







讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的(01)ORB-SLAM2源码无死角解析链接如下(本文内容来自计算机视觉life ORB-SLAM2 课程课件):
(01)ORB-SLAM2源码无死角解析-(00)目录_最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/123092196
文末正下方中心提供了本人
联系方式,
点击本人照片即可显示
W
X
→
官方认证
{\color{blue}{文末正下方中心}提供了本人 \color{red} 联系方式,\color{blue}点击本人照片即可显示WX→官方认证}
文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证
一、前言
在上一篇博客中,简单的介绍了以下特征带点,以及 ORBextractor::ORBextractor() 构造函数。我们已经知道Frame::Frame()构建函数中会调用到 ORBextractor::operator() 函数,该张博客我们就来看看其函数的具体实现,其代码位于 src/ORBextractor.cc文件中。
二、代码流程
1、根据输入的灰度图像,构建特征金字塔: ComputePyramid(image)
2、使用四叉树的方式计算每层图像的关键点并且进行分配: ComputeKeyPointsOctTree(allKeypoints);
3、经过高斯模糊之后,生成关键点对应的描述子,并且计算出关键点的方向: computeDescriptors(workingMat,keypoints,esc,pattern);
代码的流程是十分简单的,其上的三个部分都是都是十分重要的,下面是 operator() 函数的代码注释。
三、源码注释
/**
* @brief 用仿函数(重载括号运算符)方法来计算图像特征点
*
* @param[in] _image 输入原始图的图像
* @param[in] _mask 掩膜mask
* @param[in & out] _keypoints 存储特征点关键点的向量
* @param[in & out] _descriptors 存储特征点描述子的矩阵
*/
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
// Step 1 检查图像有效性。如果图像为空,那么就直接返回
if(_image.empty())
return;
//获取图像的大小
Mat image = _image.getMat();
// UNDONE:
cv::imshow("src", image);
system("mkdir -p result_images");
cv::imwrite("result_images/src.jpg", image);
//判断图像的格式是否正确,要求是单通道灰度值
assert(image.type() == CV_8UC1 );
// Pre-compute the scale pyramid
// Step 2 构建图像金字塔
ComputePyramid(image);
// Step 3 计算图像的特征点,并且将特征点进行均匀化。均匀的特征点可以提高位姿计算精度
// 存储所有的特征点,注意此处为二维的vector,第一维存储的是金字塔的层数,第二维存储的是那一层金字塔图像里提取的所有特征点
vector < vector<KeyPoint> > allKeypoints;
//使用四叉树的方式计算每层图像的特征点并进行分配
ComputeKeyPointsOctTree(allKeypoints);
//使用传统的方法提取并平均分配图像的特征点,作者并未使用
//ComputeKeyPointsOld(allKeypoints);
// Step 4 拷贝图像描述子到新的矩阵descriptors
Mat descriptors;
//统计整个图像金字塔中的特征点
int nkeypoints = 0;
//开始遍历每层图像金字塔,并且累加每层的特征点个数
for (int level = 0; level < nlevels; ++level)
nkeypoints += (int)allKeypoints[level].size();
//如果本图像金字塔中没有任何的特征点
if( nkeypoints == 0 )
//通过调用cv::mat类的.realse方法,强制清空矩阵的引用计数,这样就可以强制释放矩阵的数据了
//参考[https://blog.csdn.net/giantchen547792075/article/details/9107877]
_descriptors.release();
else
{
//如果图像金字塔中有特征点,那么就创建这个存储描述子的矩阵,注意这个矩阵是存储整个图像金字塔中特征点的描述子的
_descriptors.create(nkeypoints, //矩阵的行数,对应为特征点的总个数
32, //矩阵的列数,对应为使用32*8=256位描述子
CV_8U); //矩阵元素的格式
//获取这个描述子的矩阵信息
// ?为什么不是直接在参数_descriptors上对矩阵内容进行修改,而是重新新建了一个变量,复制矩阵后,在这个新建变量的基础上进行修改?
descriptors = _descriptors.getMat();
}
//清空用作返回特征点提取结果的vector容器
_keypoints.clear();
//并预分配正确大小的空间
_keypoints.reserve(nkeypoints);
//因为遍历是一层一层进行的,但是描述子那个矩阵是存储整个图像金字塔中特征点的描述子,所以在这里设置了Offset变量来保存“寻址”时的偏移量,
//辅助进行在总描述子mat中的定位
int offset = 0;
//开始遍历每一层图像
for (int level = 0; level < nlevels; ++level)
{
//获取在allKeypoints中当前层特征点容器的句柄
vector<KeyPoint>& keypoints = allKeypoints[level];
//本层的特征点数
int nkeypointsLevel = (int)keypoints.size();
//如果特征点数目为0,跳出本次循环,继续下一层金字塔
if(nkeypointsLevel==0)
continue;
// preprocess the resized image
// Step 5 对图像进行高斯模糊
// 深拷贝当前金字塔所在层级的图像
Mat workingMat = mvImagePyramid[level].clone();
// 注意:提取特征点的时候,使用的是清晰的原图像;这里计算描述子的时候,为了避免图像噪声的影响,使用了高斯模糊
GaussianBlur(workingMat, //源图像
workingMat, //输出图像
Size(7, 7), //高斯滤波器kernel大小,必须为正的奇数
2, //高斯滤波在x方向的标准差
2, //高斯滤波在y方向的标准差
BORDER_REFLECT_101);//边缘拓展点插值类型
// Compute the descriptors 计算描述子
// desc存储当前图层的描述子
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
// Step 6 计算高斯模糊后图像的描述子
computeDescriptors(workingMat, //高斯模糊之后的图层图像
keypoints, //当前图层中的特征点集合
desc, //存储计算之后的描述子
pattern); //随机采样模板
// 更新偏移量的值
offset += nkeypointsLevel;
// Scale keypoint coordinates
// Step 6 对非第0层图像中的特征点的坐标恢复到第0层图像(原图像)的坐标系下
// ? 得到所有层特征点在第0层里的坐标放到_keypoints里面
// 对于第0层的图像特征点,他们的坐标就不需要再进行恢复了
if (level != 0)
{
// 获取当前图层上的缩放系数
float scale = mvScaleFactor[level];
// 遍历本层所有的特征点
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
// 特征点本身直接乘缩放倍数就可以了
keypoint->pt *= scale;
}
// And add the keypoints to the output
// 将keypoints中内容插入到_keypoints 的末尾
// keypoint其实是对allkeypoints中每层图像中特征点的引用,这样allkeypoints中的所有特征点在这里被转存到输出的_keypoints
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
}
}
四、构建图像金字塔
上面有三个比较重要的地方,我们这里先来介绍其中的 ComputePyramid(image),也就是金字塔的具体构建过程,前面的博客,在 ORBextractor 的构造函数中,知道其根据配置文件,获得了很多图像金字塔需要的相关参数。那么获得参数之后,是如何进行图像金字塔的构建的呢,其核心位于 ORBextractor::ComputePyramid()函数之中,下面我们先对其进行梳理:
//循环创建金字塔图层
for (int level = 0; level < nlevels; ++level)
//根据该成的缩放因子计算本层图像的像素尺寸大小
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
//保存该金字塔图层的图像数据
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
//对边界进行扩充,需要取消代码 mvImagePyramid[level] = temp; 的注释
copyMakeBorder(image,temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,BORDER_REFLECT_101);
//赋值扩充之后的图像,需要取消注释生效
//mvImagePyramid[level] = temp;
本人这里保存的金字塔的图像,展示如下:
ComputePyramid()的代码注释如下
void ORBextractor::ComputePyramid(cv::Mat image)
{
//开始遍历所有的图层
for (int level = 0; level < nlevels; ++level)
{
//获取本层图像的缩放系数
float scale = mvInvScaleFactor[level];
//计算本层图像的像素尺寸大小
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
//全尺寸图像。包括无效图像区域的大小。将图像进行“补边”,EDGE_THRESHOLD区域外的图像不进行FAST角点检测
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
// 定义了两个变量:temp是扩展了边界的图像,masktemp并未使用
Mat temp(wholeSize, image.type()), masktemp;
// mvImagePyramid 刚开始时是个空的vector<Mat>
// 把图像金字塔该图层的图像指针mvImagePyramid指向temp的中间部分(这里为浅拷贝,内存相同)
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
#ifdef _DEBUG
// UNDONE:
ostringstream buffer;
buffer << "EDGE_mvImagePyramid_" << level << ".jpg";
string imageFile = buffer.str();
string imagePath = "result_images/" + imageFile;
//cv::imshow(imageFile, mvImagePyramid[level]);
system("mkdir -p result_images");
cv::imwrite(imagePath, mvImagePyramid[level]);
//cv::waitKey();
#endif
// Compute the resized image
//计算第0层以上resize后的图像
if( level != 0 )
{
//将上一层金字塔图像根据设定sz缩放到当前层级
resize(mvImagePyramid[level-1], //输入图像
mvImagePyramid[level], //输出图像
sz, //输出图像的尺寸
0, //水平方向上的缩放系数,留0表示自动计算
0, //垂直方向上的缩放系数,留0表示自动计算
cv::INTER_LINEAR); //图像缩放的差值算法类型,这里的是线性插值算法
// //! 原代码mvImagePyramid 并未扩充,上面resize应该改为如下
// resize(image, //输入图像
// mvImagePyramid[level], //输出图像
// sz, //输出图像的尺寸
// 0, //水平方向上的缩放系数,留0表示自动计算
// 0, //垂直方向上的缩放系数,留0表示自动计算
// cv::INTER_LINEAR); //图像缩放的差值算法类型,这里的是线性插值算法
//把源图像拷贝到目的图像的中央,四面填充指定的像素。图片如果已经拷贝到中间,只填充边界
//这样做是为了能够正确提取边界的FAST角点
//EDGE_THRESHOLD指的这个边界的宽度,由于这个边界之外的像素不是原图像素而是算法生成出来的,所以不能够在EDGE_THRESHOLD之外提取特征点
copyMakeBorder(mvImagePyramid[level], //源图像
temp, //目标图像(此时其实就已经有大了一圈的尺寸了)
EDGE_THRESHOLD, EDGE_THRESHOLD, //top & bottom 需要扩展的border大小
EDGE_THRESHOLD, EDGE_THRESHOLD, //left & right 需要扩展的border大小
BORDER_REFLECT_101+BORDER_ISOLATED); //扩充方式,opencv给出的解释:
/*Various border types, image boundaries are denoted with '|'
* BORDER_REPLICATE: aaaaaa|abcdefgh|hhhhhhh
* BORDER_REFLECT: fedcba|abcdefgh|hgfedcb
* BORDER_REFLECT_101: gfedcb|abcdefgh|gfedcba
* BORDER_WRAP: cdefgh|abcdefgh|abcdefg
* BORDER_CONSTANT: iiiiii|abcdefgh|iiiiiii with some specified 'i'
*/
//BORDER_ISOLATED 表示对整个图像进行操作
// https://docs.opencv.org/3.4.4/d2/de8/group__core__array.html#ga2ac1049c2c3dd25c2b41bffe17658a36
}
else
{
//对于第0层未缩放图像,直接将图像深拷贝到temp的中间,并且对其周围进行边界扩展。此时temp就是对原图扩展后的图像
copyMakeBorder(image, //这里是原图像
temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
// //! 原代码mvImagePyramid 并未扩充,应该添加下面一行代码
//mvImagePyramid[level] = temp;
}
}
本人对 mvImagePyramid 图像金字塔进行了保存(由于屏幕大小,本人只保存了6层,实际共8成),展示如下:
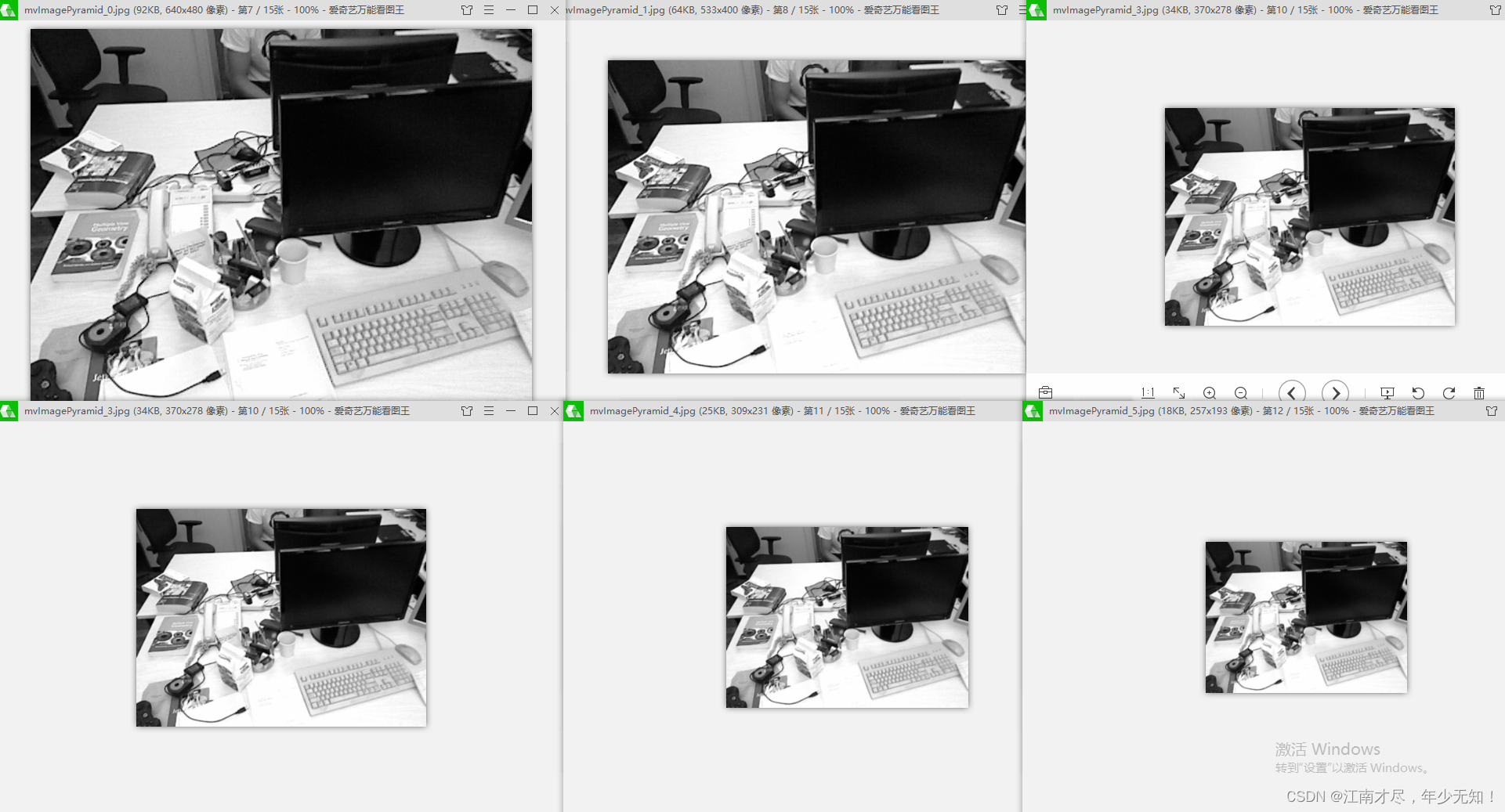
在上面的代码中,我们可以看到一个参数 EDGE_THRESHOLD = 19, 这里是为了对图片进行填充,后续进行特征提取时,尽量利用到图像的每个像素,本人取消 ORBextractor::ComputePyramid()函数中代码
mvImagePyramid[level] = temp;
的注释之后,这个参数就起到了作用,然后保存图像效果如下:

可以很明显的看到,该图像的周边填充了16行列像素,其填充结果是对称于红线的。
四、结语
这篇博客主要讲解了图像金字塔的具体构建过程,并且知道图像金字塔存储于变量 mvImagePyramid 之后,后续我们会基于金字塔进行特征点提取。也就是接下来需要讲解的核心内容了
本文内容来自计算机视觉life ORB-SLAM2 课程课件















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









