






[ICCV 2021] Point Transformer
实验代码: https://github.com/Pointcept/Pointcept
论文地址: https://arxiv.org/pdf/2012.09164.pdf
文章目录
Abstract
将自注意力网络迁移到3D点云处理。
一、Introduction
将自注意力应用于3D点云是非常自然的,因为点云本质上是嵌入在3D空间中的集合。研究了自注意力操作符的形式,将自注意力机制应用于每个点周围的局部区域,以及在网络中对相对位置进行编码。得到完全居于自注意力和逐点操作的网络。
二、Related Work
Transformer and self-attention.
局部注意力+矢量注意力(Vector Self-attention)+位置编码
三、Self-attention Networks
1、背景:两种注意力机制的对比

2、Point transformer层:
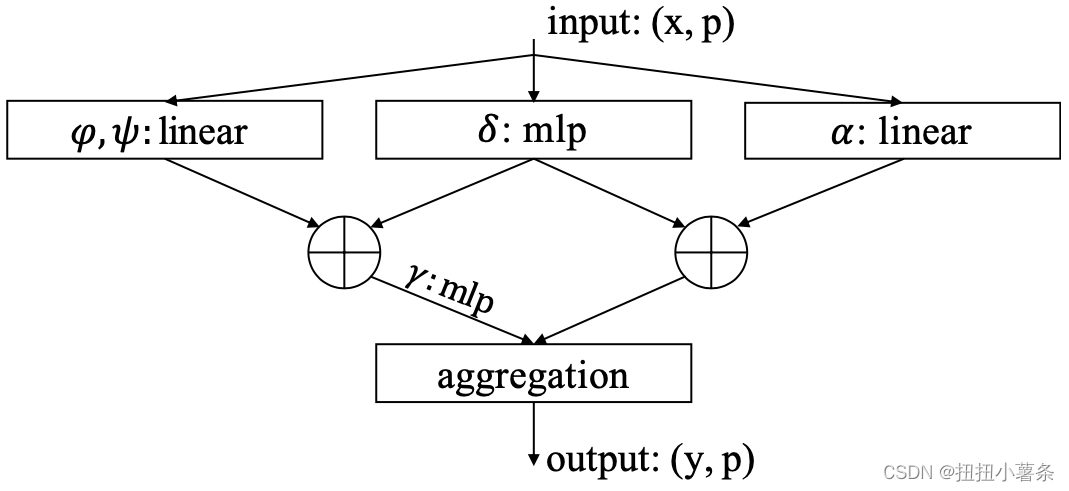
δ \delta δ是位置编码,出现在两个位置
3、位置编码:
定义:
δ
=
θ
(
p
i
−
p
j
)
\delta = \theta(p_{i}-p_{j})
δ=θ(pi−pj)
δ
\delta
δ由两个线性层和一个ReLU组成的MLP构成。
位置编码在两个分支都很重要
4、网络结构:
Backbone structure. Transition down. Transition up. Output head.
四、Experiments
S3DIS + ModelNet40 + ShapeNet

Ablation Study:
Number of neighbors. Softmax regularization. Position encoding. Attention type.
邻居16个最好,Position Encoding采用相对位置最好,Vector Attention最好,Softmax是有效的。
五、Conclusion
自注意力操作符本质上是一个集合操作符,除了在这种概念上的兼容性之外,Transformer在点云处理方面表现出了非凡的效果。下一步开发新的操作符和网络设计,并将Transformer应用于其他任务。















 7982
7982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









