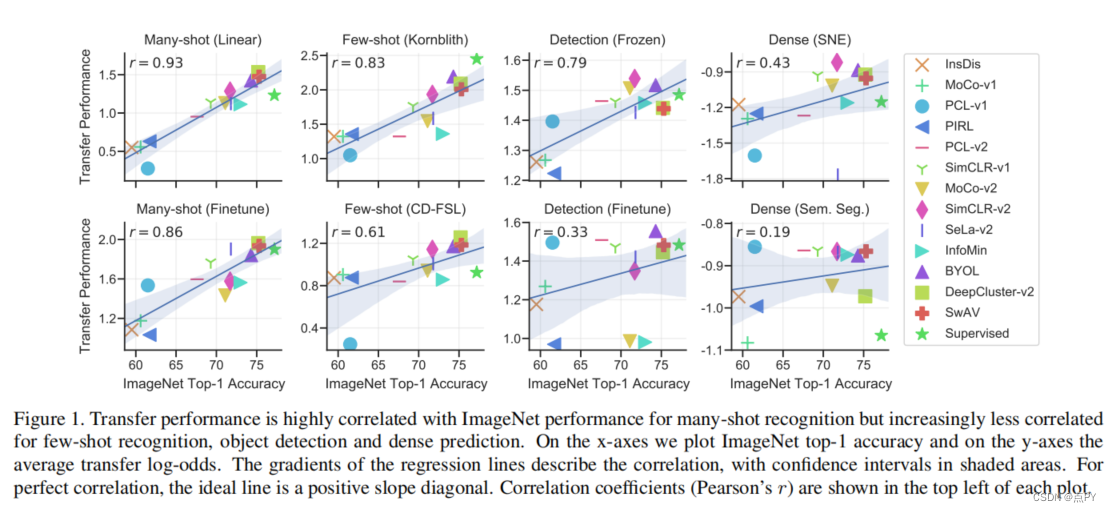
How Well Do Self-Supervised Models Transfer?(CVPR)
摘要:自我监督视觉表征学习最近取得了巨大的进展,但没有大规模的评价来比较目前许多可用的模型。我们评估了13个顶级自监督模型在40个下游任务上的传输性能,包括多镜头和少镜头识别、目标检测和密集预测。我们将它们的表现与监督基线进行了比较,表明在大多数任务中,最好的自我监督模型优于监督,证实了最近观察到的趋势。我们发现ImageNet Top-1的精度与多镜头识别的转移高度相关,但对于少镜头、目标检测和密集预测的精度越来越低。没有一种单一的自我监督方法在总体上占主导地位,这表明普遍的预训练仍然没有得到解决。我们对特征的分析表明,顶级自监督学习者不能保留颜色信息和监督替代方案,但倾向于诱导更好的分类器校准,和更少的注意过拟合。
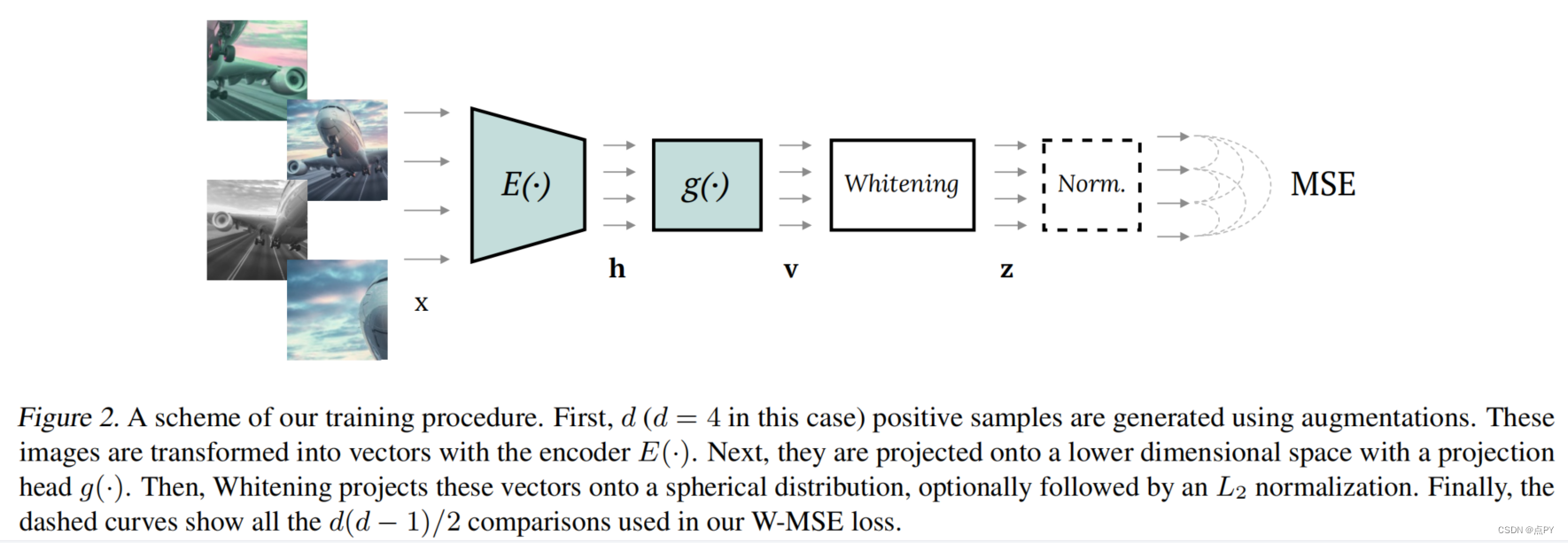
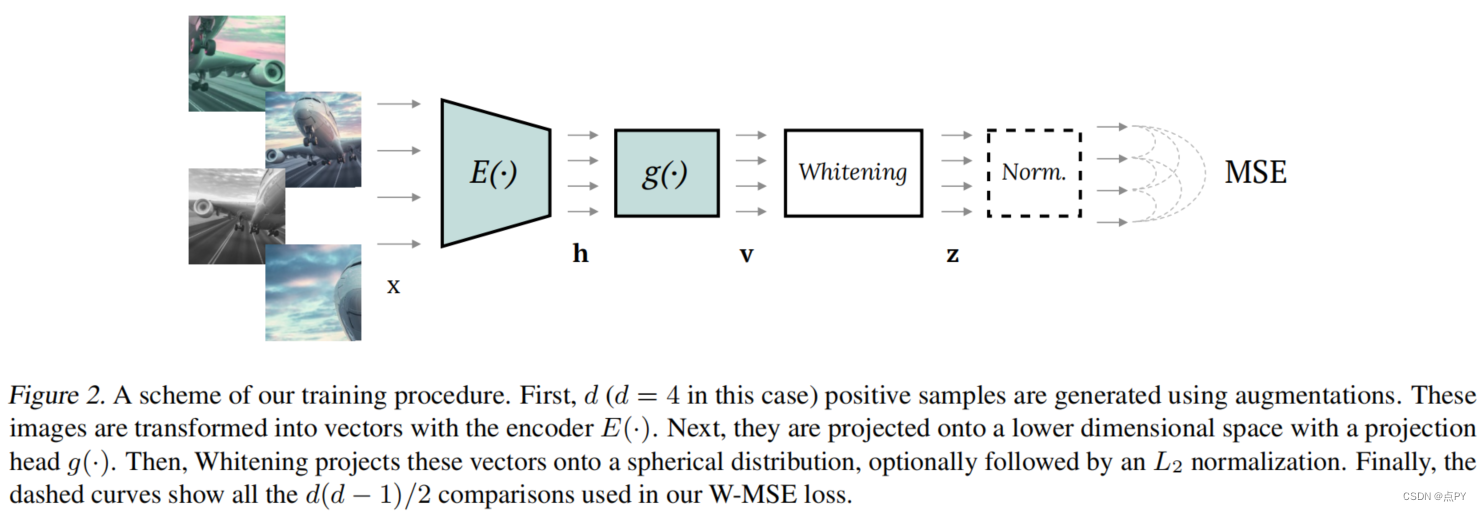
Whitening for Self-Supervised Representation Learning
code: https://github.com/htdt/self-supervised
摘要:目前大多数的自我监督表示学习(SSL)方法都是基于对比损失和实例识别任务,其中同一图像实例的增强版本(“正”)与从其他图像中提取的实例(“负”)进行对比。为了使学习有效,应该将许多负对与正对进行比较,这是需要计算要求的。本文提出了一个基于延迟空间特征白化的SSL的不同方向和一个新的损失函数。白化操作对批样本有“散射”效应,避免了所有样本表示坍缩到一个点的退化解。我们的解决方案不需要非对称网络,而且它在概念上很简单。此外,由于不需要负对,所以我们可以从同一个图像实例中提取多个正对。
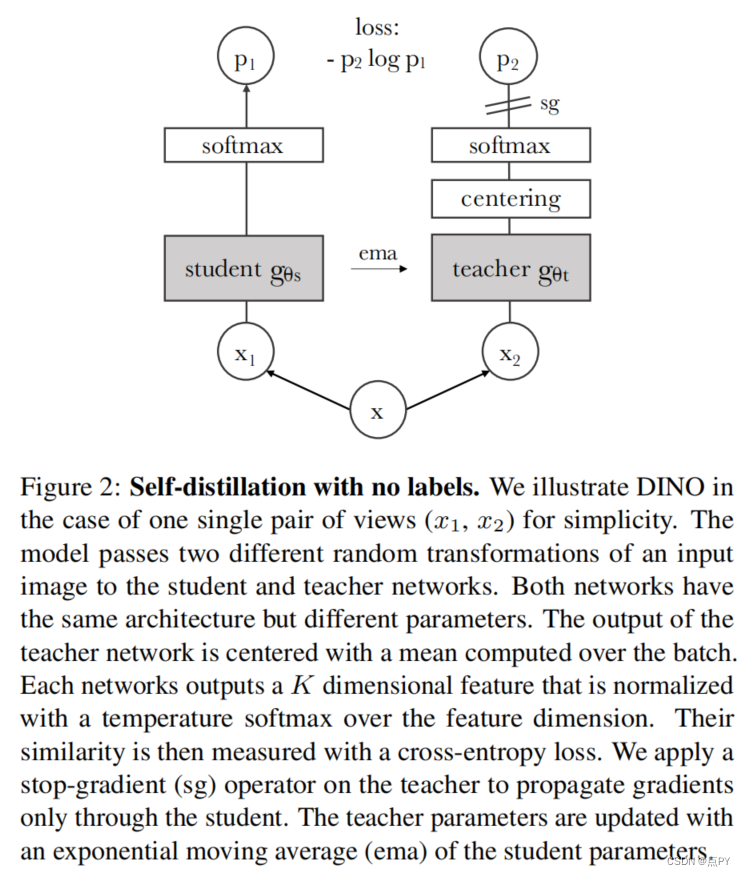
Emerging Properties in Self-Supervised Vision Transformers
code: https://github.com/facebookresearch/dino

摘要: 在本文中,我们质疑自监督学习是否为视觉变换(ViT)[19]提供了新的特性,与卷积网络(凸网络)相比脱颖而出。除了将自我监督方法适应这种结构特别有效之外,我们还做了以下观察:首先,自我监督ViT特征包含关于图像语义分割的显式信息,这在监督ViT和凸网中都不明显。其次,这些特征也是优秀的k-NN分类器,在ImageNet上达到了78.3%的前1名。我们的研究还强调了动量编码器[33]、多作物训练[10]和使用带有vit的小贴片的重要性。我们将我们的发现实现到一个简单的自我监督的方法中,称为DINO,我们将其解释为一种没有标签的自蒸馏形式。我们通过VIiT-Base的线性评估,在ImageNet上达到80.1%的前1,显示了DINO和ViTs之间的协同作用。
2022
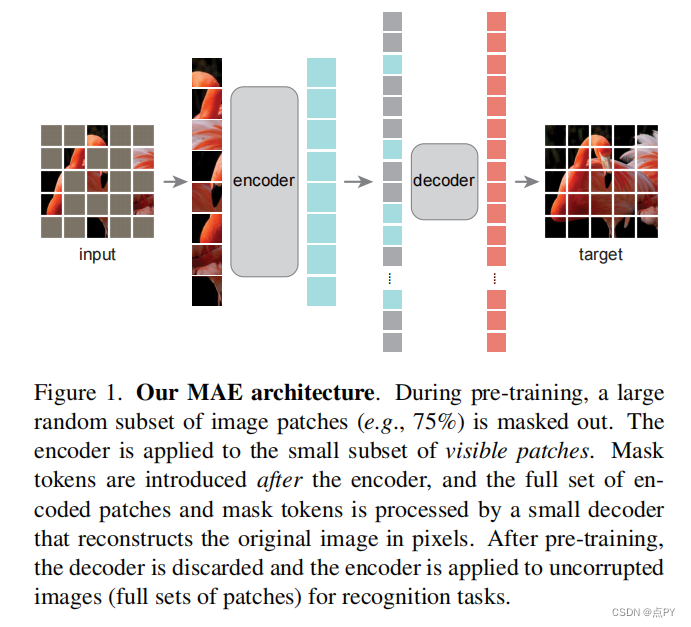
Masked Autoencoders Are Scalable Vision Learners
code: https://paperswithcode.com/paper/masked-autoencoders-are-scalable-vision
摘要: 本文证明了掩码自动编码器(MAE)是一种可扩展的计算机视觉自监督学习者。我们的MAE方法很简单:我们掩蔽输入图像的随机斑块,并重建缺失的像素。它是基于两个核心的设计。首先,我们开发了一个非对称的编码-解码器架构,一个编码器只操作于补丁的可见子集(没有掩码标记),以及一个轻量级解码器,从潜在表示和掩码标记重构原始图像。其次,我们发现掩盖高比例的输入图像,例如75%,产生一个平凡和有意义的自我监督任务。耦合这两种设计使我们能够有效地训练大型模型:我们加速训练(3×或更多)并提高准确性。我们的可扩展方法允许学习能够很好地推广的高容量模型:例如,在只使用ImageNet-1K数据的方法中,一个普通的ViT-Huge模型达到了最好的精度(87.8%)。在下游任务中的传输性能优于监督预训练,并显示出良好的缩放行为。
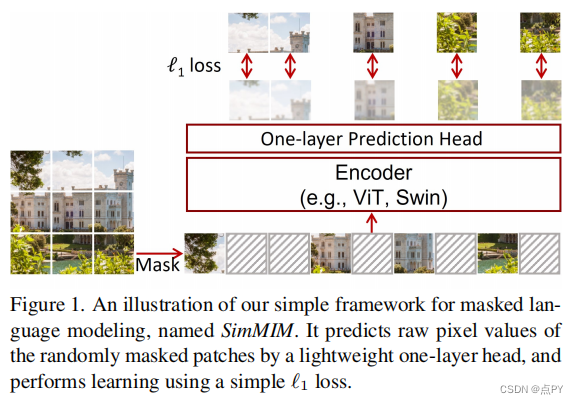
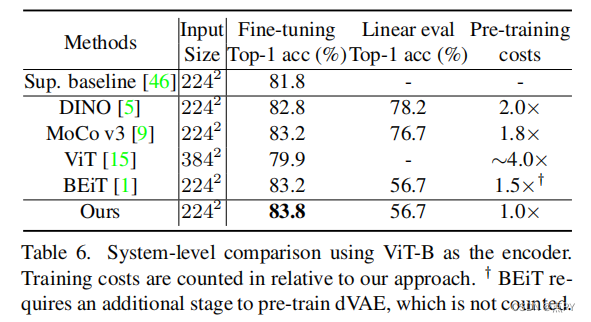
SimMIM: a Simple Framework for Masked Image Modeling
code: https://github.com/microsoft/simmim
摘要: 本文提出了一个简单的掩蔽图像建模框架SimMIM。我们已经简化了最近提出的相关方法,而不需要特殊的设计,如通过离散VAE或聚类的块级掩蔽和标记化。调查是什么使掩蔽图像建模任务学习良好的表示,我们系统地研究主要组件框架,发现每个组件的简单设计显示了非常强的表示学习性能:1)随机掩蔽的输入图像中等大屏蔽补丁大小(例如,32)使一个强大的预文本任务;2)通过直接回归预测原始像素的RGB值表现并不比复杂设计的补丁分类方法差;3)预测头可以像线性层一样轻,不会比较重的层差。使用ViT-B,我们的方法也在该数据集上通过预训练,在ImageNet-1K上达到83.8%的前1微调精度,超过之前的最佳方法+0.6%。当应用于具有约6.5亿参数的更大模型SwinV2-H时,仅使用ImageNet-1K数据在ImageNet-1K上达到87.1%的前1精度。我们还利用这种方法来解决大规模模型训练所面临的数据需求问题,即3B模型(SwinV2-G)被成功训练,以在四个具有代表性的视觉基准上实现最先进的准确性,使用比以往的实践(JFT-3B)少40×的标记数据。
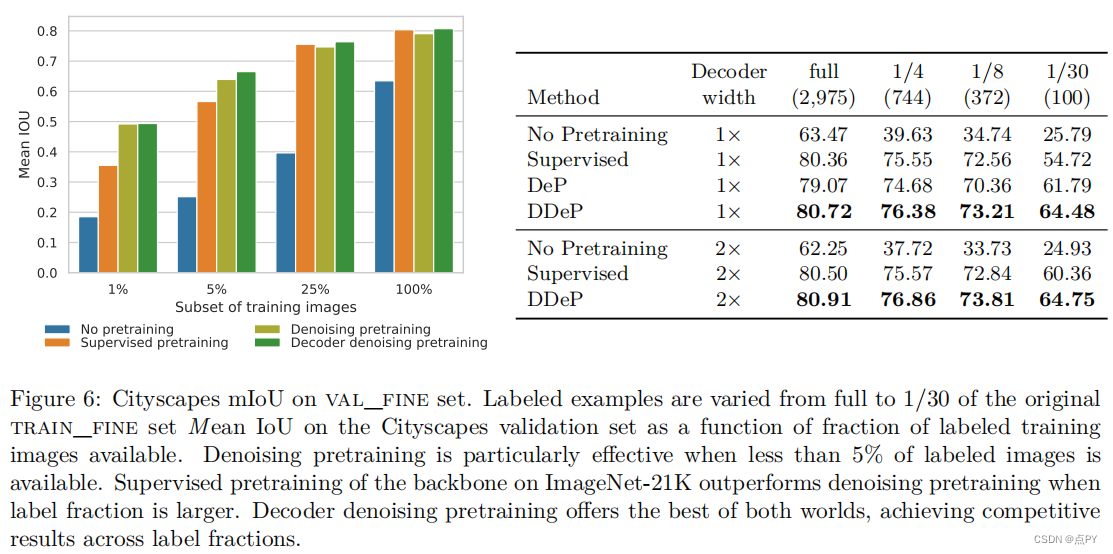
Decoder Denoising Pretraining for Semantic Segmentation
code: https://github.com/bwconrad/decoder-denoising
摘要: 语义分割标签的获取代价昂贵且耗时较长。因此,预训练常用提高分割模型的标签效率。通常,一个分割模型的编码器被预先训练为一个分类器,并且解码器被随机初始化。在这里,我们认为解码器的随机初始化可能是次优的,特别是当很少有标记的例子可用。本文提出了一种基于去噪的解码器预训练方法,该方法可与编码器的监督预训练相结合。我们发现在ImageNet数据集上的解码器去噪预训练强烈优于仅编码器监督预训练。尽管解码器去噪预训练很简单,但它在标签高效的语义分割上取得了最先进的结果,并在城市景观、Pascal上下文和ADE20K数据集上提供了相当大的收益。

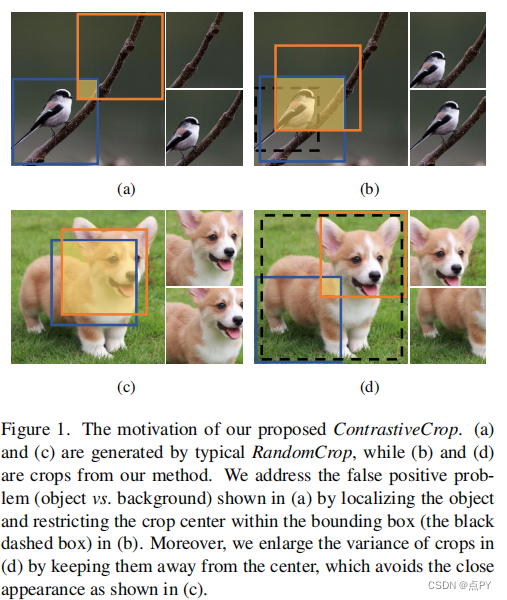
Crafting Better Contrastive Views for Siamese Representation Learning(CVPR)
code: https://github.com/xyupeng/ContrastiveCrop
知乎解读:https://mp.weixin.qq.com/s?__biz=MjM5MjgwNzcxOA==&mid=2247486171&idx=1&sn=99271087396ef01edfad6e70fe0c3027&chksm=a6a1e49291d66d84ebb2722aa732866b357ea41137ce5105eeab666f49ba9efc442ed69435db#rd
abstract: 最近的自监督对比学习方法极大地受益于暹罗结构,旨在最小化正对之间的距离。对于高性能的暹罗表示学习,关键之一是设计良好的对比对。以前的大多数工作只是简单地应用随机抽样来制作同一图像的不同作物,这忽略了可能会降低视图质量的语义信息。在这项工作中,我们提出了逆向作物,它可以有效地产生更好的作物为暹罗表征学习。首先,在训练过程中提出了一种完全无监督的语义感知对象定位策略。这指导我们生成对比性的视图,以避免大多数假阳性(例如,对象与背景)。此外,我们的经验发现,观点与相似的外观对于暹罗模型训练是微不足道的。因此,进一步设计了一个中心抑制抽样来扩大作物的方差。值得注意的是,我们的方法仔细考虑了对比学习的正对,而额外的训练开销可以忽略不计。作为一个插件游戏和框架不可知的模块,对比作物在CIFAR-10、CIFAR-100、TinyMmageNet和STL-10上,SimCLR、MoCo、BYOL、SimSiam的分类准确率持续提高了0.4%∼2.0%。在ImageNet-1K上进行预训练时,下游检测和分割任务也取得了更好的结果。
Self-Supervised Pretraining Improves Self-Supervised Pretraining
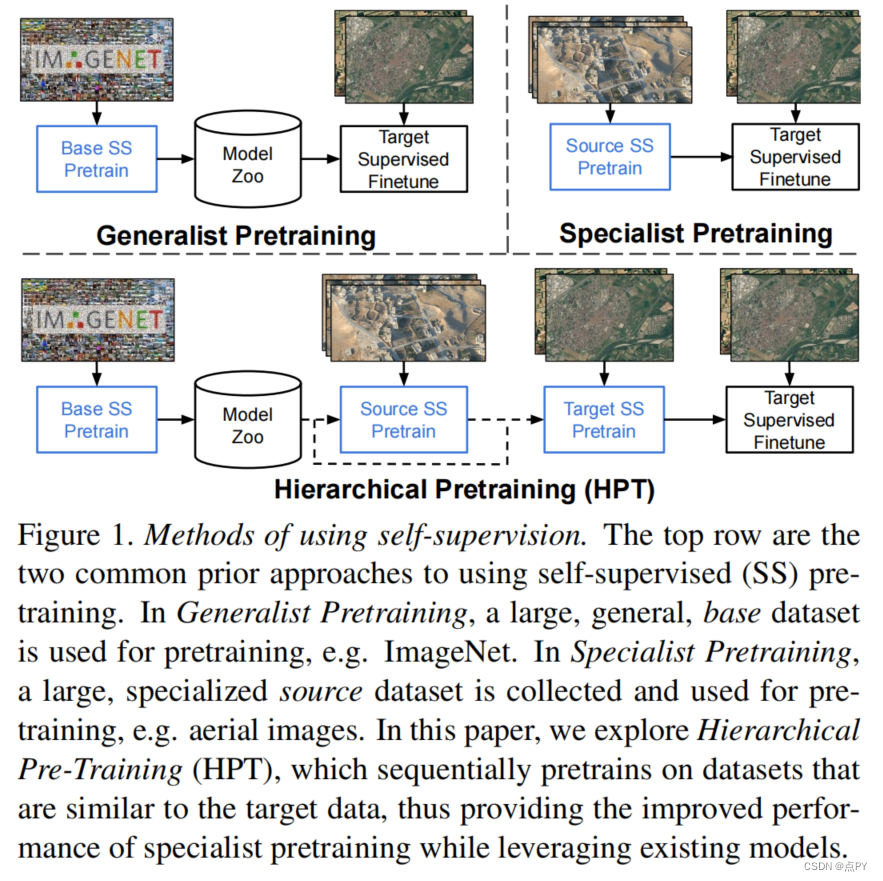
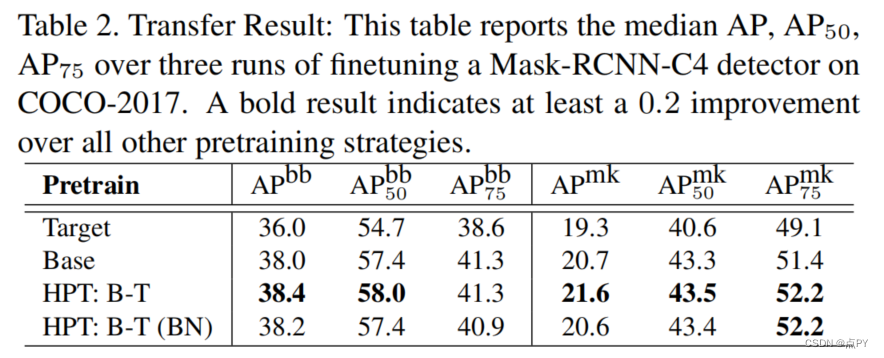
摘要:虽然自我监督的预训练已被证明对许多计算机视觉任务是有益的,但它需要昂贵和冗长的计算,大量的数据,并且对数据增强很敏感。之前的工作表明,在与目标数据不同的数据集上预先训练的模型,如在ImageNet上训练的胸部x光模型,不如从零开始训练的模型。缺乏预训练资源的用户必须使用性能较低的现有模型。本文研究了分层预训练(HPT),通过使用现有的预训练模型初始化预训练过程,减少了收敛时间,提高了训练精度。
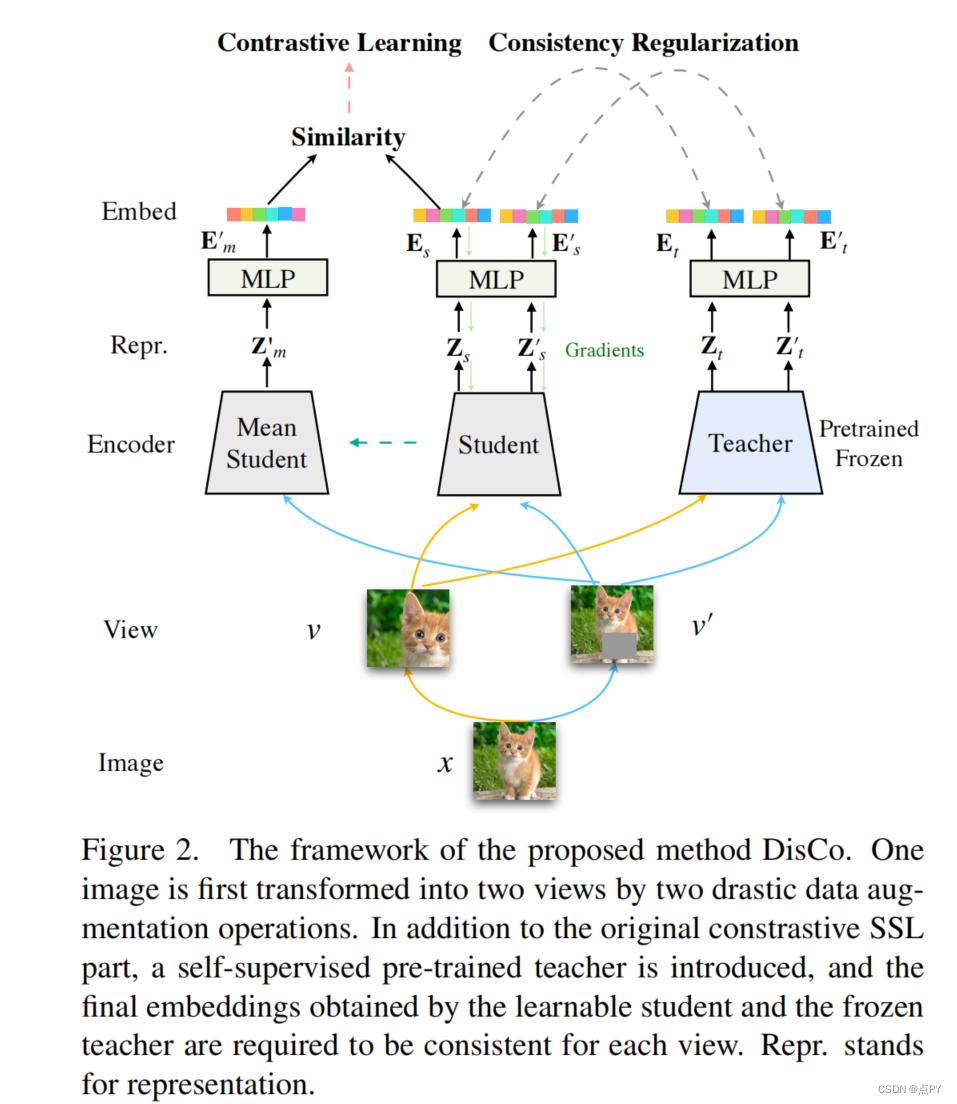
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
code: https://github.com/Yuting-Gao/DisCo-pytorch
摘要: 虽然自我监督表征学习(SSL)受到了社区的广泛关注,但最近的研究认为,当模型规模减小时,它的性能将会急剧下降。由于目前的SSL方法主要依靠对比学习来训练网络,在本工作中,我们提出了一种简单而有效的方法,即蒸馏对比学习(DisCo)来缓解这一问题。具体来说,我们发现主流SSL方法的最终内在嵌入包含了最丰富的信息,并提出通过约束学生的最后嵌入与教师的嵌入一致,最大限度地将教师的知识传递到轻量级模型中。此外,我们发现存在一种被称为蒸馏瓶颈的现象,并提出了扩大嵌入维数来缓解这一问题。由于MLP只存在于SSL阶段,因此我们的方法在下游任务部署期间不会向轻量级模型引入任何额外的参数。实验结果表明,我们的方法在所有轻量级模型上都大大超过了最先进的水平。特别是,当ResNet-101/ResNet-50分别作为教师教授效率Net-B0时,效率Net的线性结果分别提高了22.1%和19.7%,与ResNet-101/ResNet-50的参数少得多。
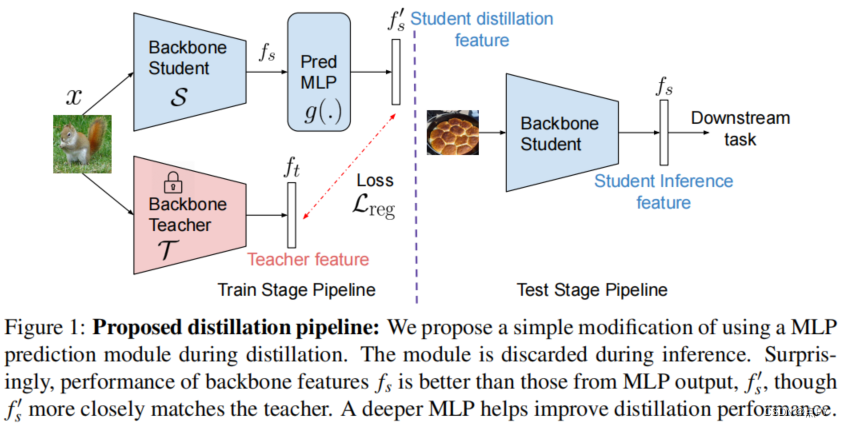
SimReg:RegressionasaSimpleYet EffectiveToolforSelf-supervised KnowledgeDistillation
code: https://github.com/UCDvision/simreg
摘要: 特征回归是将大型神经网络模型提取为较小模型的一种简单方法。我们表明,通过对网络架构进行简单的改变,回归可以比更复杂的最先进的知识蒸馏方法表现得更好。令人惊讶的是,在CNN主干中添加一个多层感知器头是有益的,即使只在蒸馏过程中使用,而在下游任务中被丢弃。因此,更深层次的非线性投影可以用来精确地模拟教师,而不改变推理架构和时间。此外,我们利用独立的投影头同时提取多个教师网络。我们还发现,使用相同的弱增广图像作为输入的教师和学生网络有助于蒸馏。在ImageNet数据集上的实验证明了在各种自监督蒸馏设置下的有效性。
VICRegL: Self-Supervised Learning of Local Visual Features
code: https://github.com/lightly-ai/lightly/tree/master/lightly
摘要:最近的学习图像表示的自监督方法要么是产生具有不变性的全局特征,要么是产生一组局部特征。前者最适合用于分类任务,而后者最适合用于检测和分割任务。本文探讨了学习局部特征和全局特征之间的基本权衡。提出了一种新的VICRegL方法,该方法可以同时学习良好的全局和局部特征,在检测和分割任务上获得良好的性能,同时在分类任务上保持良好的性能。具体地说,一个标准卷积网络体系结构的两个相同的分支被输入同一图像的两个不同的扭曲版本。将VICReg准则应用于全局特征向量对。同时,将VICReg准则应用于在最后一个池化层之前出现的局部特征向量对。如果两个局部特征向量的l2距离低于阈值,或者它们的相对位置与两个输入图像之间已知几何变换一致,它们就会相互吸引。我们证明了在线性分类和分割转移任务上的强大性能。
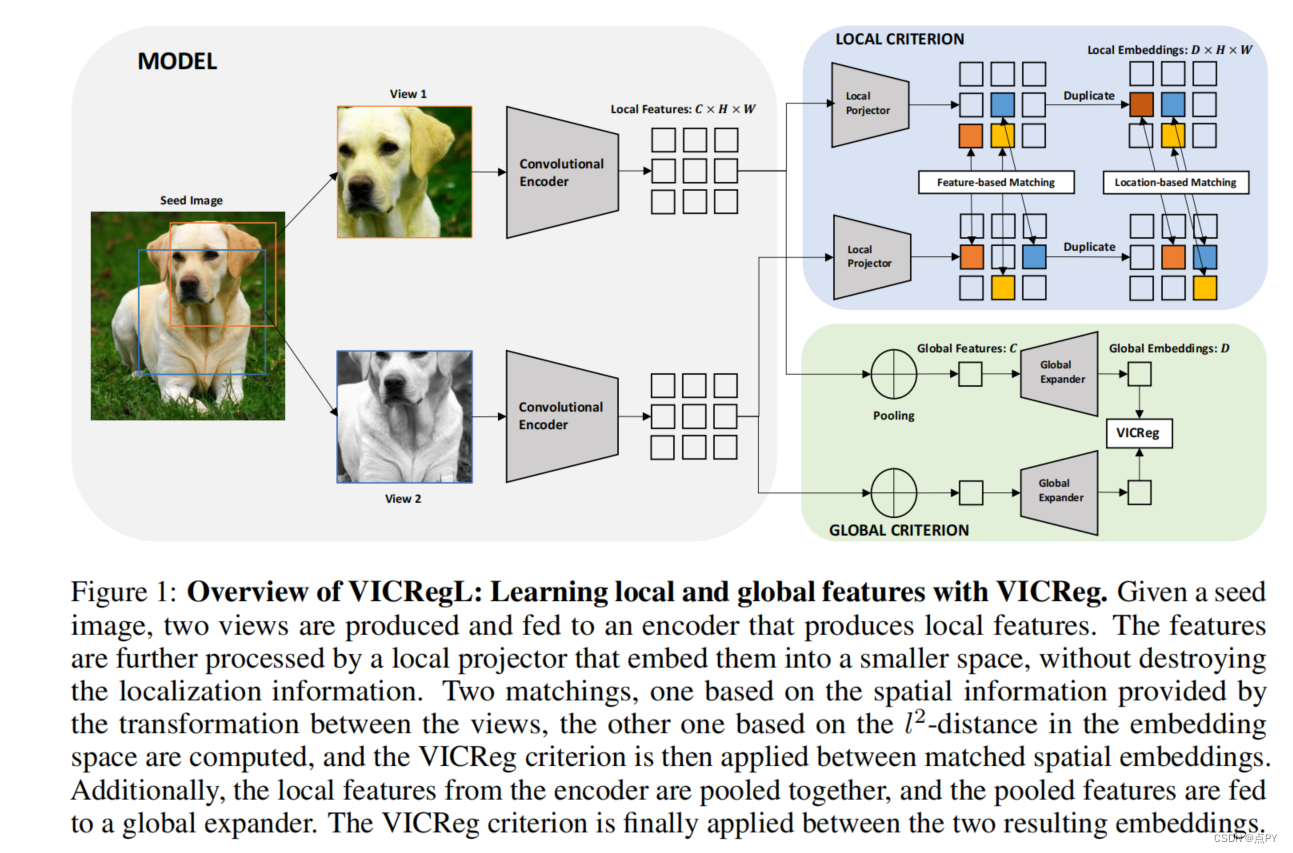
TiCo: Transformation Invariance and Covariance Contrast for Self-Supervised Visual Representation Learning
code: https://github.com/lightly-ai/lightly/tree/master/lightly
摘要:我们提出了用于自变量和协方差变换协方差对比(TiCo)的自监督视觉表示学习。与其他最近的自监督学习方法类似,我们的方法是基于最大化同一图像的不同扭曲版本的嵌入之间的一致性,这推动编码器产生变换不变表示。为了避免编码器生成常数向量的平凡解,我们通过惩罚低秩解来正则化不同图像嵌入的协方差矩阵。通过联合最小化变换不变性损失和协方差对比损失,我们得到了一个能够为下游任务生成有用的表示形式的编码器。我们分析了我们的方法,并表明它可以看作是MoCo [16]的一个变体,具有无限大小的隐式内存库,而没有额外的内存成本。这使得我们的方法在使用小批处理大小时比其他方法执行得更好。TiCo也可以被看作是巴洛双胞胎[35]的一个修改。通过将对比方法和冗余减少方法连接在一起,TiCo为我们提供了关于联合嵌入方法如何工作的新见解。
2023
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
code and paper: https://paperswithcode.com/paper/designing-bert-for-convolutional-networks
“删除-再恢复” 形式的自监督预训练可追溯到 2016 年,早于 18 年的 BERT 与 21 年的 MAE。然而在长久的探索中,这种BERT/MAE 式的预训练算法仍未在卷积模型上成功(即大幅超过有监督学习)。本篇 ICLR Spotlight 工作 “Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling” 则首次见证了 BERT/MAE 预训练在 CNN 上的成功,无论是经典 ResNet 还是新兴ConvNeXt均可从中受益,初步地预示了卷积网络上新一代自监督范式的未来。
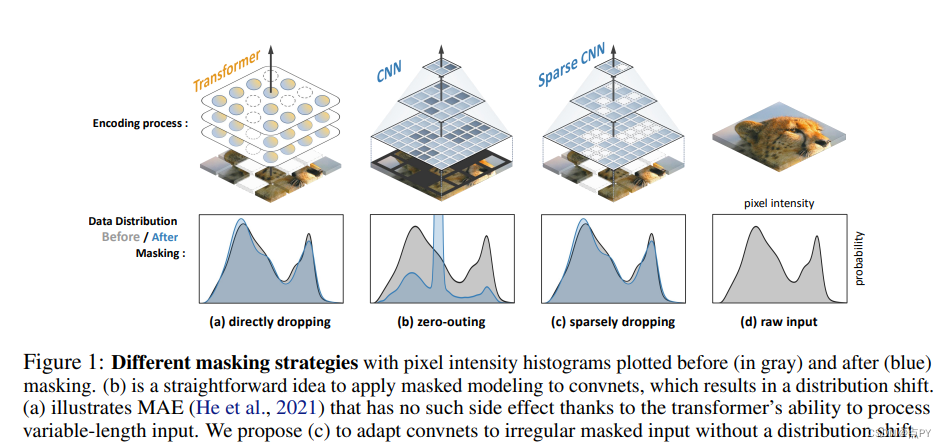
摘要: 我们识别并克服了将BERT式预训练或掩蔽图像建模的成功扩展到卷积网络(凸网)的两个关键障碍: (i)卷积操作不能处理不规则的、随机掩蔽的输入图像;(ii)BERT预训练的单尺度性质与凸网的层次结构不一致。对于(i),我们将未被掩蔽的像素视为三维点云的稀疏体素,并使用稀疏卷积进行编码。这是第一次在二维掩蔽建模中使用稀疏卷积。对于(ii),我们开发了一个分层解码器来重建来自多尺度编码特征的图像。我们的方法,称为稀疏masKed建模(SparK),是通用的:它可以直接用于任何卷积模型,而不需要修改主干。我们在经典(ResNet)和现代(ConvNeXt)模型上验证了它:在三个下游任务上,它以同样大的优势超过了最先进的对比性建模和基于转换器的掩码建模(约+1.0%)。在目标检测和实例分割方面的改进更为显著(高达+3.5%),验证了学习到的特征的强可转移性。通过在更大的网络上观察更多的收益,我们也发现了它有利的尺度行为。所有这些证据揭示了生成预训练的前景。
Semantic segmentation
2022
Learning Where to Learn in Cross-View Self-Supervised Learning
摘要:自监督学习(SSL)取得了巨大的进展,在很大程度上缩小了与监督学习的差距,其中表示学习主要由嵌入空间的投影来引导。在投影过程中,目前的方法只是采用统一的像素聚合进行嵌入;然而,这有涉及客观相关的差异和不同增强的空间失调的风险。在本文中,我们提出了一种新的学习方法(LEWEL),以自适应地聚合特征的空间信息,使投影嵌入能够精确对齐,从而更好地指导特征学习。具体地说,我们将SSL中的投影头重新解释为每像素的投影,并通过这个共享权重的投影头从原始特征中预测一组空间对齐映射。因此,通过根据这些对齐图对特征进行空间加权聚合,得到对齐嵌入谱。由于这种自适应对齐,我们观察到实质性改善图像级预测和密集预测同时: LEWEL改进MoCov2[15]1.6%/1.3%/0.5%/0.4%点,改进1.3%/1.3%/0.7%/0.6%BYOL[14]点,ImageNet线性/半监督分类,Pascal VOC语义分割,和目标检测
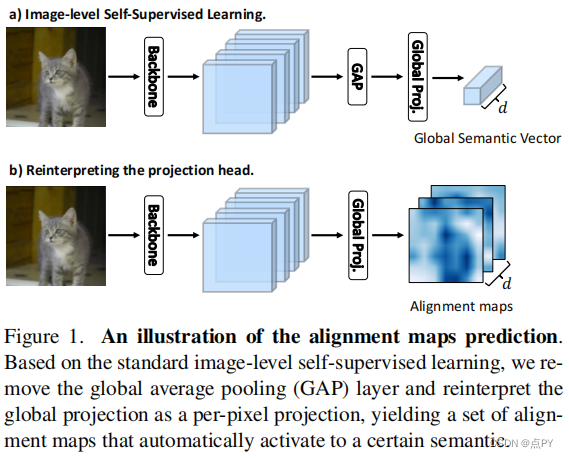
Self-Supervised Learning of Object Parts for Semantic Segmentation(CVPR)
code: https://github.com/MkuuWaUjinga/leopart
摘要: 自监督学习的进步带来了强大的图像表示学习方法。然而,到目前为止,它主要集中在图像层面的学习上。反过来,诸如无监督图像分割等任务并没有从这一趋势中受益,因为它们需要空间多样化的表示。然而,学习密集的表示是具有挑战性的,因为在无监督的上下文中,目前还不清楚如何指导模型来学习对应于各种潜在对象类别的表示。在本文中,我们认为对象部分的自监督学习是解决这个问题的一个方法。对象部分是可推广的:它们是独立于对象定义的先验部分,但可以分组形成后验对象。为此,我们利用最近提出的视觉转换器关注对象的能力,并将其与空间密集的聚类任务相结合,以微调空间标记。我们的方法在三个语义分割基准上比最先进的多出了17%-3%,表明我们的表示在各种对象定义下是通用的。最后,我们将其扩展到完全无监督的分割——即使在测试时也完全避免使用标签信息——并证明了一种基于社区检测自动合并已发现的对象部分的简单方法产生了实质性的收益。
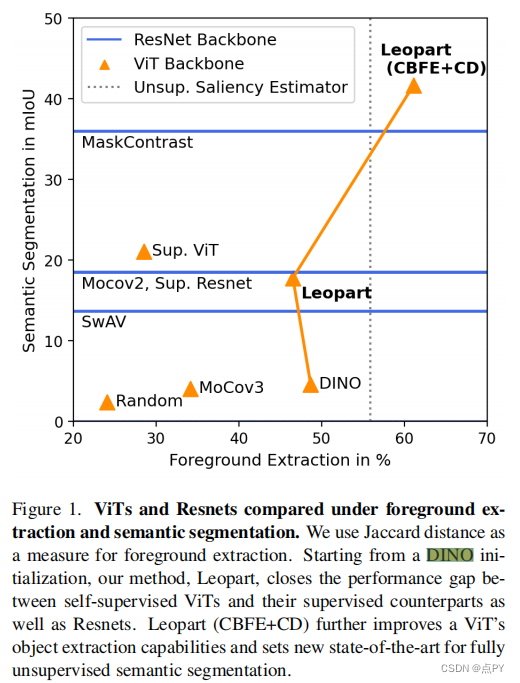
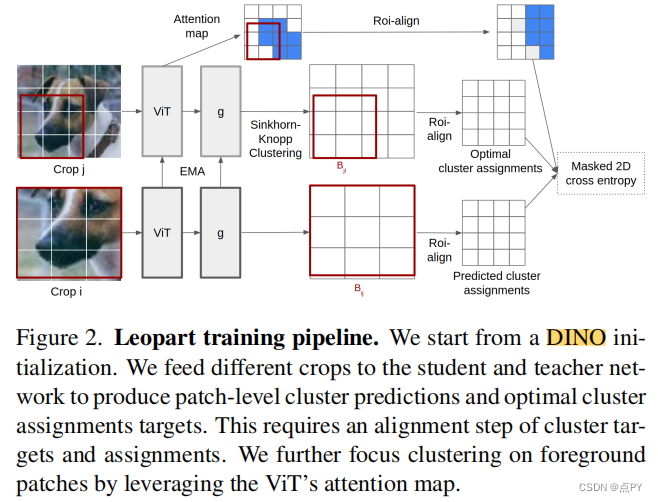
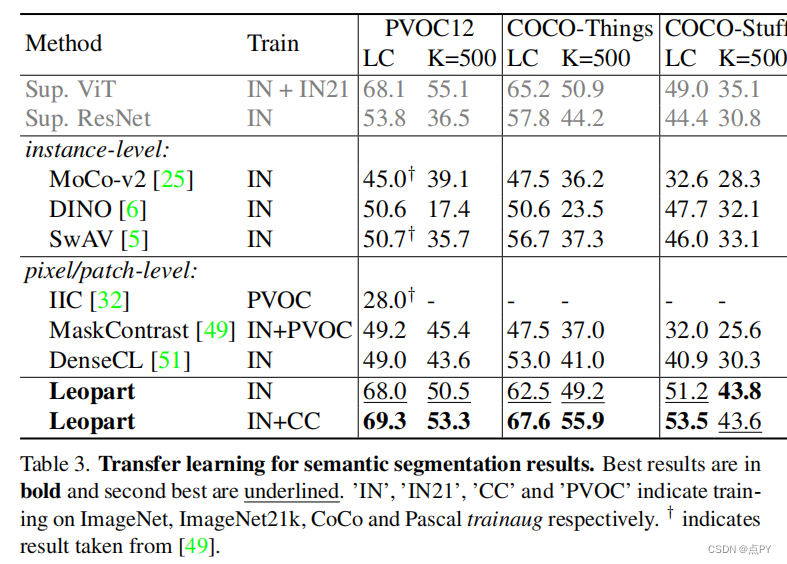
2023
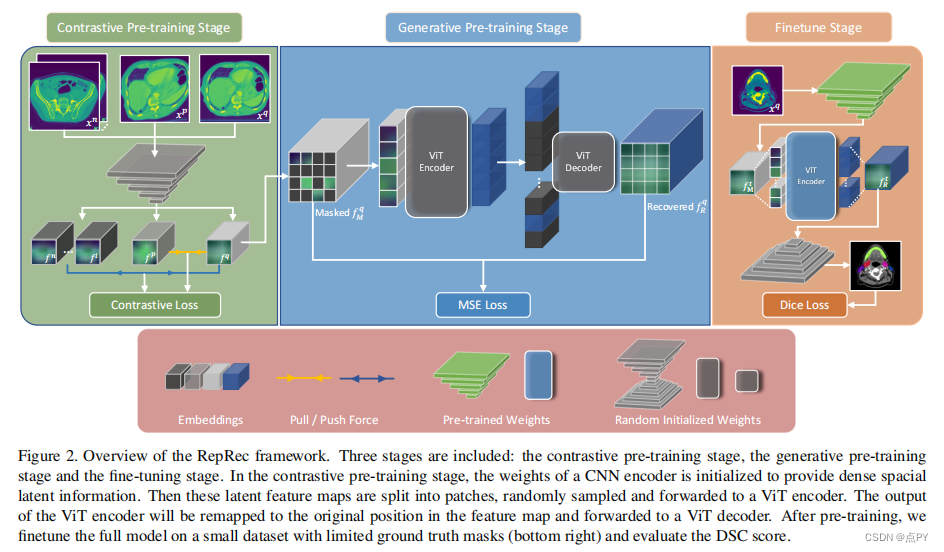
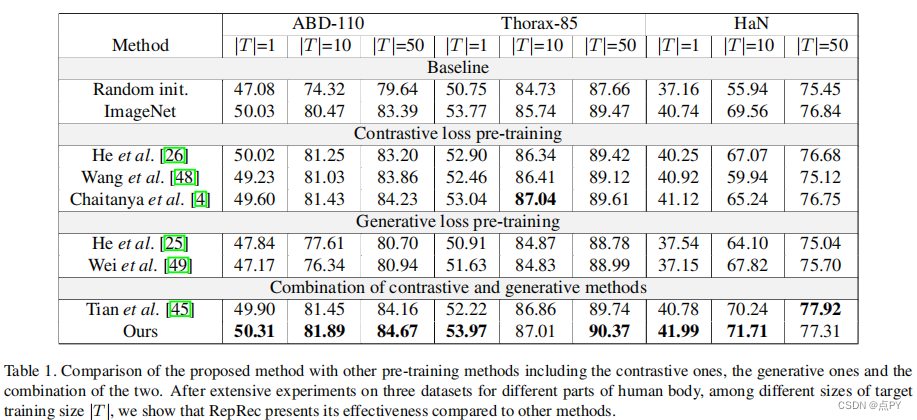
Representation Recovering for Self-Supervised Pre-training on Medical Images
自我监督学习的进步引起了人们对从未标记图像中提取有效视觉表征的技术的注意。对比学习(CL)训练了一个模型,通过生成不同的视图来提取一致的特征。最近蒙面自动编码器(MAE)最近的成功突出了生成建模在自监督学习中的好处。生成方法将输入编码到一个紧凑的嵌入中,并增强了模型恢复原始输入的能力。然而,在我们的实验中,我们发现普通MAE主要恢复粗糙的高级语义信息,在恢复详细的低级信息方面存在不足。我们表明,在多器官分割等密集的下游预测任务中,直接应用MAE并不理想。在这里,我们提出了RepRec,一个混合的视觉表示学习框架,用于在大规模的无标记医疗数据集上进行自我监督的预训练,它同时利用了对比建模和生成建模。为了解决MAE遇到的上述困境,对卷积编码器进行预训练,以对比的方式提供低层次的特征信息;变压器编码器经过预训练,以生成的方式产生高级语义依赖性——通过从卷积编码器中恢复掩码表示。在三个多器官分割数据集上的大量实验表明,我们的方法优于目前最先进的方法。
object detection
2021
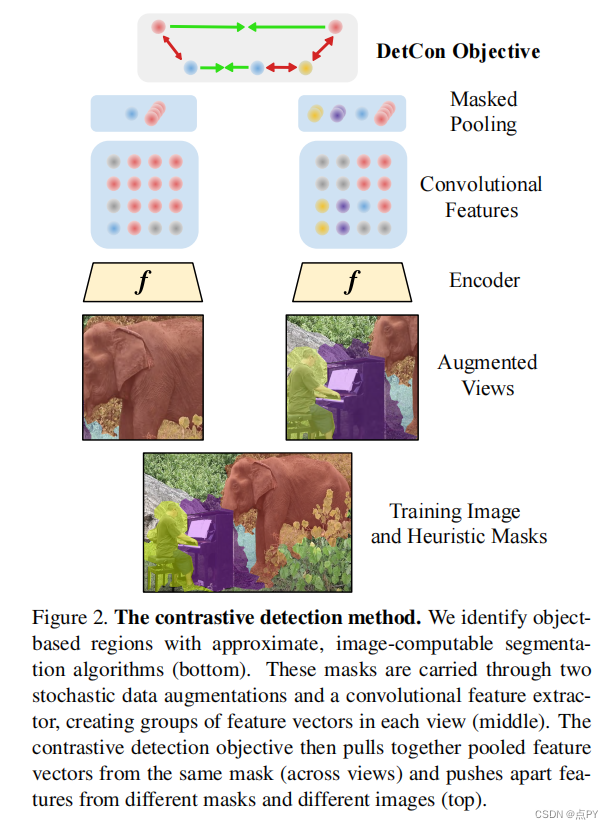
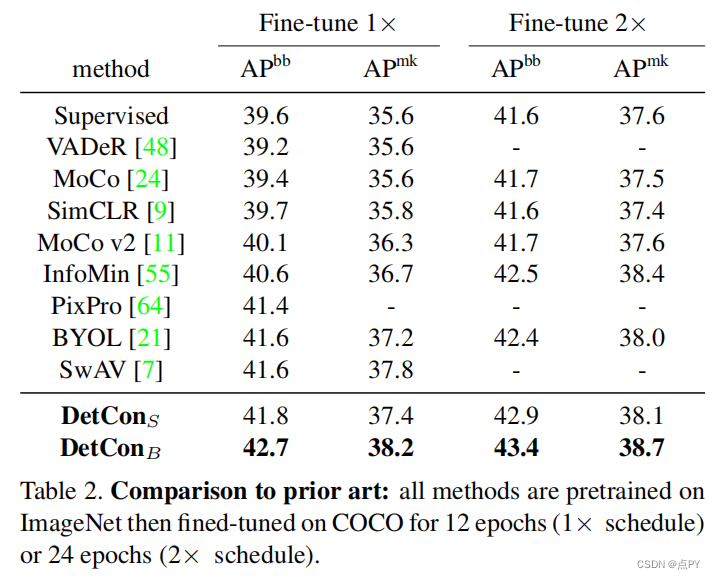
Efficient Visual Pretraining with Contrastive Detection
code: https://paperswithcode.com/paper/efficient-visual-pretraining-with-contrastive
摘要: 自我监督的预训练已被证明可以产生迁移学习的强大表征。然而,这些性能的提高要付出了巨大的计算代价,因为最先进的方法需要比监督预训练更多一个数量级的计算。我们通过引入一种新的自我监督目标,对比检测来解决这一计算瓶颈,它可以跨增强识别对象级特征。这个目标为每张图像提取丰富的学习信号,从而在各种下游任务上获得最先进的传输精度,同时需要少10⇥的预训练。特别是,我们最强的Image网络预训练模型与SEER表现相当,SEER是迄今为止最大的自我监督系统之一,它使用了1000个预训练数据。最后,我们的目标⇥无缝地处理更复杂图像的预训练,如COCO,缩小了从COCO到pascal的监督转移学习的差距。
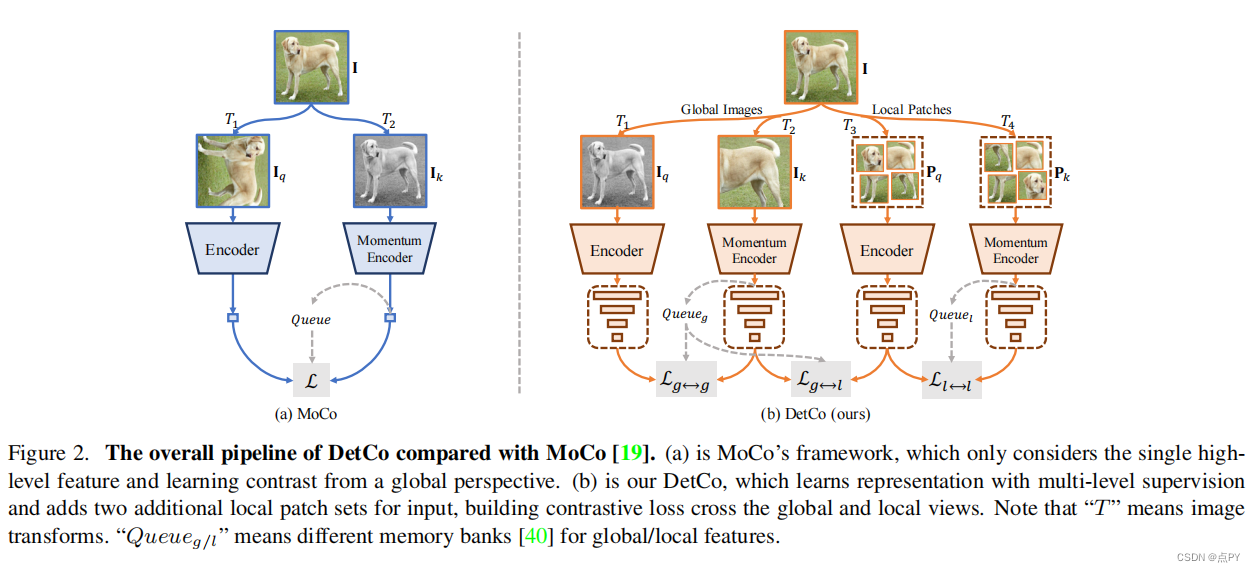
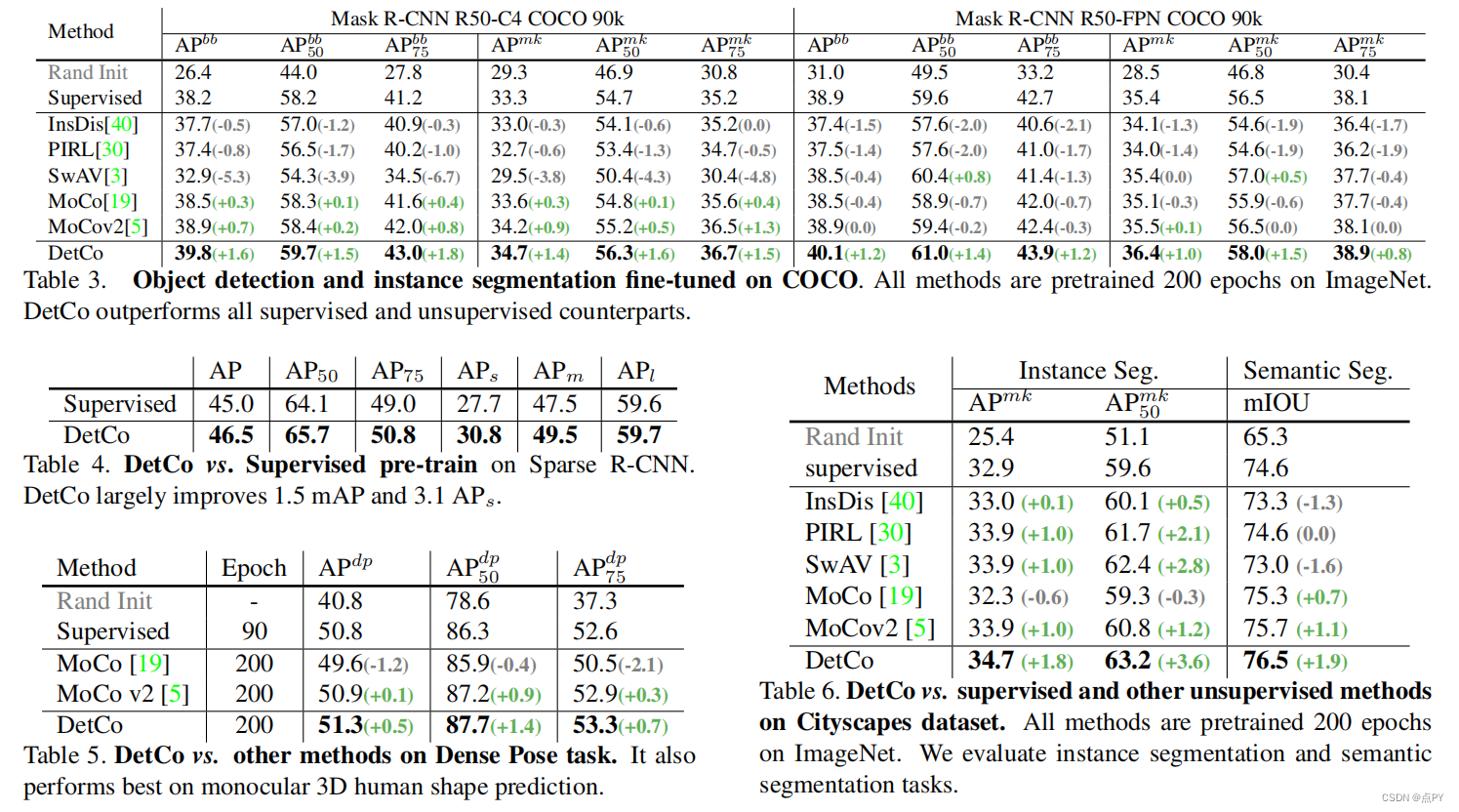
DetCo: Unsupervised Contrastive Learning for Object Detection
code: https://paperswithcode.com/paper/detco-unsupervised-contrastive-learning-for
摘要:我们提出了DetCo,一种简单而有效的自我监督的目标检测方法。无监督的预训练方法最近被设计用于目标检测,但它们通常在图像分类方面存在缺陷,或相反。与它们不同的是,DetCo在下游实例级密集预测任务上传输得很好,同时保持了具有竞争力的图像级分类精度。其优点来自于(1)的多层次监督到中间表示,以及全局图像和局部斑块之间的(2)对比学习。这两种设计在特征金字塔的每个层次上都便于区分和一致的全局和局部表示,同时提高了检测和分类。
对VOC、COCO、城市景观和ImageNet的大量实验表明,DetCo不仅在一系列二维和三维实例级检测任务上优于最近的方法,而且在图像分类上也具有竞争力。例如,在ImageNet分类上,DetCo的准确率分别比督察员和DenseCL高6.9%和5.0%,这是两个当代为目标检测而设计的作品。此外,在COCO检测上,DetCo比使用MaskR-CNNC4的SwAV好6.9 AP。值得注意的是,DetCo在很大程度上增强了最近的强探测器稀疏R-CNN,从45.0 AP提高到46.5AP(+1.5AP),在COCO上建立了一个新的SOTA。
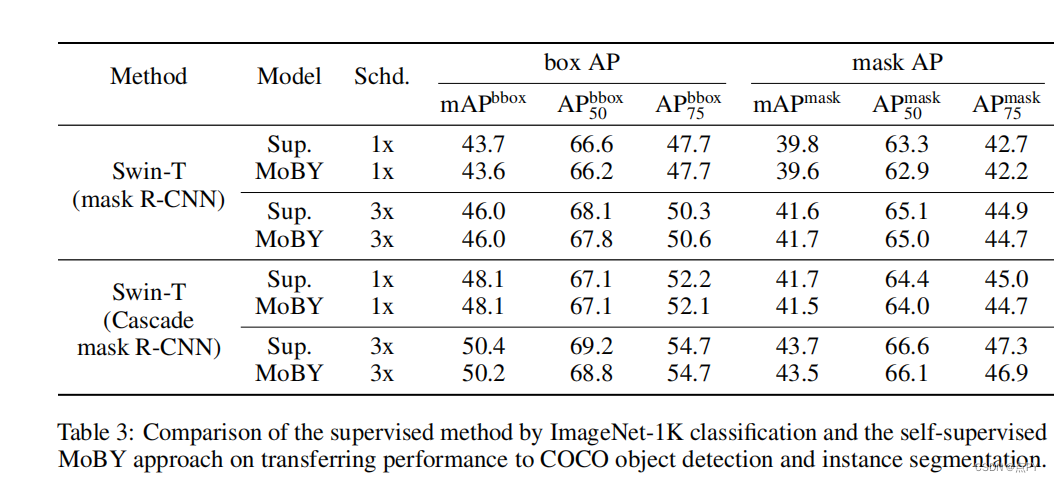
Self-Supervised Learning with Swin Transformers
code: https://github.com/SwinTransformer/Transformer-SSL
摘要: 我们正在见证在计算机视觉中从CNN到Transformers的建模转变。在这项工作中,我们提出了一种名为MoBY的自监督学习方法,以视觉Transformers作为其主干架构。该方法基本上没有新的发明,由MoCo v2和BYOL相结合,在ImageNet-1K线性评估上实现了相当高的精度:通过300epoch的训练,使用DeiT-S和Swin-T的前1精度分别为72.8%和75.0%。其性能略好于MoCo v3和DINO最近的作品,后者采用DeiT作为骨干,但技巧要轻得多。更重要的是,通用双变压器骨干使我们也评估学习表示下游任务如对象检测和语义分割,与最近一些方法建立在生活/DeiT只报告线性评估结果ImageNet-1K由于生活/生活不驯服这些密集的预测任务。我们希望我们的结果可以促进更全面的评估自我监督学习方法设计的变压器架构。
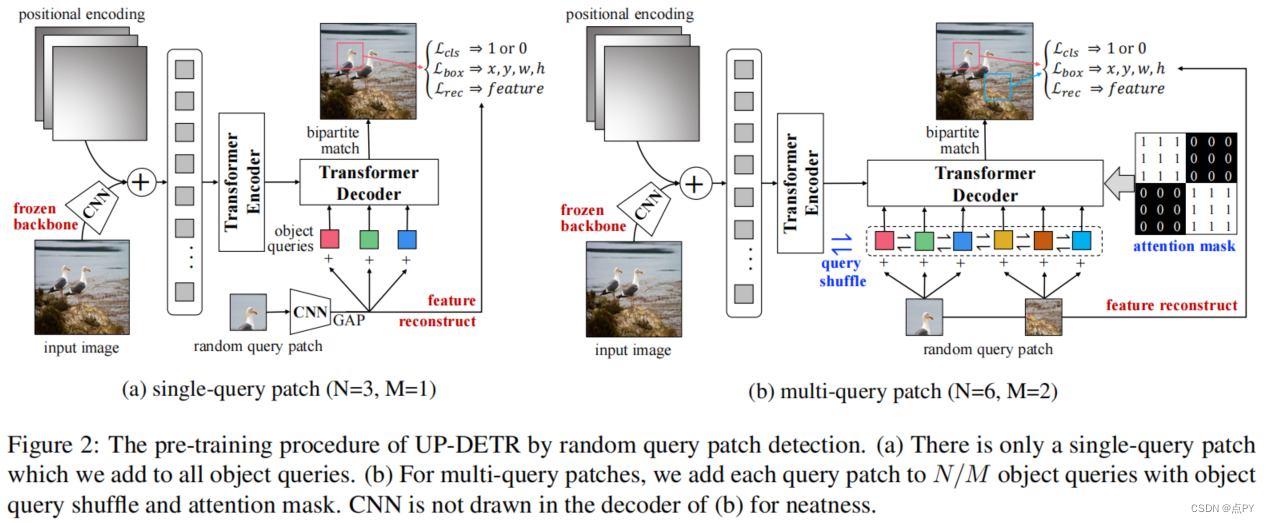
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
code: https://github.com/dddzg/up-detr
摘要:使用transformer(DETR)的目标检测通过transformer编解码器架构达到了与faster R-CNN的竞争性能。受预训练变压器在自然语言处理中的巨大成功的启发,我们提出了一个名为随机查询块检测的借口任务,以随机预训练DETR(UP-DETR)进行目标检测。具体来说,我们从给定的图像中随机裁剪补丁,然后将它们作为查询提供给解码器。该模型经过预先训练,可以从原始图像中检测这些查询补丁。在预训练过程中,我们解决了两个关键问题:多任务学习和多查询定位。(1)为了在借口任务中权衡分类和定位偏好,我们冻结了CNN主干,并提出了一个与补丁检测联合优化的补丁特征重建分支。(2)为了实现多查询定位,我们引入了单查询补丁的UP-DETR,并将其扩展到具有对象查询洗牌和注意掩码的多查询补丁。在我们的实验中,UP-DETR显著提高了DETR的性能,在目标检测、一次性检测和全景分割方面的收敛速度更快,提高了更高的平均精度。
论文的贡献:
-
多任务学习:目标检测是目标分类与定位的耦合。为了避免查询补丁检测对分类特征的破坏,我们引入了冻结的预训练骨干网和补丁特征重构,以保持transformer的特征识别能力。
-
多查询本地化:不同的对象查询关注于不同的位置区域和方框大小。为了说明这个特性,我们提出了一个简单的单查询预训练,并将其扩展到一个多查询版本。对于多查询补丁,我们设计了对象查询洗牌和注意掩码来解决查询补丁与对象查询之间的分配问题。
2022
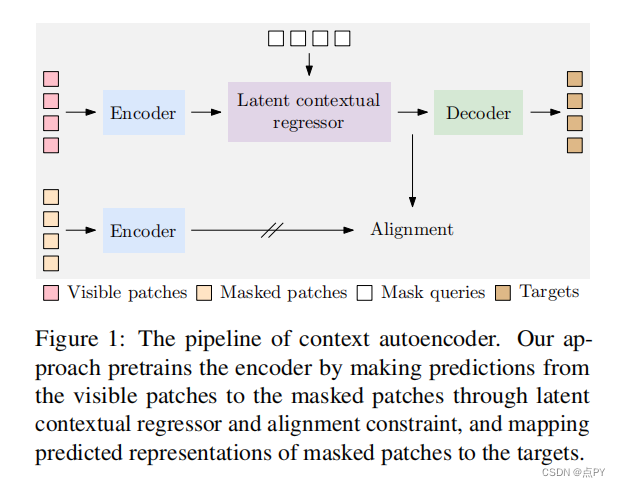
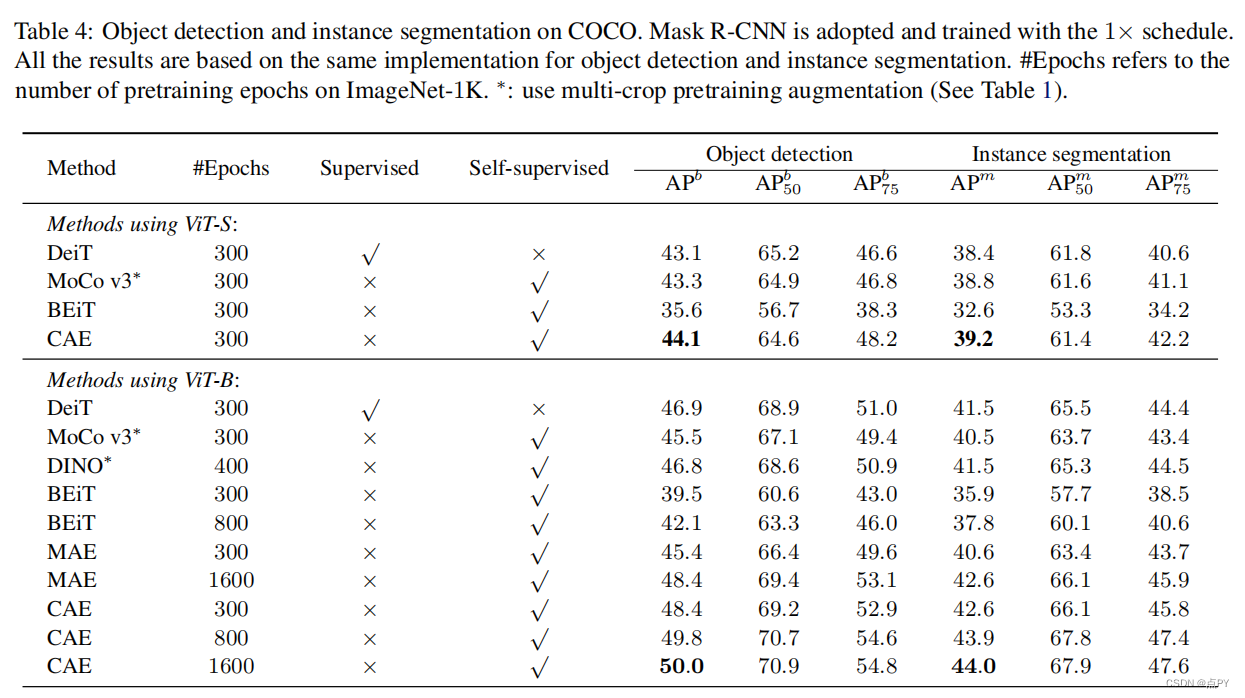
Context Autoencoder for Self-Supervised Representation Learning
code: https://paperswithcode.com/paper/context-autoencoder-for-self-supervised
摘要:我们提出了一种新的掩蔽图像建模(MIM)方法,上下文自动编码器(CAE),用于自我监督的表示预训练。其目标是通过解决代理任务来预先训练一个编码器:从图像中可见的补丁中估计掩蔽补丁。我们的方法首先将可见的补丁输入编码器,提取表示形式。然后,我们在编码表示空间中从可见补丁到掩蔽补丁进行预测。我们引入了一个对齐约束,鼓励从可见补丁的编码表示中预测出的掩蔽补丁的表示,与从编码器计算出的掩蔽补丁表示对齐。换句话说,预测的表示被期望位于编码的表示空间中,这在经验上显示了表示学习的好处。最后,通过解码器将预测的掩码补丁表示映射到代理任务的目标上。
SELF-SUPERVISED TRANSFORMERS FOR UNSUPERVISED OBJECT DISCOVERY USING NORMALIZED CUT
code: https://paperswithcode.com/paper/self-supervised-transformers-for-unsupervised
摘要: 使用自蒸馏损失(DINO)进行自我监督训练的变压器已经被证明可以产生突出突出的前景物体的注意力地图。在本文中,我们展示了一种基于图的方法,利用自监督变压器特征从图像中发现一个对象。视觉标记被视为加权图中的节点,其边表示基于标记相似性的连通性得分。然后,可以使用标准化的图形切割对前景对象进行分割,以对自相似区域进行分组。我们利用广义特征分解的谱聚类方法解决了图切割问题,并证明了第二小特征向量提供了一个切割解,因为它的绝对值表示一个标记属于前景对象的可能性。
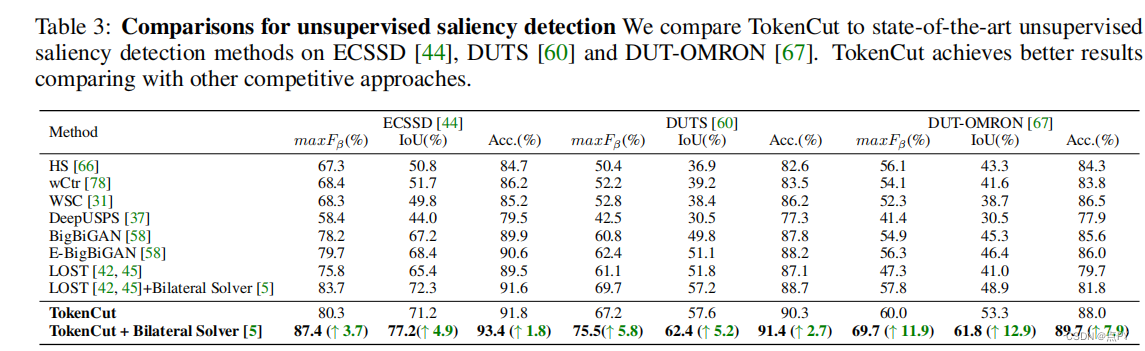
尽管它很简单,但这种方法显著提高了无监督对象发现的性能:我们在VOC07、VOC12和COCO20K上分别提高了6.9%、8.1%和8.1%。通过添加第二级类不可知检测器(CAD),可以进一步提高性能。我们提出的方法可以很容易地推广到无监督显著性检测和弱监督目标检测。对于无监督显著性检测,我们在ECSSD、DUTS、DUT-OMRON上的改进率分别为4.9%、5.2%和12.9%。对于弱监督目标检测,我们在CUB和ImageNet上实现了竞争性能。
论文的贡献:
- 提出了一种基于自监督视觉变压器的无监督的简单有效的图像目标发现方法。当在多个数据集上进行测试时,该方法显著优于现有的无监督对象发现方法;
- 我们将该方法扩展到弱监督目标检测,并证明了该简单的方法可以实现竞争性能;
- 我们还证明了该方法可以用于无监督显著性检测。结果表明,TokenCut显著提高了之前在多个数据集上的最先进的性能
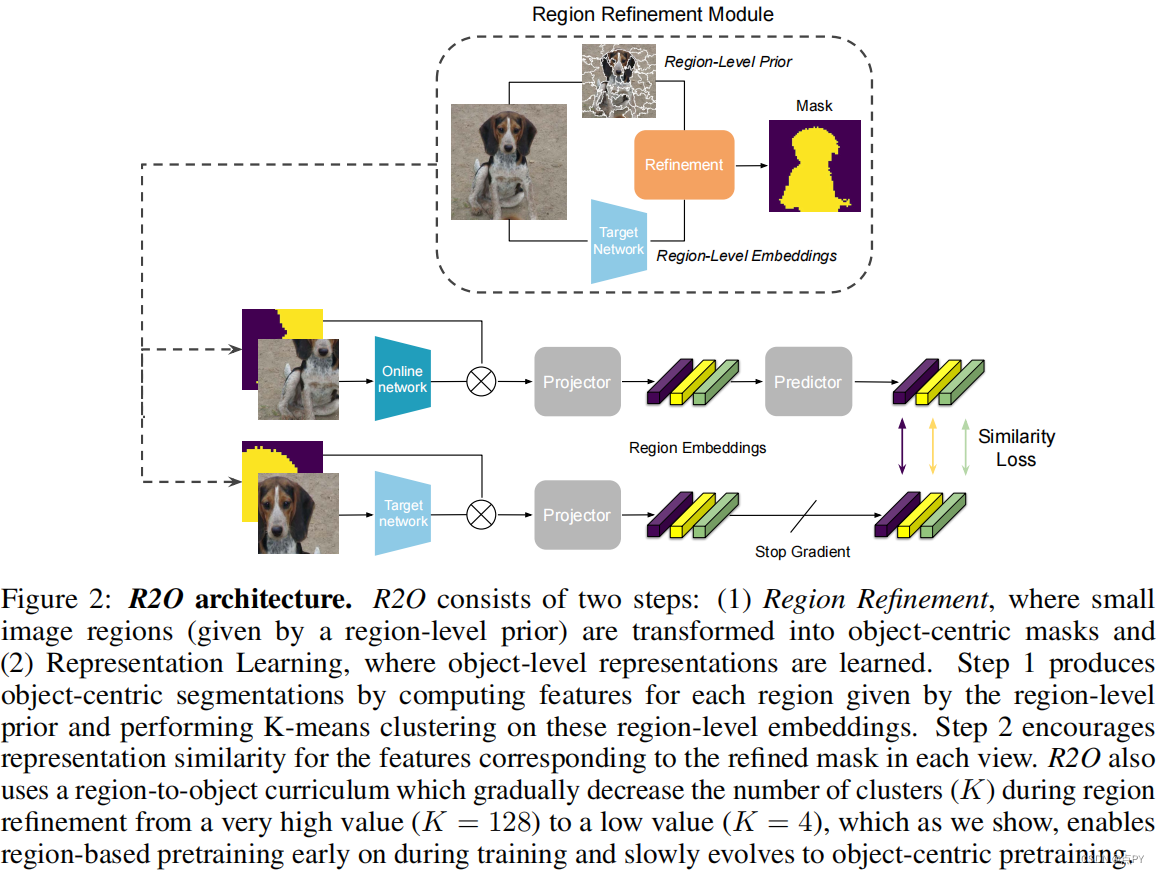
Refine and Represent: Region-to-Object Representation Learning
code: https://paperswithcode.com/paper/refine-and-represent-region-to-object
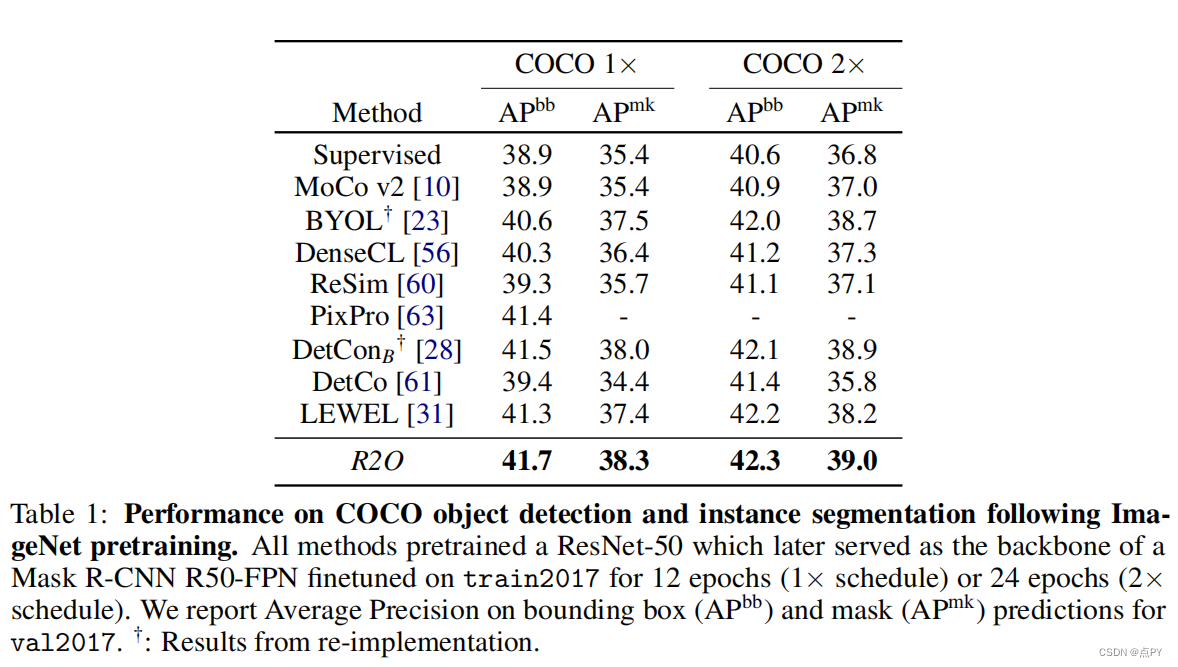
摘要: 最近在自我监督学习方面的研究表明,通过对以对象为中心或基于区域的对应目标进行预训练,它们在场景级密集预测任务上具有很强的表现。在本文中,我们提出了区域到对象的表示学习(R2O),它统一了基于区域的和以对象为中心的预训练。R2O的操作方法是训练一个编码器,动态地将基于区域的片段细化为以对象为中心的掩模,然后联合学习掩模内内容的表示。R2O使用区域细化模块将使用区域级先验生成的小图像区域分组为更大的区域,这些区域通过聚类区域级特征倾向于对应于对象的区域。
随着预训练的进展,R2O遵循一个区域到对象的课程,鼓励在早期学习区域水平的特征,并逐步推进训练以对象为中心的表征。使用R2O学习的表示在帕斯卡VOC(+0.7 mIOU)和城市景观(+0.4 mIOU)的语义分割和MS COCO(+0.3 APmk)的实例分割方面取得了最先进的性能。此外,在ImageNet上进行预训练后,R2O预训练模型能够在没有任何进一步训练的情况下超越加州理工大学-ucsd鸟类200-2011数据集(+2.9 mIoU)上的现有的无监督对象分割。
论文的贡献:
- 我们提出了R2O,它通过训练一个编码器来统一基于区域和中心对象的实例识别预训练,动态地将基于区域的片段细化为基于中心对象的掩模,然后联合学习掩模内内容的表示。
- 我们为R2O引入了一个区域到对象的预训练课程,它首先训练与简单图像区域对应的局部特征,例如共享相似颜色值的相邻像素,然后逐步推进学习以对象为中心的特征。
- R2O预训练提高了MS COCO(+0.3 APmk)目标检测和实例分割等任务的传输性能,超过了帕斯卡VOC(+0.7 mIOU)和城市景观(+0.4 mIOU)语义分割方法。R2O进一步提高了+2.9 mIoU在加州理工学院-ucsd鸟类200-200-20011)上最先进的无监督分割性能,尽管没有在CUB-200-2011上进行微调。
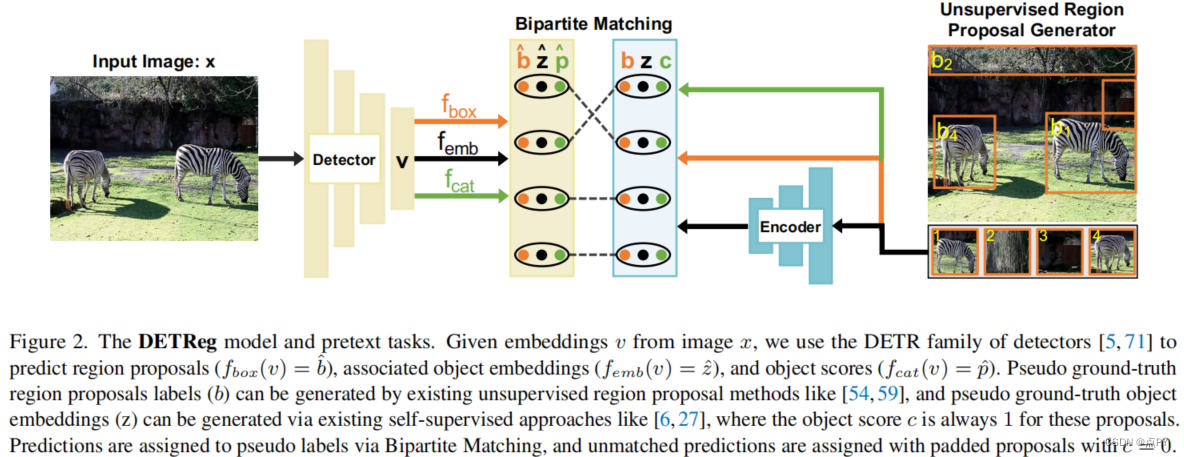
DETReg: Unsupervised Pretraining with Region Priors for Object Detection
code: https://paperswithcode.com/paper/detreg-unsupervised-pretraining-with-region
摘要: 最近的目标检测的自监督预训练方法主要集中在对目标检测器的主干进行预训练上,而忽略了检测体系结构的关键部分。相反,我们引入了DETReg,这是一种新的自监督方法,可以对整个对象检测网络进行预训练,包括对象定位和嵌入组件。在预训练过程中,DETReg预测对象定位,以匹配来自无监督区域建议生成器的定位,并同时将相应的特征嵌入与来自自监督图像编码器的嵌入对齐。我们使用DETR系列探测器实现了DETReg,并表明,在确定COCO、帕斯卡VOC和空客船舶基准时,它优于竞争基线。

UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
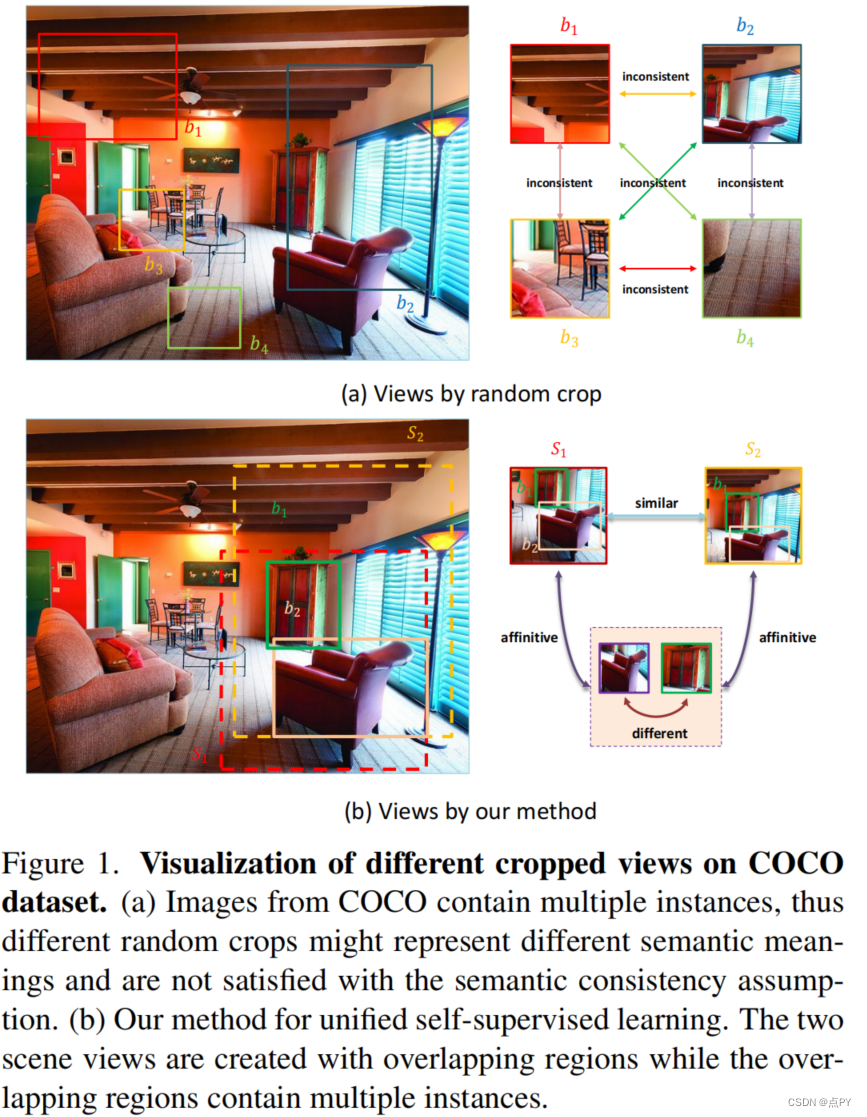
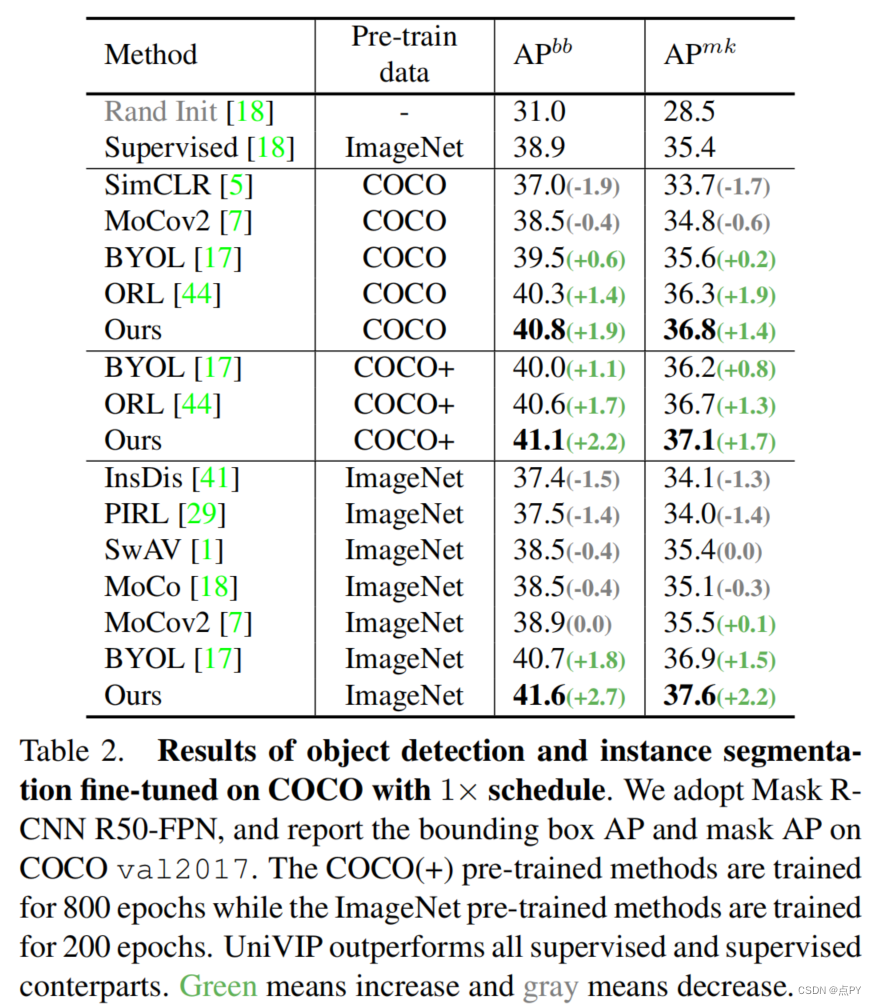
摘要: 自监督学习(SSL)有希望利用大量的未标记数据。然而,流行的SSL方法的成功限制了像ImageNet这样的单中心对象图像,忽略了场景和实例之间的相关性,以及场景中实例的语义差异。为了解决上述问题,我们提出了一种统一的自监督视觉预训练(UniVIP),这是一种新的自监督框架,用于在单中心对象或非标志性数据集上学习多功能视觉表示。该框架考虑了三个层面的表示学习: 1)场景-场景的相似性,2)场景-实例的相关性,3)实例-实例的区分。在学习过程中,我们采用最优传输算法来自动度量实例的判别性。大量实验表明,在非标志性COCO上进行预训练的UniVIP在图像分类、半监督学习、目标检测和分割等各种下游任务上都取得了最先进的传输性能。此外,我们的方法还可以利用ImageNet等单中心对象数据集,在线性探测中比相同的预训练时代比BYOL好2.5%,在COCO数据集上超过现有的自监督目标检测方法,证明了其通用性和潜力。
2023
Evaluating Self-supervised Transfer Performance in Grape Detection
摘要: 计算机视觉的进步为精密农业领域带来了良好的研究和应用。特别是,深度学习迅速提高了目标检测和分割的技术水平,这两者在作物监测和产量预测中都被证明是至关重要的。在大多数目标检测问题中,迁移学习是将深度学习系统应用于下游任务的既定范例。这在农业视觉应用程序中尤其重要,因为与深度学习系统所需的巨大需求相比,可用的数据相对稀缺。自监督学习的最新进展已经产生了预训练方法,以接近监督预训练在各种下游任务上的转移性能。为了证明自监督学习在农业中的影响,本文评估了一种自监督方法BYOL对葡萄聚类检测的迁移性能。通过比较BYOL和在更快的R-CNN架构上的监督预训练,这项工作证明了自我监督学习在农业应用中与其他监督预训练方法具有竞争力,显示了它在推进精确农业更准确和稳健的解决方案方面的前景。

Remote sensing
2021
Self-Supervised Learning of Remote Sensing Scene Representations Using Contrastive Multiview Coding
code: https://paperswithcode.com/paper/self-supervised-learning-of-remote-sensing
摘要: 近年来,自监督学习已成为一种很有前途的无监督表示学习的候选方法。在视觉领域,其应用主要是研究在自然场景中的图像的背景下。然而,它的适用性在遥感和医学等特定领域特别有趣,在这些领域很难获得大量的标记数据。在这项工作中,我们对自监督学习在遥感图像分类中的适用性进行了广泛的分析。我们分析了用于自监督预训练的图像数量和图像域对下游任务性能的影响。结果表明,对于遥感图像分类的下游任务,对遥感图像进行自监督预训练比对自然场景图像进行有监督预训练具有更好的效果。此外,我们还表明,自我监督的预训练可以很容易地扩展到多光谱图像,在我们的下游任务中产生更好的结果。
2022
Embedding Earth: Self-supervised contrastive pre-training for dense land cover classification
code: https://github.com/michaeltrs/deepsatmodels
摘要: 在土地覆盖语义分割的训练机器学习模型中,将用作输入的卫星图像的可用性与支持监督学习的地面真实数据之间形成了鲜明的对比。虽然每天都有数千张新的卫星图像可以免费获得,但获取地面真实数据仍然是一件非常具有挑战性、耗时和昂贵的工作。在本文中,我们提出了一种嵌入地球的自监督对比预训练方法,以利用卫星图像的大可用性来提高下游密集土地覆盖分类任务的性能。在四个国家和两个大洲进行了广泛的实验评估,我们使用用我们提出的方法预先训练过的模型作为监督土地覆盖语义分割的初始化点,并观察到高达25%的绝对mIoU的显著改进。在每一种测试的情况下,我们都优于随机初始化,特别是当地面真实数据稀缺时。通过一系列的消融研究,我们探索了所提出的方法的质量,发现学习的特征可以在不同区域之间推广,这为打开了使用所提出的预训练方案替代地球观测任务随机初始化的可能性。
论文的贡献:
- 我们设计了一个基于像素级的端到端自监督视觉预训练系统。对土地覆盖语义分割的预训练模型进行微调,我们观察到与我们的基线相比,绝对mIoU显著提高了25%。对于包含相对较少的注释的数据集,其好处尤其明显。
- 通过一系列的消融研究,我们探索了该方法的超参数空间,并得出了关于预训练集的大小和定性特征如何影响下游分割性能的结论。我们发现,通过延长感兴趣周期(POI)或通过感兴趣区域(AOI)来增加预训练集的大小,通常会提高下游的分割性能。
- 我们发现,当在下游分割任务的AOI不同区域的预训练模型进行初始化时,性能没有下降,例如,在不同的国家预训练模型,而在使用注释数据集的相同AOI进行预训练。这一观察结果为一般使用这种预先训练过的模型作为土地覆盖分割任务的初始化点提供了可能性。我们将本研究中使用的预训练模型与复制这里提供的实验的代码一起公开提供。
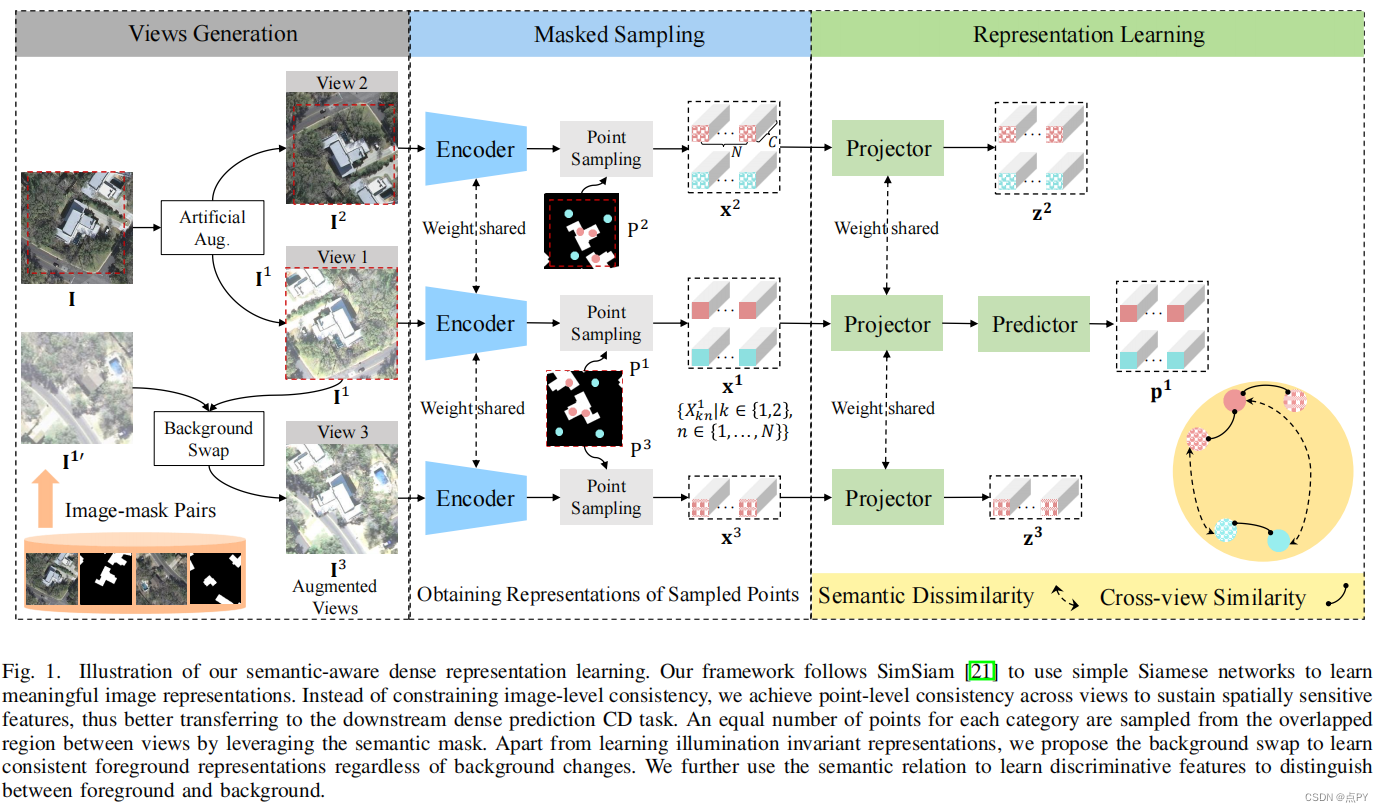
Semantic-aware Dense Representation Learning for Remote Sensing Image Change Detection
code: https://paperswithcode.com/paper/semantic-aware-dense-representation-learning
摘要: 基于深度学习的变化检测(CD)模型的训练严重依赖于标记数据。当代基于迁移学习的方法缓解CD标签不足主要通过ImageNet预训练。最近的一个趋势是使用遥感(RS)数据,通过监督或自监督学习(SSL)来获得域内的表示。在这里,不同于传统的监督预训练,学习从图像到标签的映射,我们以相反的方式利用语义监督。在RS图像中,通常有多个感兴趣的对象(例如,建筑物)分布在不同的位置。我们提出了通过采样多个类平衡点对RS图像CD进行密集的语义感知的预训练。我们不操纵缺乏空间信息的图像级表示,而是限制像素级交叉视图一致性和跨语义识别来学习空间敏感特征,从而有利于下游密集CD。除了学习照明不变特征外,我们还通过使用背景交换的合成视图来实现对不相关背景变化不敏感的一致前景特征。此外,我们还实现了区分性表征来区分前景土地覆盖和其他背景。我们收集了在RS社区免费提供的大规模图像掩模对,用于预训练。在三个CD数据集上进行的大量实验验证了该方法的有效性。我们的方法明显优于ImageNet、领域内监督和几种SSL方法。实证结果表明,我们可以很好地缓解乳糜泻的数据不足。值得注意的是,我们仅使用20%的训练数据比使用100%数据的随机基线获得了竞争结果。定量和定性的结果都表明,我们的预训练模型对下游图像的泛化能力,甚至保留了与训练前数据的域间隙。
论文的贡献:
- 提出了基于密集类平衡采样点的RS图像CD语义感知预训练。我们没有操纵图像级的表示,而是限制了像素级的跨视图一致性和跨语义识别来学习空间敏感的特征,从而有利于下游的密集预测CD任务。
- 我们以对比的方式利用语义监督来增强RS图像中感兴趣对象和背景之间的特征识别能力。除了学习照明不变表示外,我们还提出了一个通过背景合成的虚拟视图来学习对不相关背景变化不敏感的一致前景表示。
- 在三个CD数据集上的大量实验验证了该方法的有效性。我们的性能优于ImageNet的前培训、领域内监督和几种最先进的SSL方法。


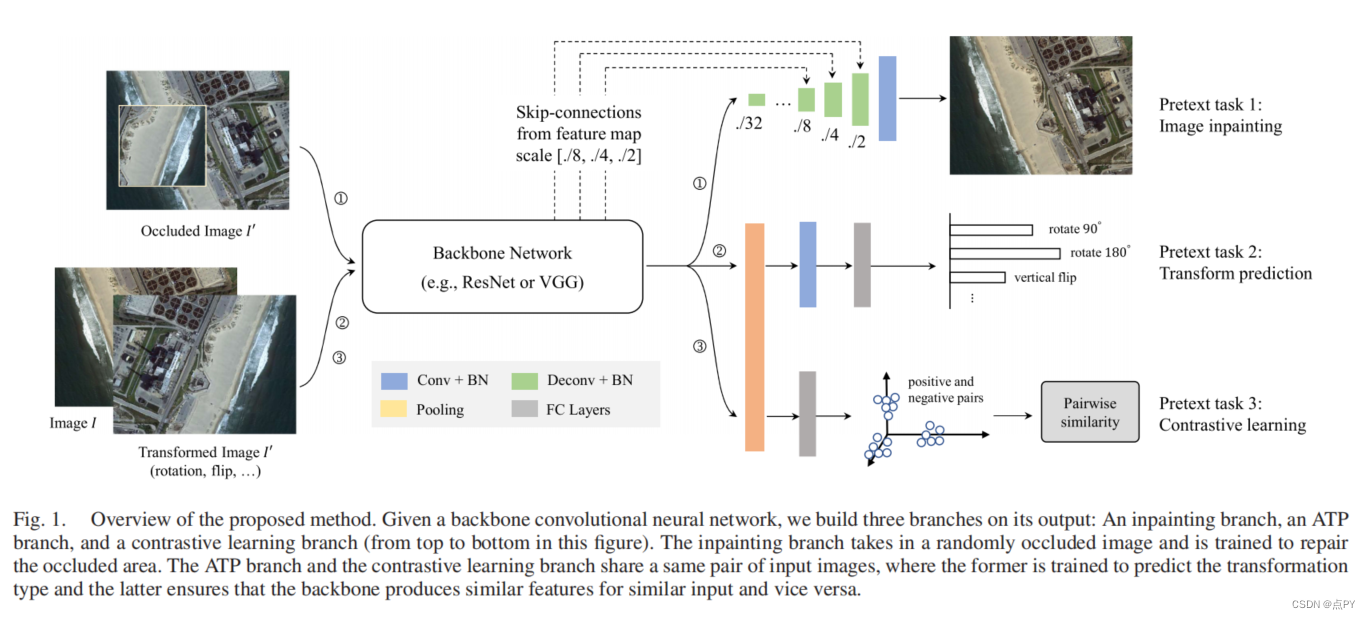
Semantic Segmentation of Remote Sensing Images With Self-Supervised Multitask Representation Learning
code: https://github.com/flyakon/SSLRemoteSensing
摘要: 现有的基于深度学习的遥感图像语义分割方法需要大规模的标记数据集。然而,对分割数据集的注释往往过于耗时和昂贵。为了减轻数据标注的负担,最近出现了自监督表示学习方法。然而,语义分割方法需要同时学习高级和低层次的特征,但现有的自监督表示学习方法大多集中在一个层面上,这影响了遥感图像的语义分割的性能。为了解决这一问题,我们提出了一种自监督的多任务表示学习方法来捕获遥感图像的有效视觉表示。我们设计了三种不同的借口任务和一个三重组合的暹罗网络来同时学习高级和低级的图像特征。该网络可以在没有任何标记数据的情况下进行训练,训练后的模型可以通过标注的分割数据集进行微调。我们在波茨坦、瓦兴根数据集和云/雪检测数据集Levir_CS上进行了实验,验证了该方法的有效性。实验结果表明,该方法可以有效地减少对标记数据集的需求,提高遥感语义分割的性能。与最近最先进的自监督表示学习方法和最常用的初始化方法(如随机初始化和ImageNet预训练)相比,我们提出的方法在大多数实验中都取得了最好的结果,特别是在训练数据较少的情况下。只有10%到50%的标记数据,我们的方法可以实现与随机初始化相比的性能。
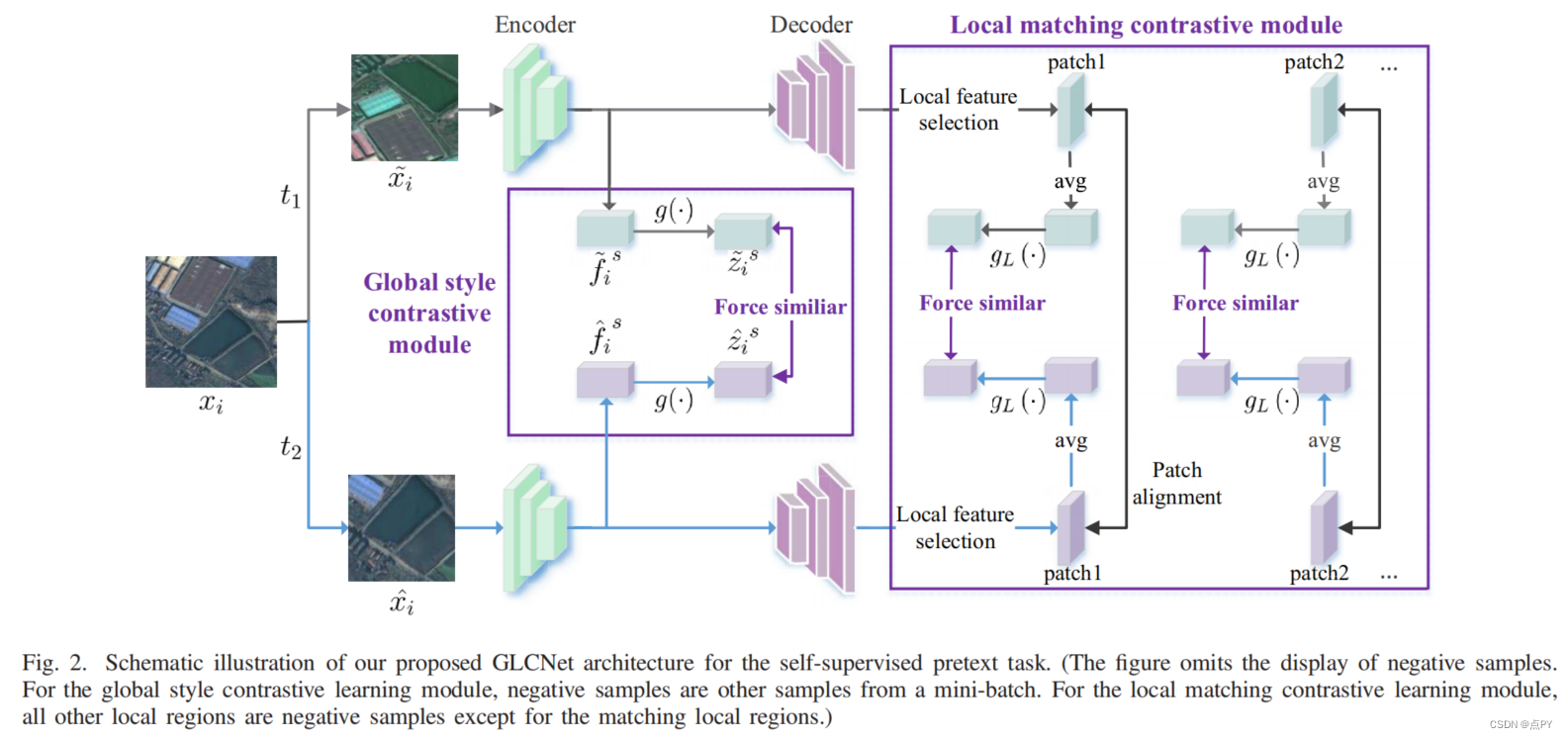
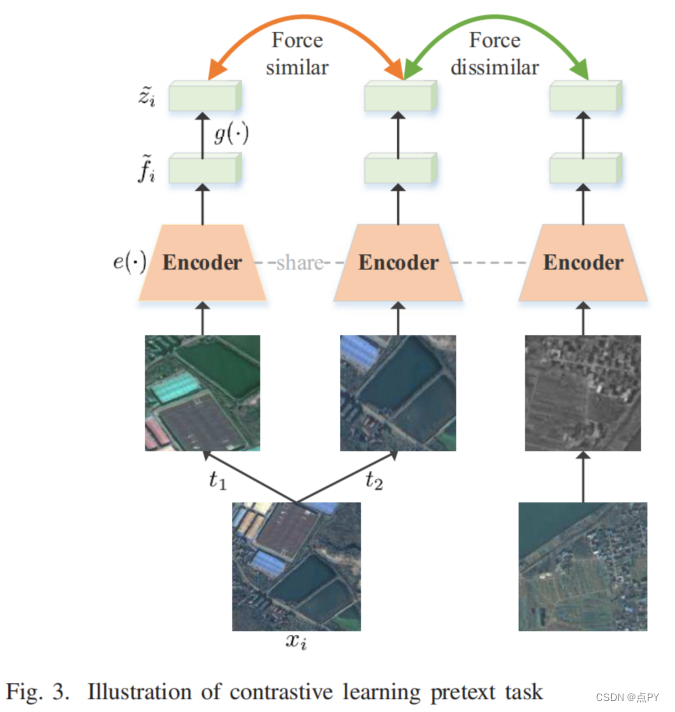
Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images
code: https://github.com/GeoX-Lab/G-RSIM
摘要:近年来,有监督的深度学习在遥感图像(RSI)语义分割方面取得了巨大的成功。然而,语义分割的监督学习需要大量的标记样本,这在遥感领域很难获得。一种新的学习范式,即自监督学习(SSL),可以通过对具有大量未标记图像的一般模型进行预训练,然后在很少标记样本的下游任务中对其进行微调。对比学习是SSL的一种典型的学习一般不变特征的方法。然而,现有的对比学习方法大多是为分类任务而设计的,以获得图像级的表示,而对于需要像素级识别的语义分割任务,这可能是次优的。.因此,我们提出了一种全局风格和局部匹配对比学习GLCNet网络(GLCNet)进行遥感图像语义分割。具体来说,1)使用全局风格对比学习模块来更好地学习图像级表示,因为我们认为风格特征可以更好地表示整体图像特征。2)设计了局部特征匹配对比学习模块来学习局部区域的表示,有利于语义分割。我们评估了四个RSI语义分割数据集,实验结果表明,我们的方法大多优于最先进的自监督方法和ImageNet预训练方法。具体来说,使用来自原始数据集的1%的注释,我们的方法将ISPRS波茨坦数据集上的Kappa提高了6%。此外,当上游任务和下游任务的数据集存在一定差异时,我们的方法优于监督学习方法。我们的研究促进了自我监督学习在RSI语义分割领域的发展。由于SSL可以直接从未标记数据中学习数据的基本特征,这在遥感领域很容易获得,因此这可能对全球制图等任务具有重要意义。

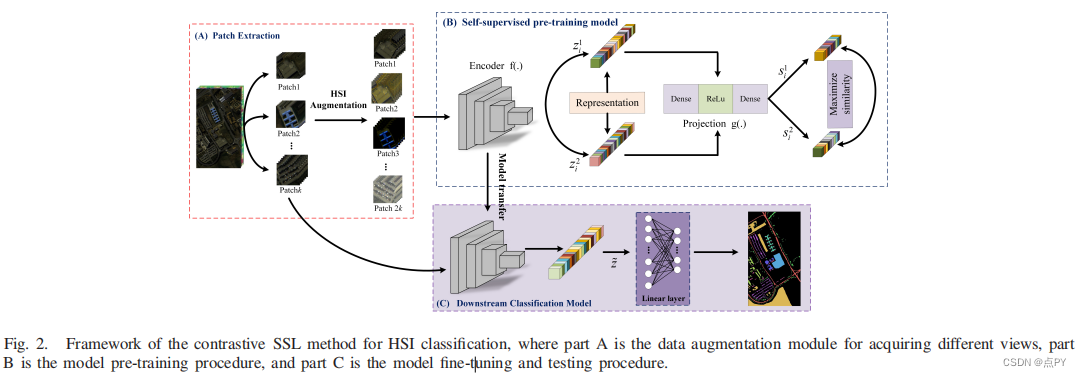
Hyperspectral Image Classification With Contrastive Self-Supervised Learning Under Limited Labeled Samples
摘要: 高光谱图像(HSI)分类是遥感领域一个活跃的研究课题。基于监督学习的方法由于其对充分标记样本的强大特征提取能力,已广泛应用于HSI分类任务的广泛应用。然而,由于标签的高成本或不可靠的视觉解释,实际应用往往有有限的样品与准确的标签。我们引入了一种对比的自监督学习(SSL)算法来实现对标记样本很少的问题的HSI分类。首先,开发了一个新的hsi特定的增强模块来生成样本对。然后,利用基于暹罗网络的对比SSL模型从这些容易获取的样本对中提取特征。最后,利用标记样本对分类模型的参数进行微调,以提高分类性能。在两个广泛使用的HSI数据集上进行了对比自监督算法的测试。实验结果表明,该算法需要少量的标记样本才能获得较好的性能。
Prior Knowledge
2020
Whitening for Self-Supervised Representation Learning
code: https://github.com/htdt/self-supervised
摘要:目前大多数的自我监督表示学习(SSL)方法都是基于对比损失和实例识别任务,其中同一图像实例的增强版本(“正”)与从其他图像中提取的实例(“负”)进行对比。为了使学习有效,应该将许多负对与正对进行比较,这是需要计算的。本文提出了一个基于延迟空间特征白化的SSL的不同方向和一个新的损失函数。白化操作对批样本有“散射”效应,避免了所有样本表示坍缩到一个点的退化解。我们的解决方案不需要非对称网络,而且它在概念上很简单。此外,由于不需要负对,所以我们可以从同一个图像实例中提取多个正对。
2022
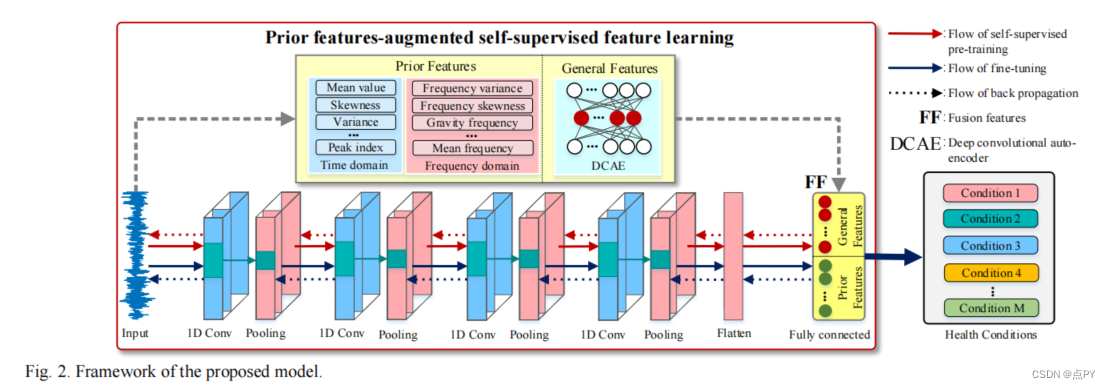
Prior Knowledge-Augmented Self-Supervised Feature Learning for Few-shot Intelligent Fault Diagnosis of Machines
摘要:智能诊断模型有望从大量的监测数据中挖掘机器的健康信息。然而,在工程场景中收集的故障监测数据的规模有限,这导致了少镜头故障诊断是一个有价值的研究点。幸运的是,通过将先前的诊断知识集成到诊断模型中,可以减少所需的训练数据量。受此启发,我们提出了一个用于少镜头故障诊断的先验知识增强自监督特征学习框架。在该框架中,构建了24个信号特征指标,基于现有的诊断知识形成先验特征集。此外,还使用卷积自动编码器来挖掘一般特征,这些特征被认为可能包含先前特征不具备的故障信息。我们设计了一个自监督学习方案来训练诊断模型,使该模型能够同时学习作为代理标签的先验特征和一般特征。因此,该模型有望从有限的监测数据中挖掘出更丰富的特征。通过两个机械故障仿真实验,验证了该框架的有效性。从先验诊断知识的角度出发,所提出的框架为机器的少镜头智能诊断问题提供了一个新的视角。
Interaction of A Priori Anatomic Knowledge with Self-Supervised Contrastive Learning in Cardiac Magnetic Resonance Imaging
摘要:在心脏磁共振成像(CMR)上训练深度学习模型可能是一个挑战,因为专家生成的标签数量较少,而且数据源具有固有的复杂性。自我监督对比学习(SSCL)最近已被证明可以提高在一些医学成像任务中的性能。然而,与周围的假组织相比,预先训练的表征在多大程度上反映了主要的兴趣器官。在这项工作中,我们评估了将先验解剖学知识纳入SSCL训练范式的最佳方法。具体来说,我们评估使用分割网络在CMR图像中明确地局部化心脏,然后在多个诊断任务中进行SSCL预训练。我们发现,使用先验的解剖学知识可以大大提高下游的诊断性能。此外,与端到端训练和ImageNet预训练网络相比,使用域内数据的SSCL预训练通常可以提高下游性能和更像人的显著性。然而,在训练前引入解剖学知识一般没有显著影响。
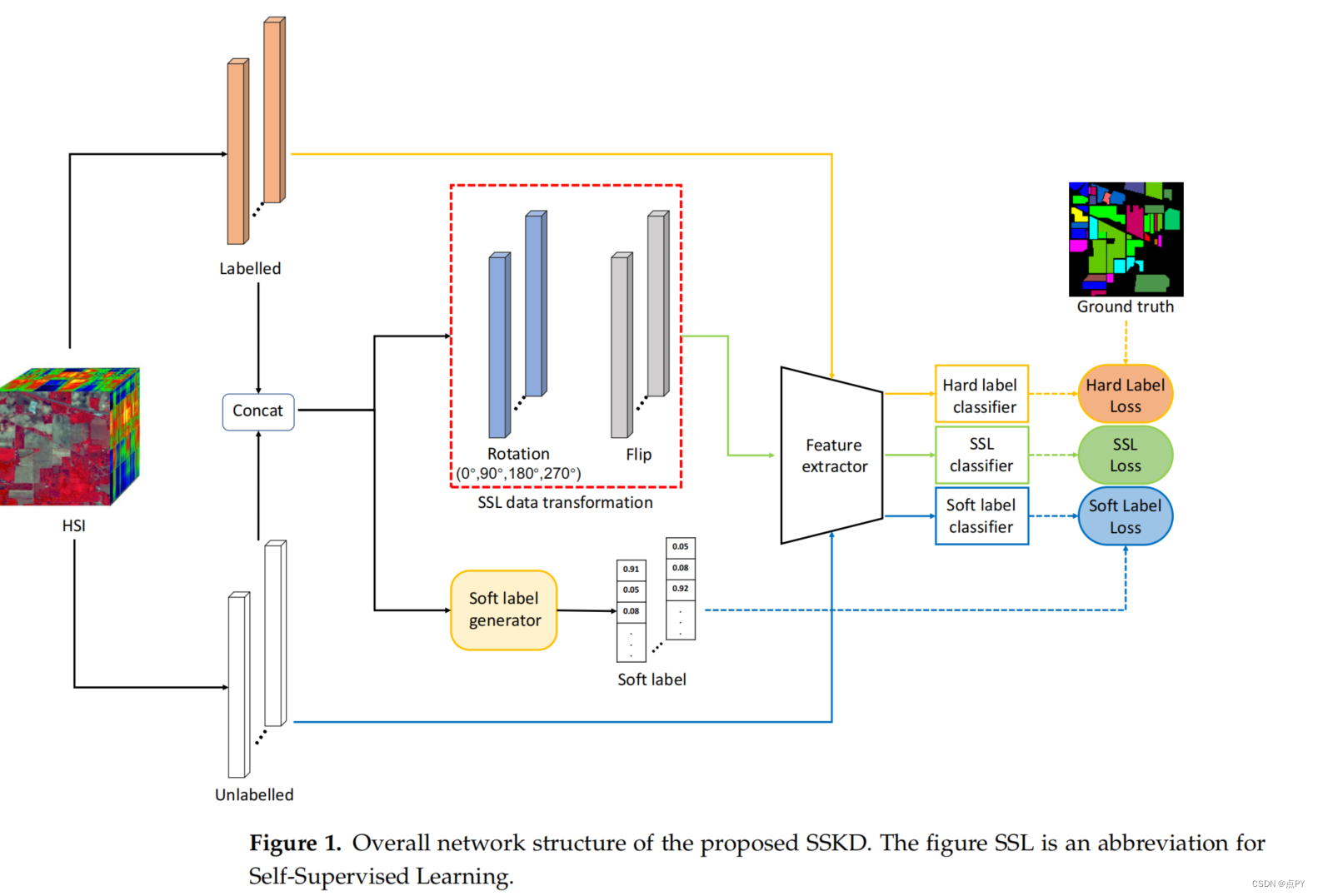
A Novel Knowledge Distillation Method for Self-Supervised Hyperspectral Image Classification
摘要: 利用深度学习对只有少数标记样本的高光谱图像(HSI)进行分类是一个挑战。近年来,基于软标签生成的知识蒸馏方法被用于解决样本数量有限的分类问题。与普通标签不同,软标签被认为是一个样本属于某一类别的概率,因此为了分类,可以提供更多的信息。现有的HSI分类的软标签生成方法不能充分利用现有的未标记样本的信息。为了解决这一问题,我们提出了一种新的自监督学习方法与知识蒸馏的HSI分类,称为SSKD。其主要动机是通过自适应地生成未标记样本的软标签,利用更有价值的信息进行分类。首先,通过同时考虑空间距离和光谱距离,对所有未标记和标记的样本进行相似度识别。然后,对生成的数据进行自适应最近邻匹配策略。最后,对该类别进行概率判断,生成软标签。与现有的方法相比,我们的方法在三个公开数据集上的分类准确率分别提高了4.88%、7.09%和4.96%。
综述
2021
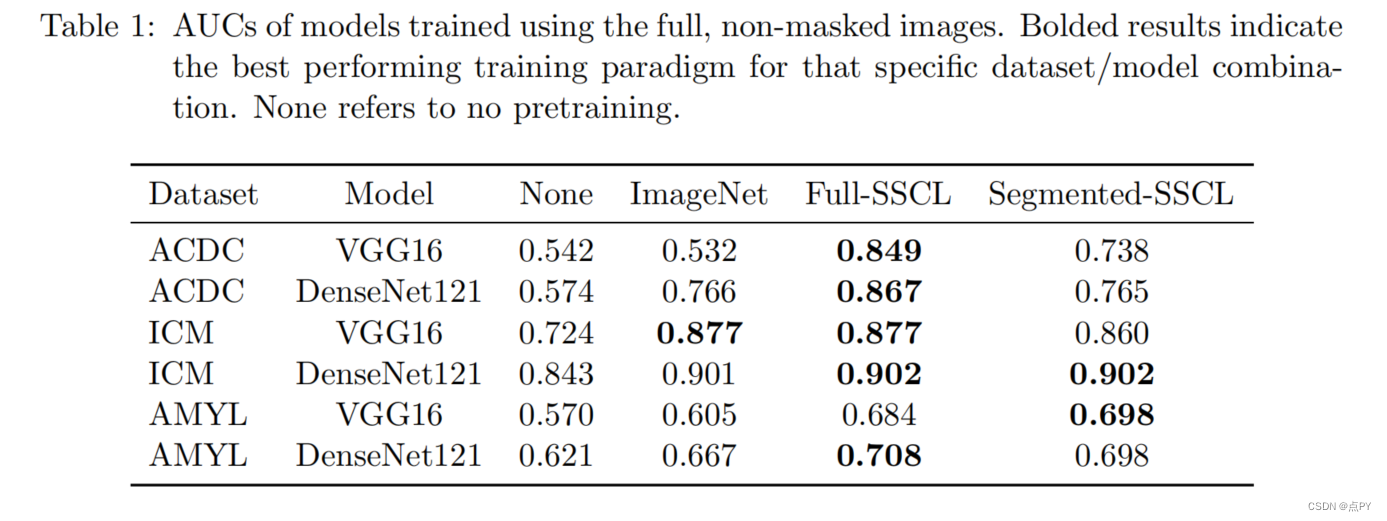
How Well Do Self-Supervised Models Transfer?
摘要: 自我监督视觉表征学习最近取得了巨大的进展,但没有大规模的评价来比较目前许多可用的模型。我们评估了13个顶级自监督模型在40个下游任务上的传输性能,包括多镜头和少镜头识别、目标检测和密集预测。我们将它们的表现与监督基线进行了比较,并表明在大多数任务中,最好的自我监督模型优于监督,证实了最近观察到的文献趋势。我们发现ImageNet Top-1的精度与多镜头识别的转移高度相关,但对于少镜头、目标检测和密集预测的精度越来越低。没有一种单一的自我监督方法在总体上占主导地位,这表明普遍的预训练仍然没有得到解决。我们对特征的分析表明,顶级自监督学习者不能保留颜色信息和监督替代方案,但倾向于诱导更好的分类器校准,和更少的注意过拟合。
2022
Self-supervised Learning in Remote Sensing: A Review
摘要: 在深度学习研究中,自我监督学习(SSL)受到了广泛的关注,并引起了计算机视觉和遥感社区的兴趣。虽然计算机视觉取得了巨大成功,但SSL在地球观测领域的大部分潜力仍被锁定。在本文中,我们介绍并回顾了遥感领域SSL的概念和最新发展。此外,我们在流行的遥感数据集上提供了现代SSL算法的初步基准,验证了SSL在遥感中的潜力,并提供了对数据扩充的扩展研究。最后,我们确定了地球观测用SSL(SSL4EO)的未来研究方向,为这两个领域的富有成效的相互作用铺平了道路。
论文的贡献:
- 对于遥感社区,我们提供了一个关于自我监督视觉表示学习的全面介绍和文献综述。
- 我们总结了一种自我监督方法的分类,涵盖了来自计算机视觉和遥感领域的现有工作。
- 我们利用ImageNet数据集[2]提供已建立的SSL方法的性能基准的量化,并将分析扩展到三个多光谱卫星图像数据集: BigEarthNet [13]、SEN12MS [14]和So2Sat-LCZ42 [15]。
- 我们讨论了自然图像和遥感数据之间的联系,为遥感和地球观测的自监督学习的未来工作提供了见解。
相关开源库
https://github.com/alibaba/EasyCV
https://github.com/vturrisi/solo-learn
https://github.com/lightly-ai/lightly
https://github.com/open-mmlab/mmselfsup/blob/main/README_zh-CN.md


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











