







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本课中,您将学习如何使用 Scikit-learn 和您之前导入的尼日利亚音乐数据集创建集群。我们将介绍用于聚类的 K-Means 的基础知识。请记住,正如您在上一课中所学到的,有很多方法可以使用集群,并且您使用的方法取决于您的数据。我们将尝试 K-Means,因为它是最常见的聚类技术。让我们开始吧!
您将了解的术语:
- 剪影得分
- 弯头法
- 惯性
- 方差
介绍
K-Means 聚类是一种源自信号处理领域的方法。它用于使用一系列观察将数据组划分和划分为“k”个集群。每个观察都将最接近其最近“平均值”或集群中心点的给定数据点分组。
可以将集群可视化为Voronoi 图,其中包括一个点(或“种子”)及其对应的区域。

Jen Looper的信息图
K-Means 聚类过程分三步执行:
- 该算法通过从数据集中采样来选择 k 个中心点。在此之后,它循环:
- 它将每个样本分配给最近的质心。
- 它通过取分配给先前质心的所有样本的平均值来创建新质心。
- 然后,它计算新旧质心之间的差异并重复,直到质心稳定。
使用 K-Means 的一个缺点是您需要建立“k”,即质心的数量。幸运的是,“肘部方法”有助于估计“k”的良好起始值。你会在一分钟内尝试。
先决条件
您将在本课的notebook.ipynb文件中工作,该文件包含您在上一课中所做的数据导入和初步清理。
练习 - 准备
首先查看歌曲数据。
-
创建一个箱线图,
boxplot()为每一列调用:plt.figure(figsize=(20,20), dpi=200) plt.subplot(4,3,1) sns.boxplot(x = 'popularity', data = df) plt.subplot(4,3,2) sns.boxplot(x = 'acousticness', data = df) plt.subplot(4,3,3) sns.boxplot(x = 'energy', data = df) plt.subplot(4,3,4) sns.boxplot(x = 'instrumentalness', data = df) plt.subplot(4,3,5) sns.boxplot(x = 'liveness', data = df) plt.subplot(4,3,6) sns.boxplot(x = 'loudness', data = df) plt.subplot(4,3,7) sns.boxplot(x = 'speechiness', data = df) plt.subplot(4,3,8) sns.boxplot(x = 'tempo', data = df) plt.subplot(4,3,9) sns.boxplot(x = 'time_signature', data = df) plt.subplot(4,3,10) sns.boxplot(x = 'danceability', data = df) plt.subplot(4,3,11) sns.boxplot(x = 'length', data = df) plt.subplot(4,3,12) sns.boxplot(x = 'release_date', data = df)这个数据有点嘈杂:通过将每一列观察为箱线图,您可以看到异常值。
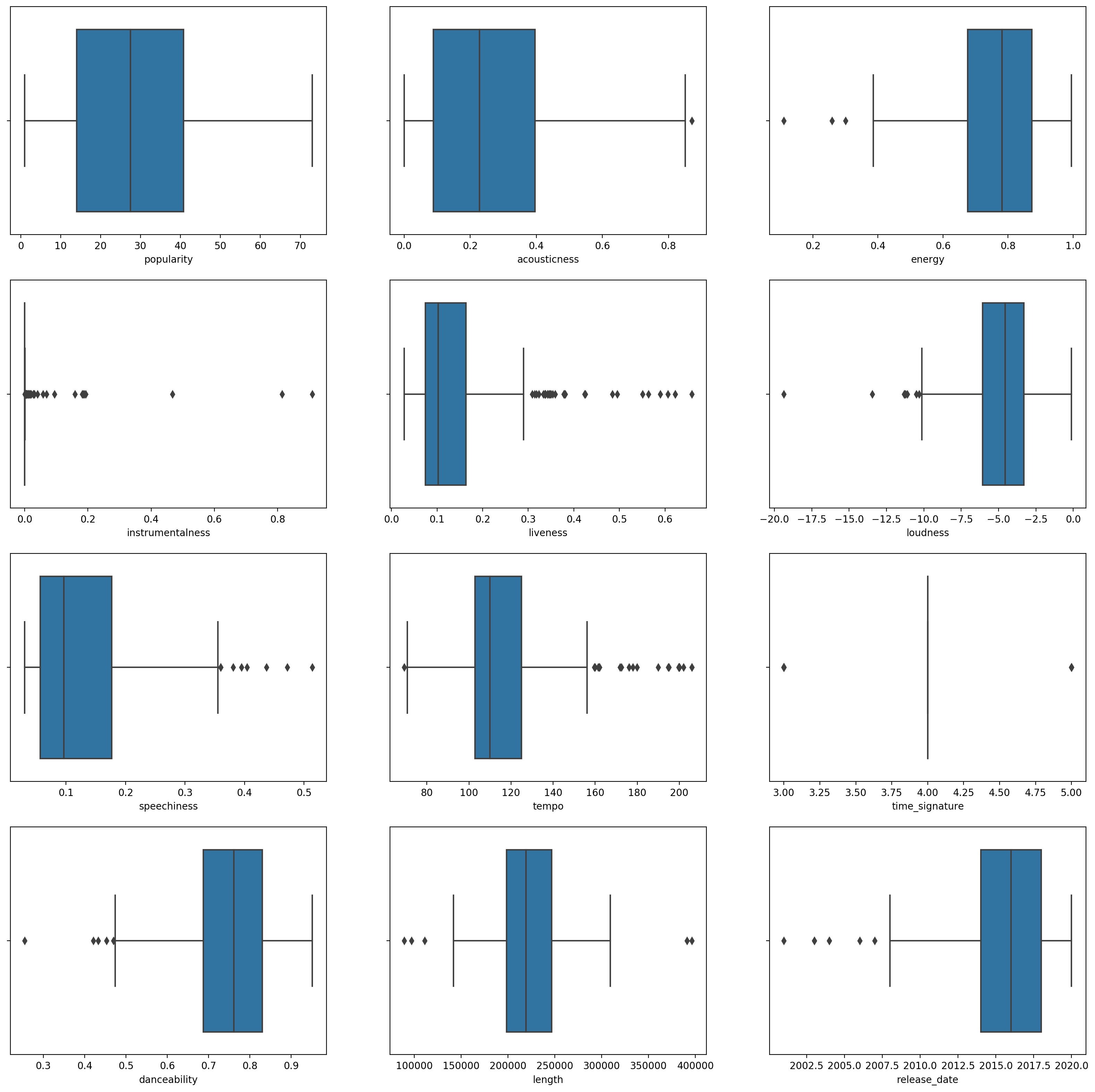
您可以遍历数据集并删除这些异常值,但这会使数据变得非常少。
-
现在,选择将用于聚类练习的列。选择具有相似范围的列并将
artist_top_genre列编码为数字数据:from sklearn.preprocessing import LabelEncoder le = LabelEncoder() X = df.loc[:, ('artist_top_genre','popularity','danceability','acousticness','loudness','energy')] y = df['artist_top_genre'] X['artist_top_genre'] = le.fit_transform(X['artist_top_genre']) y = le.transform(y) -
现在您需要选择要定位的集群数量。你知道我们从数据集中提取了 3 种歌曲类型,所以让我们尝试 3 种:
from sklearn.cluster import KMeans nclusters = 3 seed = 0 km = KMeans(n_clusters=nclusters, random_state=seed) km.fit(X) # Predict the cluster for each data point y_cluster_kmeans = km.predict(X) y_cluster_kmeans
您会看到打印出的数组,其中包含数据帧每一行的预测聚类(0、1 或 2)。
-
使用此数组计算“剪影分数”:
from sklearn import metrics score = metrics.silhouette_score(X, y_cluster_kmeans) score
剪影得分
寻找更接近 1 的轮廓分数。该分数从 -1 到 1 不等,如果分数为 1,则表示该集群密集且与其他集群分离良好。接近 0 的值表示重叠集群,其样本非常接近相邻集群的决策边界。来源。
我们的分数是.53,所以在中间。这表明我们的数据不是特别适合这种类型的聚类,但让我们继续。
练习 - 建立模型
-
导入
KMeans并启动集群过程。from sklearn.cluster import KMeans wcss = [] for i in range(1, 11): kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42) kmeans.fit(X) wcss.append(kmeans.inertia_)这里有几个部分需要解释。
🎓range:这些是聚类过程的迭代
🎓random_state:“确定质心初始化的随机数生成。” 资源
🎓WCSS:“簇内平方和”测量簇内所有点到簇质心的平方平均距离。来源。
🎓惯性:K-Means 算法试图选择质心以最小化“惯性”,“一种衡量内部连贯性集群的方法”。来源。该值在每次迭代时附加到 wcss 变量。
🎓k-means++:在Scikit-learn中,您可以使用 'k-means++' 优化,它“将质心初始化为(通常)彼此远离,从而可能比随机初始化产生更好的结果。
弯头法
之前,您推测,因为您定位了 3 个歌曲流派,您应该选择 3 个集群。但真的是这样吗?
-
使用“肘部方法”来确定。
plt.figure(figsize=(10,5)) sns.lineplot(range(1, 11), wcss,marker='o',color='red') plt.title('Elbow') plt.xlabel('Number of clusters') plt.ylabel('WCSS') plt.show()使用
wcss您在上一步中构建的变量创建一个图表,显示肘部的“弯曲”位置,这表明最佳聚类数。也许是3!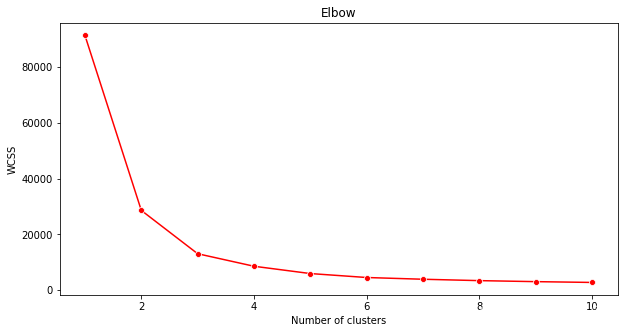
练习 - 显示集群
-
再次尝试该过程,这次设置三个集群,并将集群显示为散点图:
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3) kmeans.fit(X) labels = kmeans.predict(X) plt.scatter(df['popularity'],df['danceability'],c = labels) plt.xlabel('popularity') plt.ylabel('danceability') plt.show() -
检查模型的准确性:
labels = kmeans.labels_ correct_labels = sum(y == labels) print("Result: %d out of %d samples were correctly labeled." % (correct_labels, y.size)) print('Accuracy score: {0:0.2f}'. format(correct_labels/float(y.size)))这个模型的准确性不是很好,集群的形状给你一个提示。
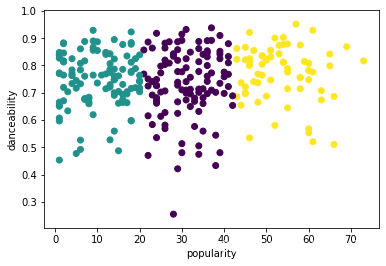
-
该数据太不平衡,相关性太小,并且列值之间的差异太大而无法很好地聚类。事实上,形成的集群可能受到我们上面定义的三个流派类别的严重影响或倾斜。那是一个学习的过程!
在 Scikit-learn 的文档中,您可以看到像这样的模型,集群没有很好地划分,存在“方差”问题:
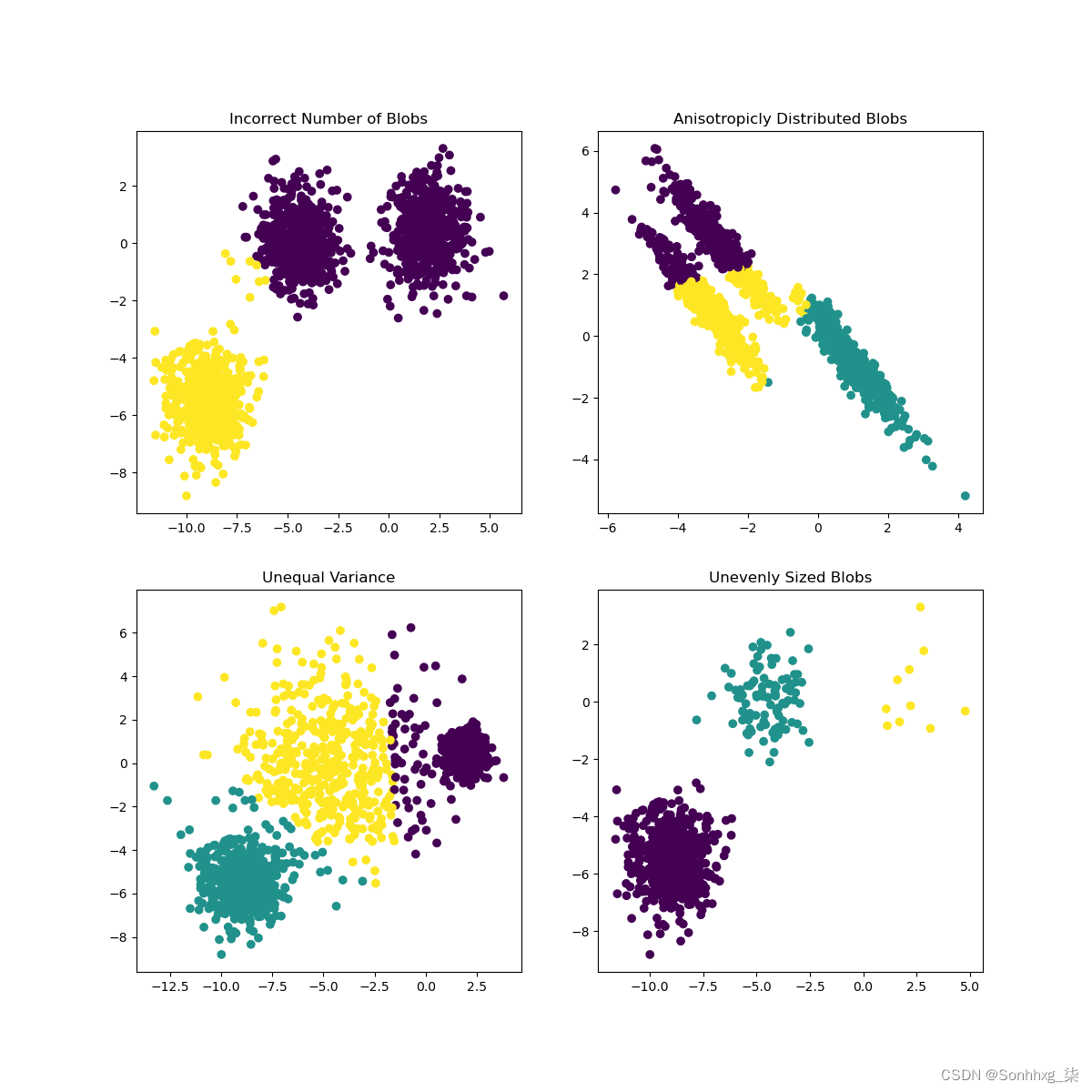
来自 Scikit-learn 的信息图
方差
方差定义为“与平均值的平方差的平均值”源。在这个聚类问题的背景下,它指的是我们的数据集的数量往往与平均值相差太大的数据。
✅这是思考可以纠正此问题的所有方法的好时机。稍微调整一下数据?使用不同的列?使用不同的算法?提示:尝试缩放数据以对其进行标准化并测试其他列。
试试这个“方差计算器”来更多地理解这个概念。
















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











